北大彭宇新教授團隊開源細粒度多模態(tài)大模型Finedefics
本文是北京大學彭宇新教授團隊在細粒度多模態(tài)大模型領域的最新研究成果,相關論文已被 ICLR 2025 接收,并已開源。
盡管多模態(tài)大模型在通用視覺理解任務中表現出色,但不具備細粒度視覺識別能力,這極大制約了多模態(tài)大模型的應用與發(fā)展。
細粒度視覺識別旨在區(qū)分同一粗粒度大類下的不同細粒度子類別,如將鳥類(粗粒度大類)圖像區(qū)分為西美鷗、灰背鷗、銀鷗等(細粒度子類別);將車區(qū)分為寶馬、奔馳、奧迪等,奧迪區(qū)分為 A4、A6、A8 等;將飛機區(qū)分為波音 737、波音 747、波音 777、空客 320、空客 380 等。實現對視覺對象的細粒度識別,在現實生產和生活中具有重要的研究和應用價值。
針對這一問題,北京大學彭宇新教授團隊系統地分析了多模態(tài)大模型在細粒度視覺識別上所需的 3 項能力:對象信息提取能力、類別知識儲備能力、對象 - 類別對齊能力,發(fā)現了「視覺對象與細粒度子類別未對齊」是限制多模態(tài)大模型的細粒度視覺識別能力的關鍵問題,并提出了細粒度多模態(tài)大模型 Finedefics。
首先,Finedefics 通過提示大語言模型構建視覺對象的細粒度屬性知識;然后,通過對比學習將細粒度屬性知識分別與視覺對象的圖像與文本對齊,實現數據 - 知識協同訓練。
Finedefics 在 6 個權威細粒度圖像分類數據集 Stanford Dog-120、Bird-200、FGVC-Aircraft、Flower-102、Oxford-IIIT Pet-37、Stanford Car-196 上的平均準確率達到了 76.84%,相比 Hugging Face 2024 年 4 月發(fā)布的 Idefics2 大模型提高了 10.89%。

- 論文標題:Analyzing and Boosting the Power of Fine-Grained Visual Recognition for Multi-modal Large Language Models
- 論文鏈接:https://openreview.net/forum?id=p3NKpom1VL
- 開源代碼:https://github.com/PKU-ICST-MIPL/Finedefics_ICLR2025
- 模型地址:https://huggingface.co/StevenHH2000/Finedefics
- 實驗室網址:https://www.wict.pku.edu.cn/mipl
背景與動機
多模態(tài)大模型是指提取并融合文本、圖像、視頻等多模態(tài)數據表征,通過大語言模型進行推理,經過微調后適配到多種下游任務的基礎模型。
盡管現有多模態(tài)大模型在視覺問答、推理等多種任務上表現出色,但存在識別粒度粗的局限性:因為多模態(tài)大模型的視覺識別能力依賴大量訓練數據,由于訓練數據的細粒度子類別的標注成本巨大,實際也是無法細粒度標注的,導致現有多模態(tài)大模型缺乏細粒度視覺識別能力。
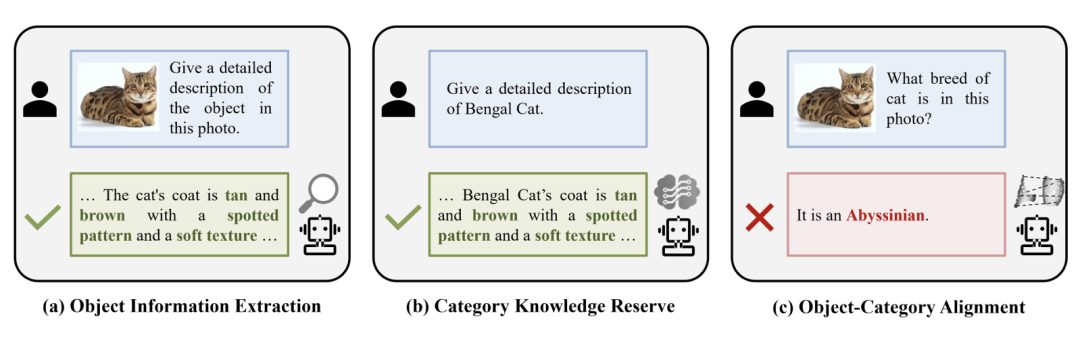
圖 1. 多模態(tài)大模型在細粒度視覺識別上所需的 3 項能力
本文系統地分析了多模態(tài)大模型在細粒度視覺識別上所需的 3 項能力,如圖 1 所示,包括:
1. 對象信息提取能力:視覺編碼器能夠從圖像中準確并全面地提取區(qū)分不同細粒度子類別的辨識性信息;
2. 類別知識儲備能力:大語言模型能夠儲備充分的細粒度子類別知識;
3. 對象 - 類別對齊能力:基于提取的辨識性視覺信息與儲備的細粒度子類別知識,在大語言模型的表征空間中對齊視覺對象與細粒度子類別,以建立輸入圖像到子類別名稱的細粒度映射關系。
實驗結果表明,「視覺對象與細粒度子類別未對齊」是限制多模態(tài)大模型具備細粒度視覺識別能力的關鍵問題。
技術方案
為解決視覺對象與細粒度子類別未對齊的問題,本文提出了細粒度多模態(tài)大模型 Finedefics。
如圖 2 所示,Finedefics 構建過程包含 2 個主要步驟:
1. 首先通過屬性描述構建,利用辨識屬性挖掘獲得區(qū)分細粒度子類別的關鍵特征,例如區(qū)分貓的品種的辨識性屬性「毛色」、「毛型」、「毛皮質地」等,并利用視覺屬性提取獲得圖像對象的辨識性屬性對,例如「毛色:棕褐色」、「毛型:帶有斑紋」、「毛皮質地:質地柔軟」等,再利用屬性描述總結將屬性對轉化為自然語言形式的對象屬性描述,例如「圖中小貓的毛為棕褐色,帶有斑紋,質地柔軟」;
2. 然后通過屬性增強對齊,將構建的對象屬性描述作為視覺對象與細粒度子類別的共同對齊目標,通過對象 - 屬性、屬性 - 類別、類別 - 類別對比學習充分建立視覺對象與細粒度子類別的細粒度對應關系,再利用以識別為中心的指令微調促進模型遵循細粒度視覺識別的任務指令。具體地,包含如下兩個訓練階段:
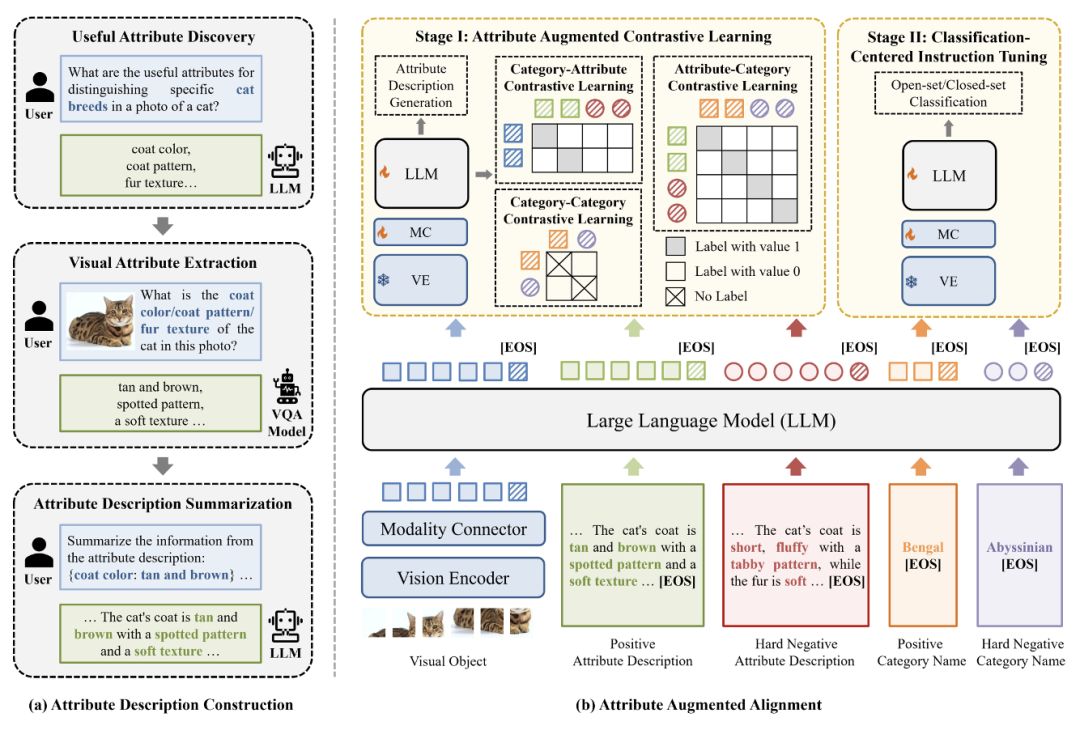
圖 2. 細粒度多模態(tài)大模型(Finedefics)框架圖
階段 I:屬性增強的對比學習
首先,針對每個「對象 - 屬性 - 類別」三元組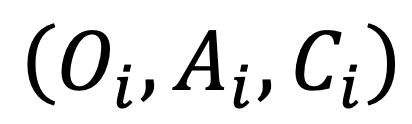 ,利用視覺編碼器
,利用視覺編碼器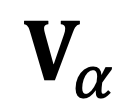 與可學習的模態(tài)連接層
與可學習的模態(tài)連接層  將
將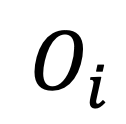 轉化為對象表征序列
轉化為對象表征序列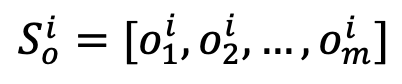 。
。
為更好捕捉全局表示,將標識符 [EOS] 輸入大語言模型的嵌入層得到向量表示,并將其與對象特征序列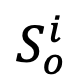 拼接,得到新構建的對象表征序列
拼接,得到新構建的對象表征序列  。相似地,得到屬性表征序列
。相似地,得到屬性表征序列 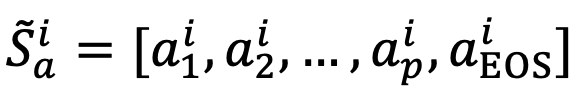 與類別表征序列
與類別表征序列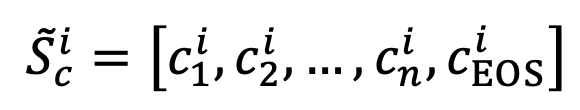 。
。
然后,分別將 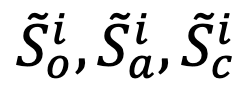 輸入到大語言模型中,將序列末尾的預測標志(token)
輸入到大語言模型中,將序列末尾的預測標志(token)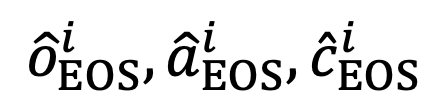 分別作為
分別作為 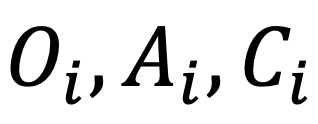 的全局表示。
的全局表示。
為簡化表示,定義 訓練采用的對比學習損失包含以下 3 種:
訓練采用的對比學習損失包含以下 3 種:
對象 - 屬性對比:為細粒度視覺識別數據集中的每個視覺對象 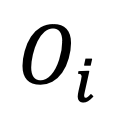 挖掘困難負樣本。具體地,針對每張樣本圖像,從三個最相似但錯誤的細粒度子類別數據中選擇負樣本,并將其屬性描述與細粒度子類別名稱作為困難負樣本加入對比學習。
挖掘困難負樣本。具體地,針對每張樣本圖像,從三個最相似但錯誤的細粒度子類別數據中選擇負樣本,并將其屬性描述與細粒度子類別名稱作為困難負樣本加入對比學習。
因此,引入困難負樣本后的對象 - 屬性對比(Object-Attribute Contrastive, OAC)損失表示如下:
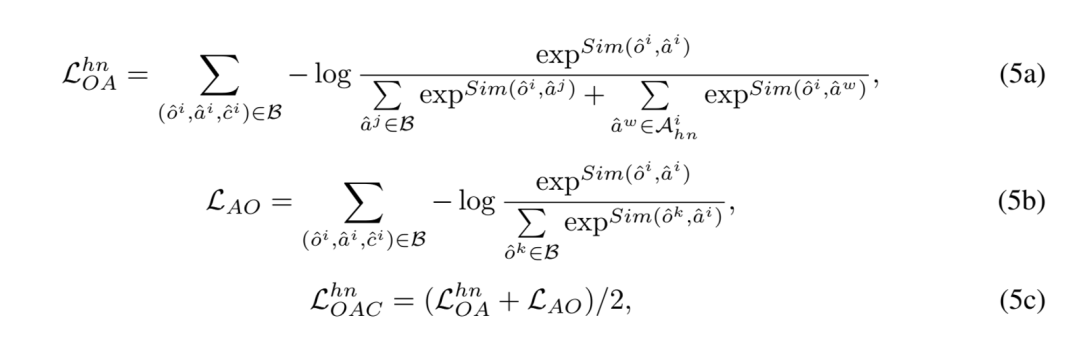
其中,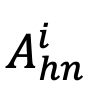 表示對象
表示對象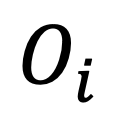 困難負樣本的屬性表征集合,Sim (?,?) 測量特征空間的余弦相似度。
困難負樣本的屬性表征集合,Sim (?,?) 測量特征空間的余弦相似度。
屬性 - 類別對比:相似地,引入困難負樣本后的屬性 - 類別對比(Attribute-Category Contrastive, ACC)損失表示如下:
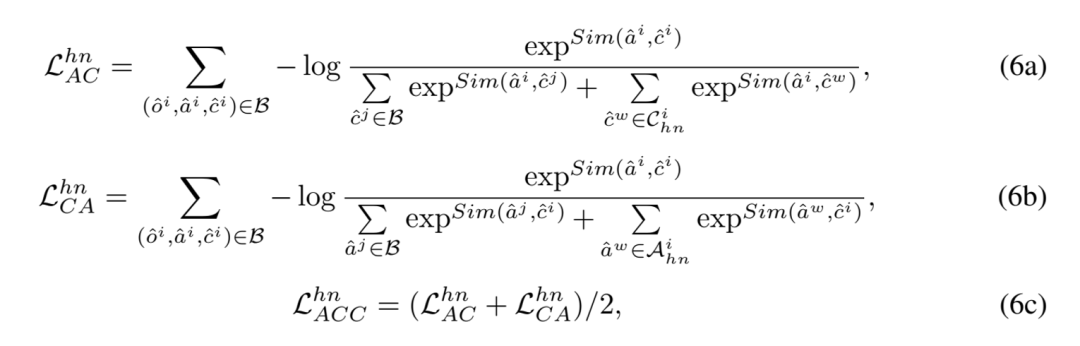
其中,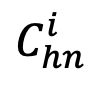 表示對象
表示對象 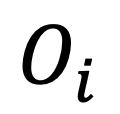 困難負樣本的細粒度子類別表征集合。
困難負樣本的細粒度子類別表征集合。
類別 - 類別對比:由于難以在大語言模型的表征空間中區(qū)分不同細粒度子類別,提出了類別 - 類別對比(Category-Category Contrastive, CCC)損失如下:
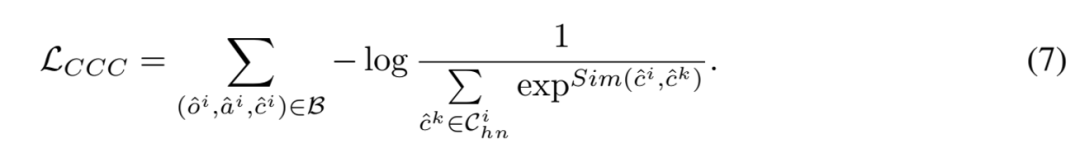
此外,為保持模型的生成能力,將屬性描述作為生成目標,采用下一個標記預測(Next Token Prediction)任務進行模型訓練。因此,階段 I 的優(yōu)化目標定義如下:
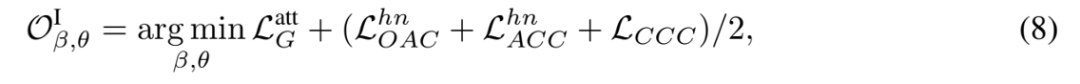
其中,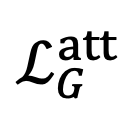 表示屬性描述生成損失。
表示屬性描述生成損失。
階段 II:以識別為中心的指令微調
將細粒度視覺識別數據集構建為兩種形式的指令微調數據:開集問答數據與閉集多選題數據,利用上述指令微調數據更新模型參數。因此,階段 II 模型的優(yōu)化目標定義如下:

其中,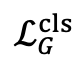 表示以識別為中心的指令微調損失。
表示以識別為中心的指令微調損失。
實驗結果
 表 1. 細粒度多模態(tài)大模型(Finedefics)實驗結果
表 1. 細粒度多模態(tài)大模型(Finedefics)實驗結果
表 1 的實驗結果表明,Finedefics 在 6 個權威細粒度圖像分類數據集 Stanford Dog-120、Bird-200、FGVC-Aircraft、Flower-102、Oxford-IIIT Pet-37、Stanford Car-196 上的平均準確率達到了 76.84%,相比阿里 2024 年 1 月發(fā)布的通義千問大模型(Qwen-VL-Chat)提高了 9.43%,相比 Hugging Face 2024 年 4 月發(fā)布的 Idefics2 大模型提高了 10.89%。
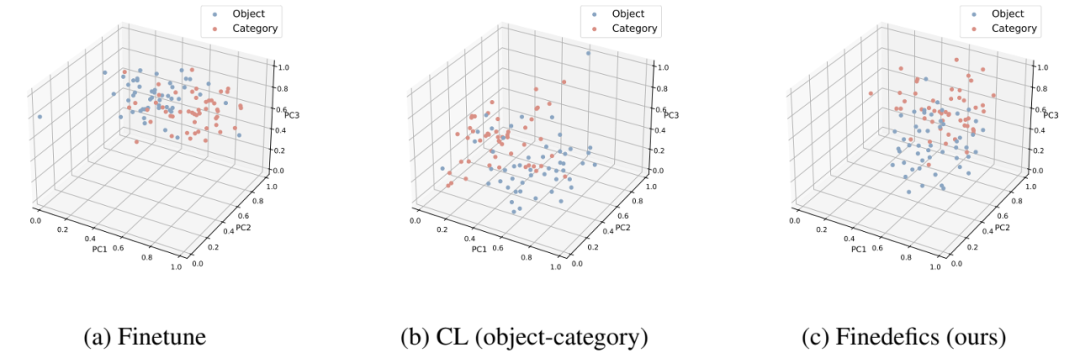
圖 3. 視覺對象 - 細粒度子類別對齊效果可視化

圖 4. 細粒度多模態(tài)大模型(Finedefics)案例展示
圖 3 的可視化結果表明,(a)僅微調大模型,視覺對象與細粒度子類別表征的分布差異大;(b)僅引入對象 - 類別對比學習時,上述分布差異仍然難以降低;(c)同時引入對象 - 屬性、屬性 - 類別、類別 - 類別對比學習時,分布差異顯著降低,優(yōu)化了視覺對象與細粒度子類別的對齊效果,提升了多模態(tài)大模型的細粒度視覺識別能力。
圖 4 的案例展示表明,相較于 Idefics2,本方法 Finedefics 能成功捕捉視覺對象特征的細微區(qū)別,并將其與相似的細粒度子類別對象顯著區(qū)分。
更多詳情,請參見原論文。