小紅書論文刷新 SOTA:人體動作預測再升級,能精準到指尖

想象一下,你在玩一款 VR 游戲,準備伸手拿起一個虛擬杯子喝水。
在傳統的交互系統中,這通常需要你按下控制器上的特定按鈕。但如果游戲集成了 EAI 框架,這一過程將變得無比自然。當你的手緩緩接近虛擬杯子時,系統會敏銳地預測出你的未來手部動作,無需任何操作,游戲中的“你”便會流暢地模擬出精細的手部抓取動作,游戲引擎也會提前對你的動作行為做出響應。
這種無縫的交互體驗,將會提升游戲中人-人、人- NPC 交互的實時性和準確性,極大地提升游戲沉浸感。
什么是 EAI 框架?全稱是編碼-對齊-交互(Encoding-Alignment-Interaction)框架,由小紅書創作發布團隊在 AAAI 2024 上創新提出。該框架用于預測未來全身人體動作,尤其擅長手部細微動作的預測。
EAI 框架的應用遠不止于此。它能夠理解并預測用戶的動作意圖,無論是在藝術表演中同步舞者的動作,創造出與音樂和視覺效果和諧融合的動態藝術,還是在智能家居中自動響應你的需求,或是在醫療康復領域指導患者正確執行運動,避免潛在傷害。它甚至能夠預測潛在的安全威脅,如在擁擠場所避免踩踏事件。
實驗結果表明:EAI 框架在多個大規模基準數據集上取得了最先進的預測性能(SOTA)。它有效地處理了身體和手部動作之間的異質性和交互性,實現了全身動作預測的高質量輸出。這一突破性的技術,預示著未來在人機交互、虛擬現實以及更廣泛的智能系統中,將有無限的可能性等待著被探索。
一、背景
人體動作預測(Human Motion Forecasting),即預估未來一段時間內的人類行為,正成為連接人類行為與智能系統的關鍵橋梁。在人機交互(HRI)、虛擬現實(VR)和游戲動畫(GA)等領域,這一任務至關重要。然而,現有研究通常集中在預測人體主要關節的運動,卻忽略了手部精細動作,而這些動作在溝通和交互中至關重要。
在人機交互場景中,機器人需要準確預測人類未來動作以實現有效協作,但現有模型未能充分捕捉手部精細動作,這直接影響了對人類意圖和行為的理解。此外,人體各部分間的協作和交付,如喝水、鼓掌等復雜交互模式,也未被現有預測模型充分捕捉,這限制了預測的準確性和表達性。

為解決上述挑戰,我們首先提出了一種全新范式:全身人體動作預測任務,即同時預測身體和手部所有關節的未來活動。通過這種聯合預測,可以更準確地捕捉人類行為的全貌,從而在人機交互等應用中提供更自然的交互體驗。這種全身運動預測不僅包括身體的主要動作,還細致地考慮了手部的精細運動,以理解人類行為的意圖和情感表達。
進一步地,為實現面向全身人體關節的細粒度動作預測的目標,我們重點提出了編碼-對齊-交互(Encoding-Alignment-Interaction,EAI)框架。EAI 框架主要包括以下兩個核心組成部分:
- 跨上下文對齊(cross-context-alignment,XCA):用于對齊不同人體組件的潛在特征,消除異質性
- 跨上下文交互(cross-context-interaction,XCI):專注于捕捉人體組件間的上下文交互,提高動作預測的準確性
通過在新引入的大型數據集上的廣泛實驗,EAI 框架在 3D 全身人體動作預測方面取得了最先進的性能,證明了其在捕捉人類動作細微差別方面的有效性。這些實驗結果不僅展示了 EAI 框架在預測復雜人類動作方面的優越性,還為未來的人機交互和虛擬現實等領域的應用提供了新的視角和可能性。
二、方法

EAI 算法流程圖
如圖所示,EAI 框架主要涉及以下三個核心步驟:
- Encoding :通過離散余弦變換(DCT) 和動態圖卷積神經網絡(GCNs)提取運動序列的時空相關性,并將其編碼為高維隱藏特征;
- Alignment:通過提出的跨上下文對齊(XCA)來調整不同身體部分的潛在特征,使其更加一致;
- Interaction:利用提出的跨上下文交互(XCI)來捕捉身體各部分之間的語義和物理互動。
這種方法通過聯合預測身體和手部動作,能夠提高預測運動的準確性和表達性,特別是在捕捉不同人體部分動作的細微差別方面具有較強的性能。
2.1 內部上下文編碼(Intra-context Encoding)
內部上下文編碼(Intra-context Encoding)是 EAI 框架中的一個重要模塊,負責從每個身體部分(如左手、右手和主要身體)提取特征。該模塊能夠獨立地處理每個身體部分,以便捕捉每個組件內部的時空相關性。假設下標 , , 分別表示左手、軀干和右手,我們將全身人體姿態劃分為三個部分:左手動作序列 ,軀干動作序列 ,右手動作序列 。具體操作步驟如下:
a. DCT 編碼:在時間域,使用離散余弦變換(Discrete Cosine Transform,DCT)來捕捉動作序列的時序平滑性,將觀察到的動作序列轉換到軌跡空間:
b. GCN 表示學習:在空間域,利用圖卷積網絡(Graph Convolutional Networks,GCNs)將骨骼表示為一個全連接圖,通過鄰接矩陣來捕捉空間關系:

其中, 表示 ReLU 激活函數, 表示鄰接矩陣, 表示輸入特征, 表示 GCN 權重矩陣, 表示輸出特征。上述是以軀干關節進行的上下文編碼。相似地,我們也能夠得到左右手的關節表示 、 ,這些特征隨后將用于跨上下文對齊和交互,以實現更準確的全身動作預測。

2.2 跨上下文對齊(Cross-context Alignment)
跨上下文對齊(Cross-context Alignment,XCA) 目的是對齊不同身體部分(如身體、左手和右手)的潛在特征,以消除它們之間的異質性,從而方便后續的跨上下文特征交互。該模塊通過以下步驟實現特征對齊:
- 特征中立化:引入可學習的因子來中和不同特征分布之間的差異,通過最小化最大均值差異(Maximum Mean Discrepancy,MMD)來調整特征分布,使其更加接近一致:

- 環形中立化:為了進一步實現 part-to-part 的對齊,我們將中立化擴展到環形版本,通過身體到手腕的鏈路來實現身體和手部之間的對齊,確保每個部分的特征對齊都會考慮到其他兩個部分的特征屬性。

- 不一致性約束:接著,我們應用差異約束來減少部分到部分的差異,通過計算特征的平均值和方差,然后應用中立化和差異約束來調整特征,使其分布更加一致。

通過 XCA,EAI 框架能夠有效地處理身體各部分之間的異質性,為后續的 XCI 提供了更加一致和協調的特征表示,從而有助于提高全身動作預測的準確性和表達性。
2.3 跨上下文交互(Cross-context Interaction)
跨上下文交互(Cross-context Interaction,XCI)是 EAI 框架中的另一個核心模塊,它專注于捕捉全身不同部分之間的交互性,包括語義和物理層面的互動。這個模塊通過以下步驟實現交互:
a. 語義交互:通過交叉注意力機制,模型學習不同身體部分之間的語義依賴性。例如,對于吃飯這個動作,手指和頭部關節之間存在強相關性。XCI 通過計算注意力圖來融合這些語義交互信息。

b. 物理交互:作為身體和手部之間的橋梁,手腕提供了直接的鏈式相關性。XCI 采用“分割和融合”策略,首先獨立地復制手腕關節以包含它,然后進行動態特征融合,以更好地模擬身體部分之間的物理連接。

通過最小化分布差異誤差,XCI 將不同身體部分的特征融合在一起,生成表達性特征。這些特征隨后用于預測器,以回歸到預測的序列。通過 XCI,EAI 框架能夠捕捉到全身動作中微妙的交互細節,這對于理解和預測復雜的人類行為至關重要。這種交互性的理解有助于提高預測的準確性,特別是在涉及精細手部動作的場景中。
2.4 損失函數(Training Loss)
損失函數(Training Loss)主要包含四個部分:關節損失、物理損失、骨頭長度損失和對齊損失,具體如下:
- 關節損失():用于衡量模型預測的 3D 坐標準確性的損失。通過計算預測關節位置與真實關節位置(Ground Truth)之間的平均每關節位置誤差(Mean Per Joint Position Error,MPJPE)來實現:

- 物理損失():用于考慮手部動作的語義信息,特別是手腕的運動。通過計算預測的手腕關節位置與真實手腕關節位置之間的誤差來衡量。

- 骨頭長度損失():用于衡量預測的骨骼長度與真實骨骼長度之間的差異。計算每個骨骼段的預測長度與真實長度之間的差異。確保模型能夠準確地預測人體動作中骨骼的伸縮和變形非常重要,特別是在涉及到手部和腳部動作的預測中。通過最小化骨頭長度損失,模型能夠更準確地捕捉到動作中的細微變化。

- 對齊損失():用于衡量 XCA 模塊中特征分布的一致性。通過最小化不同身體組件特征分布之間的差異,有助于減少特征的異質性。

最終損失是所有損失函數的加權和,綜合了預測損失、物理損失和對齊損失。通過調整權重參數(λ1、λ2、λ3)來平衡這些損失,以確保模型在訓練過程中能夠同時優化預測準確性和特征的一致性。

三、實驗
3.1 實驗設置
數據集:本文采用 GRAB 數據集,它一個近期發布的大規模人體運動分析數據集,包含超過 160 萬幀的記錄,涉及 10 位不同演員執行的 29 種動作。這些動作通過高精度的運用運動捕捉技術進行捕捉。GRAB 提供了 SMPL-X 參數,從中提取了 25 個關節(3D 位置)定義為身體( = 25),每只手則表示為 15 個關節( = = 15),因此全身姿態總共包含 + + = 25 + 15 + 15 個關節。
評估指標:為了評估模型的性能,我們使用了平均每個關節位置誤差 MPJPE、手腕對齊后的 MPJPE-AW。MPJPE 用于衡量預測的 3D 坐標的準確性,而MPJPE-AW 則用于評估手部動作的精細預測,通過將手勢與手腕對齊來減少手腕運動對預測的影響。
實驗設置:我們采用了兩種訓練策略來評估不同方法的性能:
(1)分隔(D)訓練策略,分別針對每個人體組件的訓練基線方法,這種獨立策略缺乏組件之間的交互,可以用來說明 XCI 的有效性。
(2)聯合(U)訓練策略,將 GCN 的節點數擴展到 55( = 25, = = 15),這種策略通過全身圖隱含地包含跨上下文交互,但不考慮不同身體部分的異質性,用來展示 XCA 的有效性。訓練細節包括使用 AdamW 優化器,初始學習率為 0.001,批次大小為 64,訓練 50 個周期,每兩個周期學習率衰減0.96。權衡參數 {λ1, λ2, λ3} 設置為 {1, 0.1, 0.001}。
3.2 指標對比結果
我們首先統計了 GRAB 數據集上的平均預測性能(表 1),針對每種動作類型統計了預測性能(表 2)。我們分別展示了使用分割策略(標注為 D)和聯合策略(標注為 U)的預測結果。另外,每個表格中分別展示了身體關節的預測結果(major body)、左手關節的預測結果(left hand)、右手關節的預測結果(right hand),以及使用腕關節對齊后的左手對齊誤差(left hand AW)、右手對齊誤差(right hand AW),以及全身所有關節的預測結果(whole body)。

表1:GRAB 數據集上采用分隔(D)和聯合(U)訓練的平均預測結果

表2:采用統一訓練策略,GRAB 數據集上每一個動作類別下的預測結果
3.3 可視化對比結果
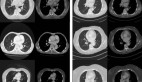
可視化對比結果部分提供了一種直觀的方式來評估和理解模型在預測全身動作方面的性能。通過展示「play」動作的全身骨骼形式,我們可以分析模型的預測性能。這些可視化結果可以幫助我們直觀地理解模型在預測精細動作和粗略動作方面的表現。可以清晰地看出,提出的 EAI 方法不僅在預測軀干姿態方面取得了最優的性能,而且對于細粒度的手部動作具有更好的預測結果。

「play」動作下的全身關節預測結果對比
3.4 消融實驗
消融實驗(Ablation Study)旨在評估 EAI 框架中不同組件對最終性能的貢獻程度。這些實驗通過單獨移除或修改框架中的某些部分來觀察模型性能的變化。具體來說,消融實驗包括以下幾個方面:
- 移除 XCA 和 XCI :首先,實驗移除了跨上下文對齊(XCA)和跨上下文交互(XCI)模塊,以觀察這些核心組件對模型性能的影響。通過比較移除這些組件前后的平均預測誤差,可以評估它們在提高預測準確性方面的重要性。
- 移除 XCA 的子模塊:進一步地,實驗移除了 XCA 中的交叉中性化(CN)和差異約束(DC)子模塊,以單獨評估這些技術在對齊不同身體部分特征分布中的作用。
- 移除 XCI 的子模塊:類似地,實驗移除了 XCI 中的語義交互(SI)和物理交互(PI)子模塊,以分析這些交互在捕捉身體部分之間相互作用中的效果。
- 全模型與消融模型比較:通過比較包含所有組件的全模型與經過消融的模型,可以直觀地看到每個組件對整體性能的具體貢獻。

移除不同組件時對于算法性能影響的分析
四、結束
在本研究中,小紅書創作發布團隊提出了一種創新的全身人體動作預測框架——編碼-對齊-交互(EAI),該框架旨在同時預測身體主要關節和手部的精細動作。我們通過引入跨上下文對齊(XCA)和跨上下文交互(XCI)機制,有效地處理了全身動作預測中的異質性和交互性問題。在新引入的 GRAB 數據集上的廣泛實驗表明,EAI 框架在 3D 全身人體動作預測方面取得了最先進的性能(SOTA),顯著提升了預測的準確性和表達性。
我們的工作不僅在理論上提出了新的預測框架,而且在實際應用中也展示了其潛力,尤其是在需要精細手部動作預測的場景中。這些技術能夠支撐小紅書媒體技術中面向細粒度人體動作生成、分析、建模的需求。不過這項工作仍有待進一步探索,例如,如何將與物體的交互納入模型,以提供更準確的運動預測。隨著未來研究的深入,我們期待 EAI 框架將為人體運動預測領域帶來更多的創新和突破。
論文地址:https://arxiv.org/pdf/2312.11972.pdf
代碼地址:https://github.com/Dingpx/EAI
五、作者簡介
- 丁鵬翔
碩士畢業于北京郵電大學,目前為西湖大學博士生,該工作完成于在小紅書實習期間。發表多篇期刊和會議論文,主要研究方向為人體動作分析,3D 計算機視覺。 - 崔瓊杰
博士畢業于南京理工大學,該工作完成于在小紅書實習期間。在 CVPR、ICCV、ECCV、IJCAI、AAAI 等國際會議上發表多篇論文,擔任多個國際頂級計算機視覺,人工智能會議的審稿人。目前主要研究方向為人體運動分析與合成。 - 王浩帆
小紅書創作發布組- AIGC 方向算法工程師,碩士畢業于卡內基梅隆大學,在 CVPR、ICCV、NeurIPS、3DV、AAAI、TPAMI 等國際會議和學術期刊上發表多篇論文。目前主要研究方向為圖像、視頻、3D 生成。