













4萬億晶體管5nm制程,全球最快AI芯片碾壓H100!單機可訓24萬億參數LLM,Llama 70B一天搞定
全球最快、最強的AI芯片面世,讓整個行業瞬間驚掉了下巴!
就在剛剛,AI芯片初創公司Cerebras重磅發布了「第三代晶圓級引擎」(WSE-3)。
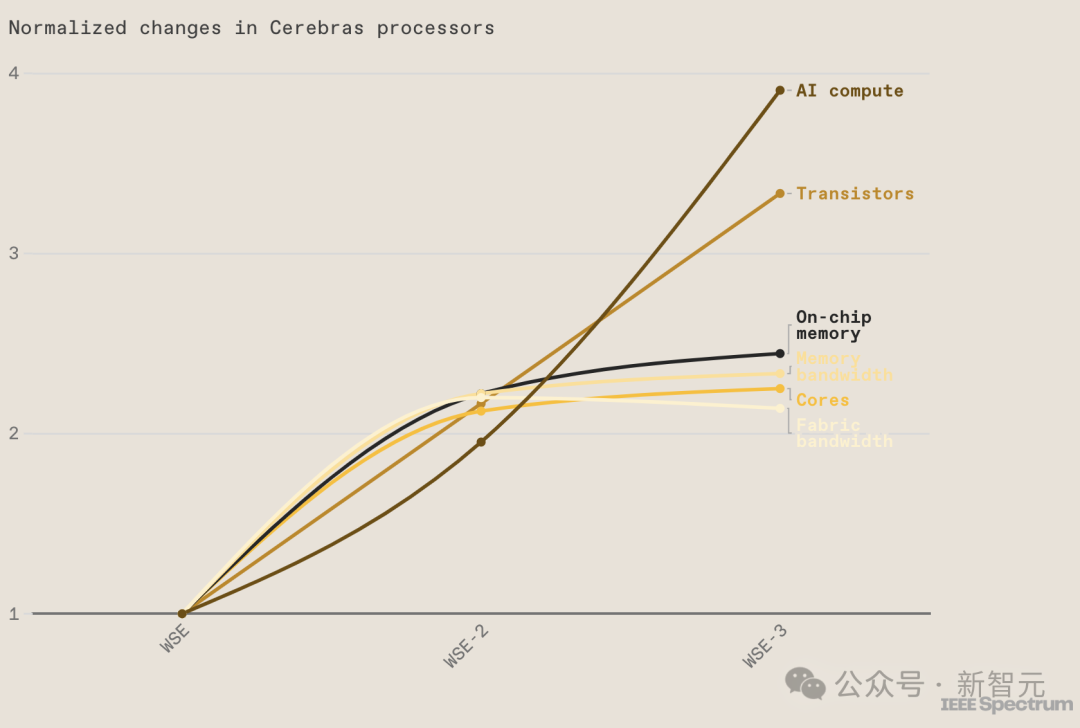
性能上,WSE-3是上一代WSE-2的兩倍,且功耗依舊保持不變。

90萬個AI核心,44GB的片上SRAM存儲,讓WSE-3的峰值性能達到了125 FP16 PetaFLOPS。

這相當于52塊英偉達H100 GPU!

不僅如此,相比于800億個晶體管,芯片面積為814平方毫米的英偉達H100。
采用臺積電5nm制程的WSE-3,不僅搭載了40000億個晶體管(50倍),芯片面積更是高達46225平方毫米(57倍)。

專為AI打造的計算能力
此前,在傳統的GPU集群上,研究團隊不僅需要科學地分配模型,還必須在過程中處理各種復雜問題,比如處理器單元的內存容量、互聯帶寬、同步機制等等,同時還要不斷調整超參數并進行優化實驗。

更令人頭疼的是,最終的實現很容易因為小小的變動而受到影響,這樣就會進一步延長解決問題所需的總時間。
相比之下,WSE-3的每一個核心都可以獨立編程,并且專為神經網絡訓練和深度學習推理中,所需的基于張量的稀疏線性代數運算,進行了優化。
而團隊也可以在WSE-3的加持下,以前所未有的速度和規模訓練和運行AI模型,并且不需要任何復雜分布式編程技巧。
單芯片實現集群級性能
其中,WSE-3配備的44GB片上SRAM內存均勻分布在芯片表面,使得每個核心都能在單個時鐘周期內以極高的帶寬(21 PB/s)訪問到快速內存——是當今地表最強GPU英偉達H100的7000倍。
超高帶寬,極低延遲
而WSE-3的片上互連技術,更是實現了核心間驚人的214 Pb/s互連帶寬,是H100系統的3715倍。
單個CS-3可訓24萬億參數,大GPT-4十倍
由WSE-3組成的CS-3超算,可訓練比GPT-4和Gemini大10倍的下一代前沿大模型。
再次打破了「摩爾定律」!2019年Cerebras首次推出CS-1,便打破了這一長達50年的行業法則。

官方博客中的一句話,簡直刷新世界觀:
在CS-3上訓練一個萬億參數模型,就像在GPU上訓練一個10億參數模型一樣簡單!
顯然,Cerebras的CS-3強勢出擊,就是為了加速最新的大模型訓練。
它配備了高達1.2PB的巨大存儲系統,單個系統即可訓出24萬億參數的模型——為比GPT-4和Gemini大十倍的模型鋪平道路。
簡之,無需分區或重構,大大簡化訓練工作流提高開發效率。

在Llama 2、Falcon 40B、MPT-30B以及多模態模型的真實測試中,CS-3每秒輸出的token是上一代的2倍。
而且,CS-3在不增加功耗/成本的情況下,將性能提高了一倍。
除此之外,為了跟上不斷升級的計算和內存需求,Cerebras提高了集群的可擴展性。
上一代CS-2支持多達192個系統的集群,而CS-3可配置高達2048個系統集群,性能飆升10倍。
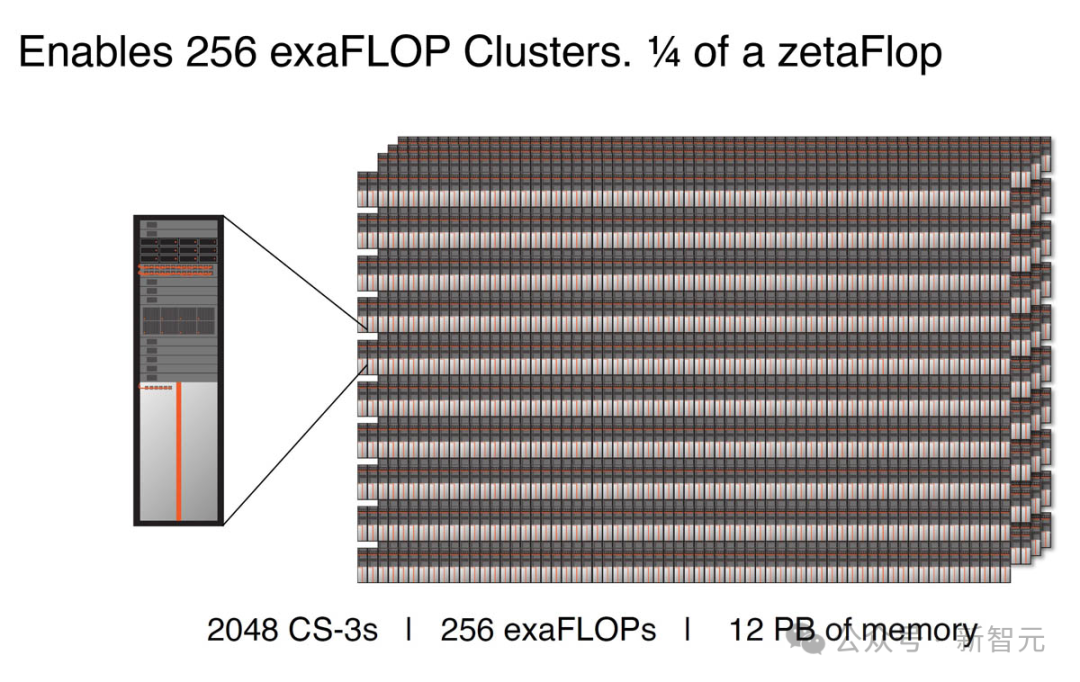
具體來說,由2048個CS-3組成的集群,可以提供256 exafloop的AI計算。
能夠在24小時內,從頭訓練一個Llama 70B的模型。
相比之下,Llama2 70B可是用了大約一個月的時間,在Meta的GPU集群上完成的訓練。

與GPU系統的另一個不同是,Cerebras晶圓規模集群可分離計算和內存組件,讓開發者能輕松擴展MemoryX單元中的內存容量。
得益于Cerebras獨特的Weight Streaming架構,整個集群看起來與單個芯片無異。
換言之,一名ML工程師可以在一臺系統上開發和調試數萬億個參數模型,這在GPU領域是聞所未聞的。

具體來說,CS-3除了為企業提供24TB和36TB這兩個版本外,還有面向超算的120TB和1200TB內存版本。(之前的CS-2集群只有1.5TB和12TB可選)
單個CS-3可與單個1200 TB內存單元配對使用,這意味著單個CS-3機架可以存儲模型參數,比10000個節點的GPU集群多得多。

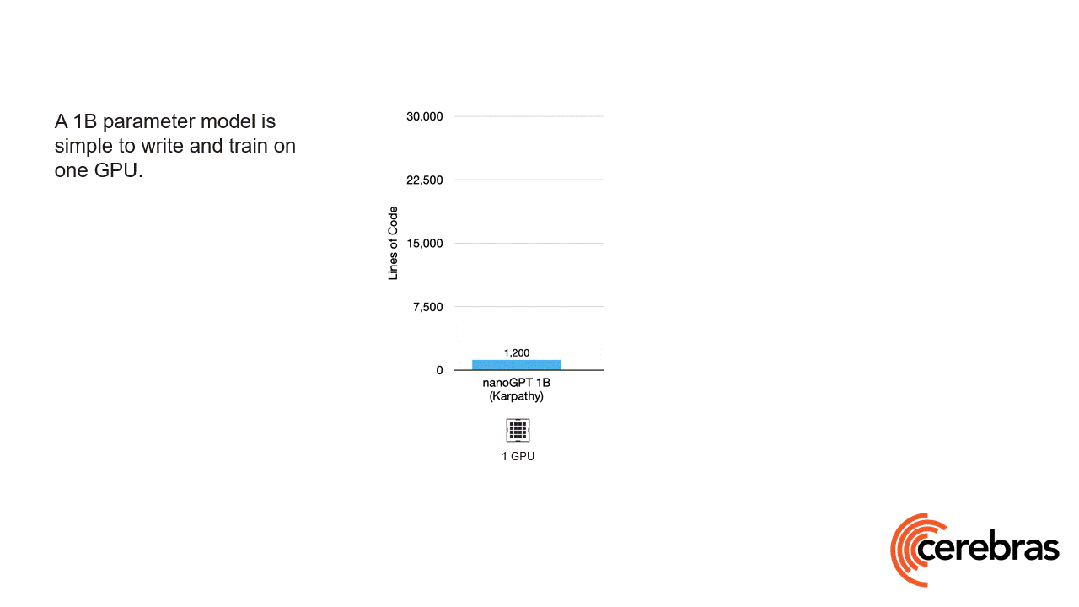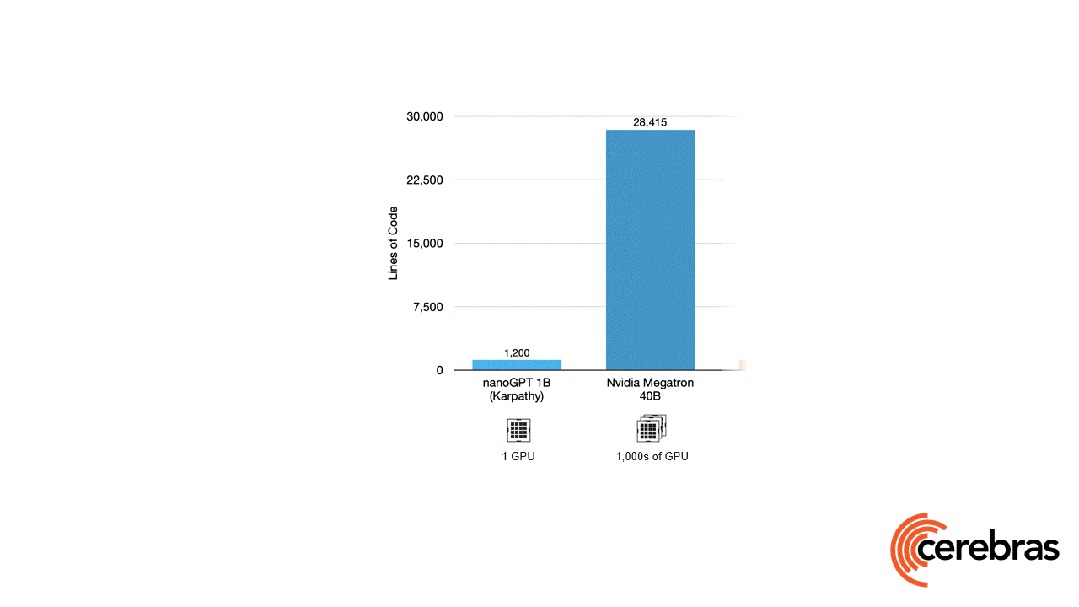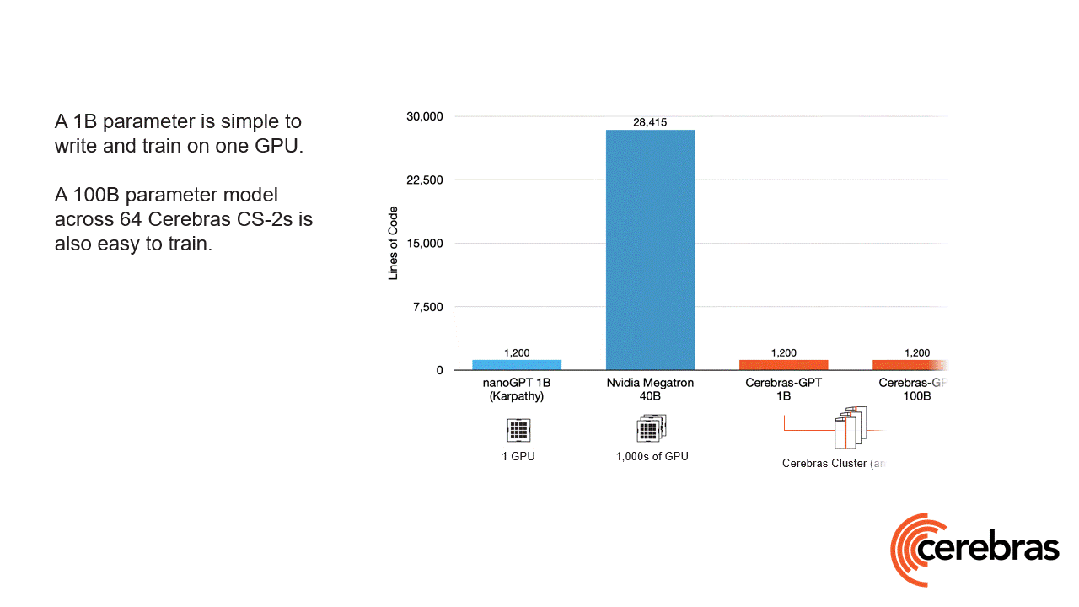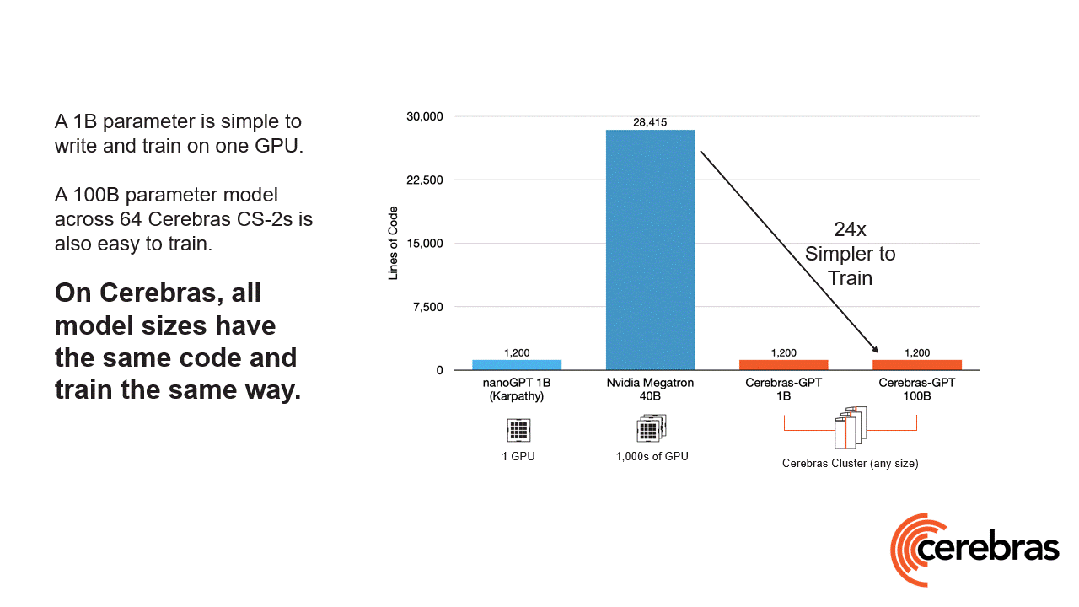
除此之外,與使用GPU相比,在Cerebras平臺上開發所需的代碼量還減少了高達97%。
更令人震驚的數字是——訓練一個GPT-3規模的模型,僅需565行代碼!
Playground AI創始人稱,GPT-3正穩步成為AI領域的新「Hello World」。在Cerebras上,一個標準的GPT-3規模的模型,只需565行代碼即可實現,創下行業新紀錄。

首個世界最強芯片打造的超算來了
由G42和Cerebras聯手打造的超級計算機——Condor Galaxy,是目前在云端構建AI模型最簡單、最快速的解決方案。

它具備超過16 ExaFLOPs的AI計算能力,能夠在幾小時之內完成對最復雜模型的訓練,這一過程在傳統系統中可能需要數天。
其MemoryX系統擁有TB級別的內存容量,能夠輕松處理超過1000億參數的大模型,大大簡化了大規模訓練的復雜度。
與現有的基于GPU的集群系統不同,Condor Galaxy在處理GPT這類大型語言模型,包括GPT的不同變體、Falcon和Llama時,展現出了幾乎完美的擴展能力。
這意味著,隨著更多的CS-3設備投入使用,模型訓練的時間將按照幾乎完美的比例縮短。
而且,配置一個生成式AI模型只需幾分鐘,不再是數月,這一切只需一人便可輕松完成。

在簡化大規模AI計算方面,傳統系統因為需要在多個節點之間同步大量處理器而遇到了難題。
而Cerebras的全片級計算系統(WSC)則輕松跨越這一障礙——它通過無縫整合各個組件,實現了大規模并行計算,并提供了簡潔的數據并行編程界面。

此前,這兩家公司已經聯手打造了世界上最大的兩臺AI超級計算機:Condor Galaxy 1和Condor Galaxy 2,綜合性能達到8exaFLOPs。
G42集團的首席技術官Kiril Evtimov表示:「我們正在建設的下一代AI超級計算機Condor Galaxy 3,具有8exaFLOPs的性能,很快將使我們的AI計算總產能達到16exaFLOPs。」

如今,我們即將迎來新一波的創新浪潮,而全球AI革命的腳步,也再一次被加快了。

























