OLTP&OLAP超融合,揭秘新一代云原生數(shù)據(jù)庫的設(shè)計(jì)之道

MatrixOne 是一款面向未來的超融合異構(gòu)云原生數(shù)據(jù)庫管理系統(tǒng)。通過全新設(shè)計(jì)和研發(fā)的統(tǒng)一分布式數(shù)據(jù)庫引擎,能夠同時(shí)靈活支持 OLTP、OLAP、Streaming 等不同工作負(fù)載的數(shù)據(jù)管理和應(yīng)用,用戶可以在公有云、自建數(shù)據(jù)中心和邊緣節(jié)點(diǎn)上無縫部署和運(yùn)行。其優(yōu)點(diǎn)包括:簡(jiǎn)單易用,成本較低,性能優(yōu)異,靈活擴(kuò)展。本文將對(duì) MatrixOne 存儲(chǔ)格式設(shè)計(jì)進(jìn)行詳細(xì)解讀。
一、MatrixOne 存儲(chǔ)格式設(shè)計(jì)的初衷
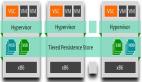
1. MatrixOne 架構(gòu)解讀

MatrixOne 整體架構(gòu)分為三層,分別為:
計(jì)算層,設(shè)計(jì)為多節(jié)點(diǎn)結(jié)構(gòu),主要負(fù)責(zé)提取數(shù)據(jù),完成計(jì)算功能。
中間層,事務(wù)處理與元數(shù)據(jù)層面、共享日志,主要功能是提供完整的日志服務(wù)以及元數(shù)據(jù)信息。
對(duì)接層,通過 File Service 對(duì)接底層各種不同的存儲(chǔ),比如 S3、用戶的本地文件、NAS 等。
數(shù)據(jù)執(zhí)行過程:
插入一條數(shù)據(jù),系統(tǒng)接到請(qǐng)求后,這一條數(shù)據(jù)提交到事務(wù)處理層,之后系統(tǒng)將數(shù)據(jù)寫到共享日志中,再返回給用戶提示,表示操作成功。
有三點(diǎn)需要注意:
第一點(diǎn):事務(wù)處理層(TN)剛開始寫數(shù)據(jù)會(huì)比較小,系統(tǒng)會(huì)先在內(nèi)存里面做組織結(jié)構(gòu),等積累到足夠的量,比如幾千行或 1 萬行,再將這些數(shù)據(jù)落盤,落盤后的數(shù)據(jù)定義為一個(gè) block。
第二點(diǎn):剛開始用戶寫數(shù)據(jù)是比較小的,隨著數(shù)據(jù)量的增長(zhǎng),系統(tǒng)會(huì)把數(shù)據(jù)都 MER merge 起來,然后不停地 merge,方便用戶直接查數(shù)據(jù),做分析。
第三點(diǎn):遇到在寫入數(shù)據(jù)過程中,操作多及數(shù)據(jù)量大的時(shí)候,系統(tǒng)會(huì)直接將數(shù)據(jù)寫入 Database 或者寫入 S3,寫入完成后,通過發(fā)布 service,提交到系統(tǒng)后臺(tái)。

如上圖右邊的結(jié)構(gòu),從上至下,第一層是 DB,第二層是 table,DB 和 table 存在元數(shù)據(jù)里,具體的數(shù)據(jù)分為多個(gè) object,一個(gè) object 又可以分為多個(gè) block。
2. MatrixOne 存儲(chǔ)格式設(shè)計(jì)的初衷

從 MatrixOne 0.5 開始,現(xiàn)在已經(jīng)發(fā)布到 1.1,一直采用列存的結(jié)構(gòu),因?yàn)榱写鎸?duì) AP 容易優(yōu)化,負(fù)載可以靈活適配;一個(gè) Column 數(shù)據(jù),和大多數(shù)數(shù)據(jù)庫的 Hive 文件排列結(jié)構(gòu)比較相似,每一個(gè)列有獨(dú)立的 block,用戶可以通過這些列來查詢數(shù)據(jù)。
對(duì)于 MatrixOne 來說,需要滿足所有的業(yè)務(wù)類型,比如數(shù)據(jù)庫表的數(shù)據(jù),table、DB、Catalog 的元數(shù)據(jù)管理、元數(shù)據(jù)落盤、再做 Replay。
業(yè)務(wù)數(shù)據(jù)在運(yùn)行過程中,有很多 trace log、raw log,為了方便用戶查看 log,也要對(duì)這些數(shù)據(jù)做足夠的支撐。
遇到類似 AP 場(chǎng)景,有很大數(shù)據(jù)量的查詢,查詢結(jié)果后續(xù)可能還會(huì)調(diào)用,系統(tǒng)會(huì)把常用查詢結(jié)果存儲(chǔ)在本地文件或者是 S3 上,方便后續(xù)直接調(diào)用常用結(jié)果型數(shù)據(jù)。
為了滿足所有的業(yè)務(wù)數(shù)據(jù),不同的數(shù)據(jù)類型方便去訪問,且不影響數(shù)據(jù)查詢時(shí)效,采用 File Server 中的 S3 共享存儲(chǔ)可以解決此問題。S3 的對(duì)象存儲(chǔ),每一個(gè)對(duì)象都需要存儲(chǔ)指定的行,或者是指定 size,或者是指定的 block。block 有很多,存儲(chǔ)一個(gè)對(duì)象可能會(huì)有多種類型的 block,可能 schema 都不一樣,這些不同的 schema,需要哪些 block,需要用 block 的語言數(shù)據(jù)分析,之后更新 block 的源數(shù)據(jù),才能得到真正的數(shù)據(jù)存放地址。這就是保證便捷高效的元數(shù)據(jù)請(qǐng)求訪問的原理。
用戶數(shù)據(jù)在正常運(yùn)行一段時(shí)間之后,需要 scrub 任務(wù)來校驗(yàn)一下數(shù)據(jù)正確性,MatrixOne 提供了一些工具,來滿足這些需求,幫助用戶做數(shù)據(jù)維護(hù)。
3. 數(shù)據(jù)結(jié)構(gòu)解析

結(jié)構(gòu)圖最上方 Header 會(huì)記錄對(duì)象的版本信息、數(shù)據(jù)格式、元數(shù)據(jù)的位置、校驗(yàn)值位置,結(jié)構(gòu)圖最下方的 footer 是 head 的鏡像。
結(jié)構(gòu)圖 Header 以下是數(shù)據(jù)區(qū),寫入的業(yè)務(wù)數(shù)據(jù)在內(nèi)存打包處理后寫到這個(gè)數(shù)據(jù)區(qū),在數(shù)據(jù)區(qū)里將寫入的數(shù)據(jù)稱為一個(gè) block,結(jié)構(gòu)圖再往下一層是整個(gè)對(duì)象的元數(shù)據(jù)區(qū)域。
首先是索引區(qū)域,比如現(xiàn)有的 feature 還有 Romec 都存在里面。
結(jié)構(gòu)圖最后一層是整個(gè)對(duì)象的 Meta 標(biāo)記,包括整個(gè)對(duì)象怎么解析,怎么去讀。
當(dāng)用戶寫完數(shù)據(jù)成功后,系統(tǒng)會(huì)有一個(gè) offset 指向整個(gè) Meta data 區(qū)域。

Metadata 的結(jié)構(gòu)如上圖所示。
Tombstone 就是用戶 data,用戶寫完后可能要?jiǎng)h某一行,因?yàn)閷懭胂到y(tǒng)不能直接修改,需要?jiǎng)h的那一行,系統(tǒng)會(huì)再記錄一下,也就是軟刪。
SubMeta 會(huì)存儲(chǔ) catalog、block、object 等,用戶讀數(shù)據(jù)的時(shí)候,需要這些元數(shù)據(jù),簡(jiǎn)稱為 checkpoint。Checkpoint 存在 SubMeta 里面,有 20 多種。為了保障性能,用戶要提取一套數(shù)據(jù),系統(tǒng)只需要指針偏移,就可以去拿到對(duì)應(yīng)的 Meta,記錄這些 Meta 存在的位置,就需要 SubMetaIndex。
DataMeta、TombstoneMeta、SubMeta,每一個(gè) Meta 都有 head 去記錄整個(gè) Meta 的信息。

Block 層結(jié)構(gòu)如上圖。
每個(gè) block 有不同的值,整個(gè)數(shù)據(jù)的 Meta 的checkpoint、columncnt,rows或者 Bloom Fitter 這些索引,都記錄在 supplement。還有一些 block 的 index 用來記錄 block 的偏移,block 的數(shù)量不是固定的,所以系統(tǒng)要記錄 index。否則如果先去讀有多少 block,然后通過這些 block 去算需要的 block 具體在哪里,這樣對(duì)整體性能要求很高,所以系統(tǒng)會(huì)記住 block index,記錄固定的起止位置來標(biāo)記 block 都在哪里,從而便于讀取。

DBID、TableID、AccountID 等內(nèi)容具體解釋如上圖所示。

ColumnMeta 記錄第幾列,當(dāng)前列是什么 type;NDV 即 column 中有多少不同的值;NullCnt 記錄的是這一列中有多少 null 值;DataExtent 記錄的是數(shù)據(jù)位置,也會(huì)記錄壓縮前和壓縮后的數(shù)據(jù)大小;Chksum 是數(shù)據(jù)的 checksum;ZoneMap 是指這列的 MinMax 索引,然后通過 index 當(dāng)前尋找的偏行地址就可以讀這個(gè)數(shù)據(jù)。

用戶寫完數(shù)據(jù)后,會(huì)返回一個(gè)記錄對(duì)象 Meta 位置的 extent,并保存到 catalog 也就是 Metadata 當(dāng)中。當(dāng)用戶使用系統(tǒng)去執(zhí)行查詢數(shù)據(jù)所需要去讀數(shù)據(jù)的時(shí)候,可以通過這個(gè) extent 去查詢整個(gè)對(duì)象的 Meta,從而通過 Meta 一層一層去看到具體的 column data。
通過一個(gè) extent,就可以去讀取一個(gè) IO,因?yàn)橄到y(tǒng)中一個(gè)對(duì)象里面最小的單位是 IO entry,根據(jù)不同的 IO 它可分成不同的 IO entry。比如一個(gè) column data,column 是一列,就等于一個(gè) IO,可以一列一列地讀,或者一個(gè) Meta,也是一個(gè) IO,或者 bloomfilter,也是一個(gè) IO,可以通過一個(gè) IO 讀出所有不同的 feed,方便過濾。
通過 IO entry,查詢到這個(gè)對(duì)象的 Meta,然后查詢真正的數(shù)據(jù)。通過 Meta 讀數(shù)據(jù),需要先查找數(shù)據(jù)的 head,然后得到 block index 就可以很方便地去獲取到 block 的 Meta,每一列都在 block Meta 里面,包括如何方便地查詢一些 column,可以看到 column Meta,column Meta 里面就記錄著 data 的 extent,然后可以根據(jù)這些 IO 去讀數(shù)據(jù),能夠很方便地獲得真正想要的數(shù)據(jù)。
當(dāng)遇到有些數(shù)據(jù)不常用到但也需要去分析時(shí),用戶決定讀哪些數(shù)據(jù),對(duì)應(yīng)對(duì)象的Meta 就需要不停地去查,系統(tǒng)會(huì)將對(duì)象的 Meta 放在常駐緩存中,解決數(shù)據(jù)讀取時(shí)效的問題。
二、性能的保證

需要訪問的數(shù)據(jù)多種多樣,包括元數(shù)據(jù)、Table data、索引、checkpoint 以及各種日志。為了保證低成本訪問,需要做 metadata cache、index cache 等等。拿到數(shù)據(jù)后,需要高效地解析。

為了實(shí)現(xiàn)對(duì)元數(shù)據(jù)的高效解析,我們也做了很多嘗試。比如采用 byte 的方式,放在內(nèi)存里面也不需要序列化,直接去用就可以了。要去讀哪些字段時(shí),靠指針偏移即可完成。
數(shù)據(jù)寫入的時(shí)候也很方便,set 一個(gè) block ID,相當(dāng)于通過 block ID 這個(gè)結(jié)構(gòu)先做成 byte,可以直接拷貝,指針操作也很方便。
通過 Benchmark 做反序列化解析,只要拿到相應(yīng)的 Meta data 的 ID,整個(gè)解析過程會(huì)比較快,是納秒級(jí)別的速度。
三、數(shù)據(jù)兼容性和使?場(chǎng)景
1. 數(shù)據(jù)兼容性

兼容性也是個(gè)很重要的問題,比如客戶已經(jīng)用了一兩年,有些優(yōu)化需要修改數(shù)據(jù)格式,那么新的代碼肯定要對(duì)以前的數(shù)據(jù)做好兼容。
我們的方案比較簡(jiǎn)單,每個(gè) IO Entry 會(huì)在 Header 中標(biāo)記 Data Type,type 會(huì)決定如何 encode 和 decode。Version 是 type 的版本。版本切換時(shí),注冊(cè)相應(yīng)的 encode 和 decode 函數(shù),讀到相應(yīng)的 IO Entry Header,選擇對(duì)應(yīng)的函數(shù),解析數(shù)據(jù),這樣就可以實(shí)現(xiàn)兼容。

以上是結(jié)構(gòu)圖,IOEntryHeader 中記錄著 Type 和 Version。Type 包括對(duì)象的 Meta,column data,還有 index 等等。用戶寫數(shù)據(jù)時(shí),系統(tǒng)會(huì)注冊(cè)一個(gè) encode 函數(shù),如果要寫入對(duì)象的 Meta,對(duì)象 Meta 是版本 2,就會(huì)標(biāo)記 type 為 type1,版本是 version2,后面就是要寫入的 Meta的byte。
讀的時(shí)候,先讀到 header,因?yàn)橄到y(tǒng)去讀 IO Entry 是把所有的東西都讀上來,之后先拿前面兩個(gè)字段,通過 header 去做解析。
從開始到現(xiàn)在,MatrixOne 的版本只變過三次,每個(gè)版本會(huì)有簡(jiǎn)潔的對(duì)應(yīng)的函數(shù),維護(hù)起來非常便捷。
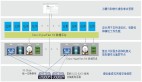
2. 應(yīng)用場(chǎng)景

系統(tǒng)有單獨(dú)的 log service,其余所有的數(shù)據(jù)結(jié)構(gòu)都使用這種結(jié)構(gòu)-落盤讀取,包括正常業(yè)務(wù)的讀寫 table 數(shù)據(jù),查詢或者插入等等。
支持 checkpoint、catalog。系統(tǒng)隔一段時(shí)間會(huì)打一個(gè) checkpoint,記錄增加了哪個(gè) DB,DB 里面增加了幾個(gè) table,如果是落盤的數(shù)據(jù),增加哪個(gè)對(duì)象,以及具體的對(duì)象數(shù)據(jù)的里面 block。啟動(dòng)的時(shí)候,系統(tǒng)會(huì)根據(jù) checkpoint,replay 出來 catalog。用戶可以根據(jù) Catalog 去查詢 DB 數(shù)據(jù)。
Metadata 掃描的主要功能是查看 scan 用戶存了多少數(shù)據(jù),存了多少表 DB,這些 DB 具體有多少個(gè)對(duì)象文件,對(duì)象到底都有多大,壓縮前、壓縮后分別是多大等等。Metadata 掃描會(huì)用到對(duì)象的 metadata,常駐在緩存里面,效率很高。
查詢結(jié)果的 cache 的使用,在遇到比較大的查詢分析時(shí),比如一個(gè)查詢分析要幾秒,耗費(fèi)計(jì)算資源比較多,系統(tǒng)會(huì)將這些結(jié)果都存在 cache 里。這樣用戶下次查詢就不需要再重新去 load 那么多數(shù)據(jù)再重新計(jì)算。

四、問答環(huán)節(jié)
Q1:社區(qū)實(shí)現(xiàn)動(dòng)態(tài) catalog 會(huì)考慮任務(wù)修改?
A1:現(xiàn)在 Catalog 是通過 checkpoint 來做,問題已經(jīng)得到解決,checkpoint 所有都是增量的,增量的所有的記錄都會(huì)記錄下來,增刪改查或 DDL,這些東西都記錄在 checkpoint 里面,只要 Replay 即可。Catalog 也是常駐在內(nèi)存當(dāng)中的,可以進(jìn)行原子性的控制。
Q2:比如企業(yè)已有一個(gè)非常完善的,且有很多存量數(shù)據(jù)的集群,在這種情況下怎么使用 MatrixOne 呢?
A2:MatrixOne 對(duì)外提供了集群對(duì)接的小工具,MoDump,可以實(shí)現(xiàn) load 這些數(shù)據(jù)。首先要做的是把這些數(shù)據(jù)打包 load 出來,然后再把這些數(shù)據(jù) load 到產(chǎn)品里面。后期會(huì)開發(fā)一些對(duì)接各種數(shù)據(jù)庫可以實(shí)時(shí)拷貝的工具。