













劍橋團隊開源:賦能多模態大模型RAG應用,首個預訓練通用多模態后期交互知識檢索器

- 論文鏈接:https://arxiv.org/abs/2402.08327
- DEMO 鏈接:https://u60544-b8d4-53eaa55d.westx.seetacloud.com:8443/
- 項目主頁鏈接:https://preflmr.github.io/
- 論文標題:PreFLMR: Scaling Up Fine-Grained Late-Interaction Multi-modal Retrievers
背景
盡管多模態大模型(例如 GPT4-Vision、Gemini 等)展現出了強大的通用圖文理解能力,它們在回答需要專業知識的問題時表現依然不盡人意。即使 GPT4-Vision 也無法回答知識密集型問題(圖一上),這成為了很多企業級落地應用的瓶頸。
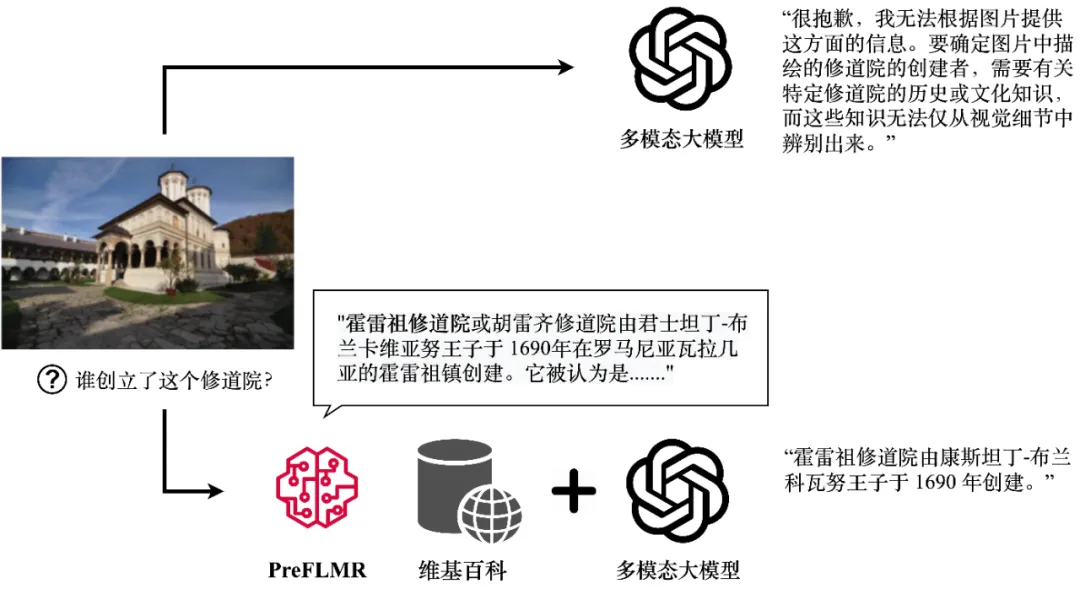
圖 1:GPT4-Vision 在 PreFLMR 多模態知識檢索器的幫助下可以獲得相關知識,生成正確的答案。圖中展示了模型的真實輸出。
針對這個問題,檢索增強生成(RAG,Retrieval-Augmented Generation)提供了一個簡單有效的讓多模態大模型成為” 領域專家” 的方案:首先,一個輕量的知識檢索器(Knowledge Retriever)從專業數據庫(例如 Wikipedia 或企業知識庫)中獲得相關的專業知識;然后,大模型將這些知識和問題一起作為輸入,生成準確的答案。多模態知識提取器的知識 “召回能力” 直接決定了大模型在回答推理時能否獲得準確的專業知識。
近期,劍橋大學信息工程系人工智能實驗室完整開源了首個預訓練、通用多模態后期交互知識檢索器 PreFLMR (Pre-trained Fine-grained Late-interaction Multi-modal Retriever)。相比以往常見的模型,PreFLMR 有以下特點:
1.PreFLMR 是一個可以解決文文檢索,圖文檢索,知識檢索等多個子任務的通用預訓練模型。該模型經過百萬級的多模態數據預訓練后,在多個下游檢索任務中取得了優秀的表現。同時,作為一個優秀的基底模型,PreFLMR 在私有數據上稍加訓練就能夠獲得表現極佳的領域專用模型。
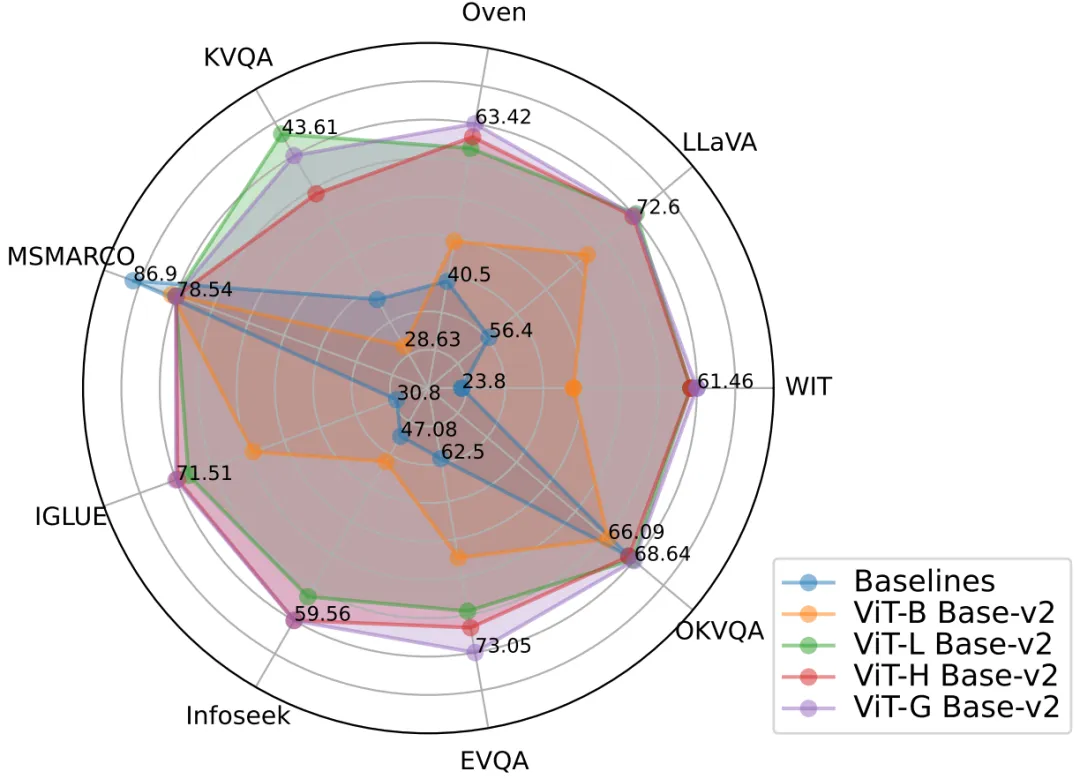
圖 2:PreFLMR 模型同時在多項任務上取得極佳的多模態檢索表現,是一個極強的預訓練基底模型。
2. 傳統的密集文本檢索(Dense Passage Retrieval, DPR)只使用一個向量表征問詢(Query)或文檔(Document)。劍橋團隊在 NeurIPS 2023 發表的 FLMR 模型證明了 DPR 的單向量表征設計會導致細粒度信息損失,導致 DPR 在需要精細信息匹配的檢索任務上表現不佳。尤其是在多模態任務中,用戶的問詢(Query)包含復雜場景信息,壓縮至一維向量極大抑制了特征的表達能力。PreFLMR 繼承并改進了 FLMR 的結構,使其在多模態知識檢索中有得天獨厚的優勢。

圖 3:PreFLMR 在字符級別(Token level)上編碼問詢(Query,左側 1、2、3)和文檔(Document,右側 4),相比于將所有信息壓縮至一維向量的 DPR 系統有信息細粒度上的優勢。
3.PreFLMR 能夠根據用戶輸入的指令(例如 “提取能用于回答以下問題的文檔” 或 “提取與圖中物品相關的文檔”),從龐大的知識庫中提取相關的文檔,幫助多模態大模型大幅提升在專業知識問答任務上的表現。



圖 4:PreFLMR 可以同時處理圖片提取文檔、根據問題提取文檔、根據問題和圖片一起提取文檔的多模態問詢任務。
劍橋大學團隊開源了三個不同規模的模型,模型的參數量由小到大分別為:PreFLMR_ViT-B (207M)、PreFLMR_ViT-L (422M)、PreFLMR_ViT-G (2B),供使用者根據實際情況選取。
除了開源模型 PreFLMR 本身,該項目還在該研究方向做出了兩個重要貢獻:
- 該項目同時開源了一個訓練和評估通用知識檢索器的大規模數據集,Multi-task Multi-modal Knowledge Retrieval Benchmark (M2KR),包含 10 個在學界中被廣泛研究的檢索子任務和總計超過百萬的檢索對。
- 在論文中,劍橋大學團隊對比了不同大小、不同表現的圖像編碼器和文本編碼器,總結了擴大參數和預訓練多模態后期交互知識檢索系統的最佳實踐,為未來的通用檢索模型提供經驗性的指導。
下文將簡略介紹 M2KR 數據集,PreFLMR 模型和實驗結果分析。
M2KR 數據集
為了大規模預訓練和評估通用多模態檢索模型,作者匯編了十個公開的數據集并將其轉換為統一的問題 - 文檔檢索格式。這些數據集的原本任務包括圖像描述(image captioning),多模態對話(multi-modal dialogue)等等。下圖展示了其中五個任務的問題(第一行)和對應文檔(第二行)。

圖 5:M2KR 數據集中的部分知識提取任務
PreFLMR 檢索模型

圖 6:PreFLMR 的模型結構。問詢(Query)被編碼為 Token-level 的特征。PreFLMR 對問詢矩陣中的每一個向量,找到文檔矩陣中的最近向量并計算點積,然后對這些最大點積求和得到最后的相關度。
PreFLMR 模型基于發表于 NeurIPS 2023 的 Fine-grained Late-interaction Multi-modal Retriever (FLMR) 并進行了模型改進和 M2KR 上的大規模預訓練。相比于 DPR,FLMR 和 PreFLMR 用由所有的 token 向量組成的矩陣對文檔和問詢進行表征。Tokens 包含文本 tokens 和投射到文本空間中的圖像 tokens。后期交互(late interaction)是一種高效計算兩個表征矩陣之間相關性的算法。具體做法為:對問詢矩陣中的每一個向量,找到文檔矩陣中的最近向量并計算點積。然后對這些最大點積求和得到最后的相關度。這樣,每個 token 的表征都可以顯式地影響最終的相關性,以此保留了 token-level 的細粒度(fine-grained)信息。得益于專門的后期交互檢索引擎,PreFLMR 在 40 萬文檔中提取 100 個相關文檔僅需 0.2 秒,這極大地提高了 RAG 場景中的可用性。
PreFLMR 的預訓練包含以下四個階段:
- 文本編碼器預訓練:首先,在 MSMARCO(一個純文本知識檢索數據集)上預訓練一個后期交互文文檢索模型作為 PreFLMR 的文本編碼器。
- 圖像 - 文本投射層預訓練:其次,在 M2KR 上訓練圖像 - 文本投射層并凍結其它部分。該階段只使用經過投射的圖像向量進行檢索,旨在防止模型過度依賴文本信息。
- 持續預訓練:然后,在 E-VQA,M2KR 中的一個高質量知識密集型視覺問答任務上持續訓練文本編碼器和圖像 - 文本投射層。這一階段旨在提升 PreFLMR 的精細知識檢索能力。
- 通用檢索訓練:最后,在整個 M2KR 數據集上訓練所有權重,只凍結圖像編碼器。同時,將問詢文本編碼器和文檔文本編碼器的參數解鎖進行分別訓練。這一階段旨在提高 PreFLMR 的通用檢索能力。
同時,作者展示了 PreFLMR 可以在子數據集(如 OK-VQA、Infoseek)上進一步微調以在特定任務上獲得更好的檢索性能。
實驗結果和縱向擴展
最佳檢索結果:表現最好的 PreFLMR 模型使用 ViT-G 作為圖像編碼器和 ColBERT-base-v2 作為文本編碼器,總計二十億參數。它在 7 個 M2KR 檢索子任務(WIT,OVEN,Infoseek, E-VQA,OKVQA 等)上取得了超越基線模型的表現。
擴展視覺編碼更加有效:作者發現將圖像編碼器 ViT 從 ViT-B(86M)升級到 ViT-L(307M)帶來了顯著的效果提升,但是將文本編碼器 ColBERT 從 base(110M)擴展到 large(345M)導致表現下降并造成了訓練不穩定問題。實驗結果表明對于后期交互多模態檢索系統,增加視覺編碼器的參數帶來的回報更大。同時,使用多層 Cross-attention 進行圖像 - 文本投射的效果與使用單層相同,因此圖像 - 文本投射網絡的設計并不需要過于復雜。
PreFLMR 讓 RAG 更加有效:在知識密集型視覺問答任務上,使用 PreFLMR 進行檢索增強大大提高了最終系統的表現:在 Infoseek 和 EVQA 上分別達到了 94% 和 275% 的效果提升,經過簡單的微調,基于 BLIP-2 的模型能夠擊敗千億參數量的 PALI-X 模型和使用 Google API 進行增強的 PaLM-Bison+Lens 系統。
結論
劍橋人工智能實驗室提出的 PreFLMR 模型是第一個開源的通用后期交互多模態檢索模型。經過在 M2KR 上的百萬級數據預訓練,PreFLMR 在多項檢索子任務中展現出強勁的表現。M2KR 數據集,PreFLMR 模型權重和代碼均可以在項目主頁 https://preflmr.github.io/ 獲取。
拓展資源
- FLMR paper (NeurIPS 2023): https://proceedings.neurips.cc/paper_files/paper/2023/hash/47393e8594c82ce8fd83adc672cf9872-Abstract-Conference.html
- 代碼庫:https://github.com/LinWeizheDragon/Retrieval-Augmented-Visual-Question-Answering
- 英文版博客:https://www.jinghong-chen.net/preflmr-sota-open-sourced-multi/
- FLMR 簡介:https://www.jinghong-chen.net/fined-grained-late-interaction-multimodal-retrieval-flmr/




























