













Champ首發開源:人體視頻生成新SOTA,5天斬獲1k星,demo可玩
近日,由阿里、復旦大學、南京大學聯合發布的可控人體視頻生成工作 Champ 火爆全網。該模型僅開源 5 天 GitHub 即收獲 1k 星,在 Twitter 更是「火出圈」,吸引了大量博主二創,瀏覽量總量達到 300K。

目前 Champ 已經開源推理代碼與權重,用戶可以直接從 Github 上下載使用。官方 Hugging Face 的 Demo 已經上線,封裝的 Champ-ComfyUI 也正在同步推進中。GitHub 主頁顯示團隊將會在近期開源訓練代碼及數據集,感興趣的小伙伴可以持續關注項目動態。
- 項目主頁:https://fudan-generative-vision.github.io/champ/
- 論文鏈接:https://arxiv.org/abs/2403.14781
- Github 鏈接:https://github.com/fudan-generative-vision/champ
- Hugging Face 鏈接:https://huggingface.co/fudan-generative-ai/champ
先來看下 Champ 在真實世界人像上的視頻效果,以下圖左上角的動作視頻為輸入,Champ 能讓不同的人像「復制」相同的動作:

雖然 Champ 僅用真實的人體視頻訓練,但它在不同類型的圖像上展現了強大的泛化能力:

黑白照片,油畫,水彩畫等效果拔群,在不同文生圖模型生成的真實感圖像,虛擬人物也不在話下:

技術概覽
Champ 利用先進的人體網格恢復模型,從輸入的人體視頻中提取出對應的參數化三維人體網格模型 SMPL 序列(Skinned Multi-Person Linear Model),進一步從中渲染出對應的深度圖,法線圖,人體姿態與人體語義圖,作為對應的運動控制條件去指導視頻生成,將動作遷移到輸入的參考人像上,能夠顯著地提升人體運動視頻的質量,以及幾何和外觀一致性。
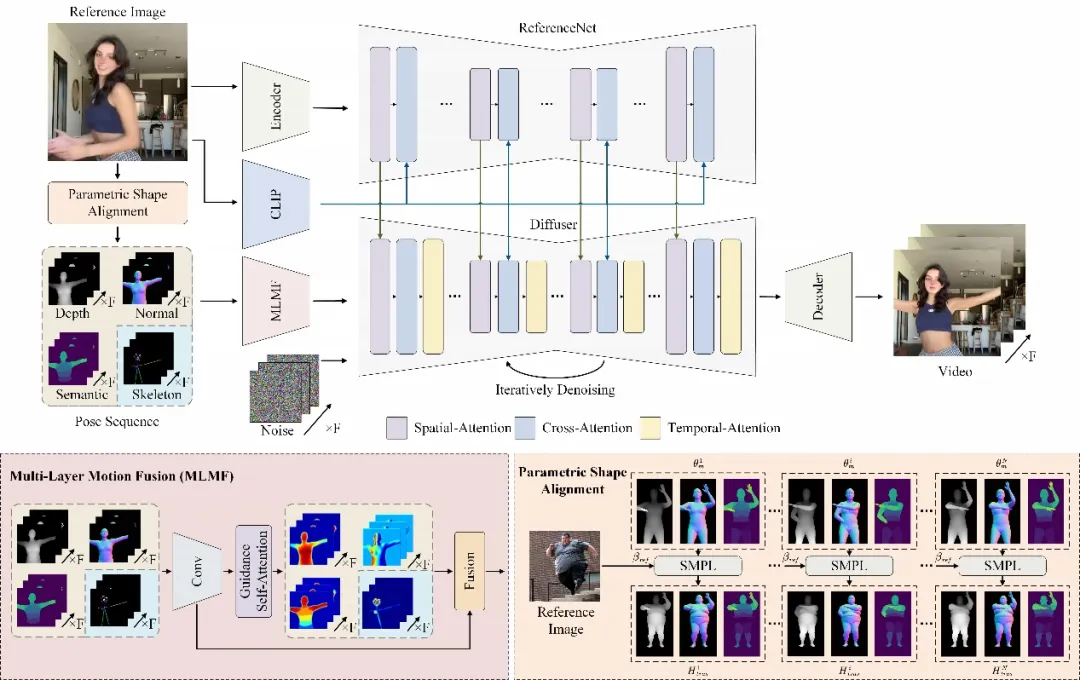
針對不同的運動條件,Champ 采用了一個多層運動融合模塊(MLMF),利用自注意力機制充分融合不同條件之間的特性,實現更為精細化的運動控制。下圖中展示了該模塊不同條件的注意力可視化結果:深度圖關注人物形態的幾何輪廓信息,法線圖指示了人體的朝向,語義圖控制人體不同的部分的外觀對應關系,而人體姿態骨架則僅關注于人臉與手部的關鍵點細節。

另一方面,Champ 發現并解決了人體視頻生成中一直被忽略的體型遷移的問題。此前的工作或是基于人體骨骼模型,或是基于輸入的視頻得到的其他幾何信息來驅動人像的運動,但這些方法都無法將運動與人體體型解耦,導致生成的結果無法與參考圖像的人體體型匹配。
例如,給定一個大胖作為參考圖像得到的如下圖 7 所示的對比結果:

可以看到,Animate Anyone 與 MagicAnimate 的生成結果中,大胖的大肚子被抹平,甚至骨架也有一些縮水。而 Champ 利用 SMPL 中體型參數,來將其與驅動視頻的 SMPL 序列進行參數化的體型對齊,從而在體型,動作上都取得了最佳的一致性(圖中 with PST)。
實驗結果
如下表 4 所示,與其他的 SOTA 工作相比,Champ 具有更好的運動控制以及更少的偽影:

同時,Champ 還展現了其優越的泛化性能與外觀匹配上的穩定性:

在 TikTok Dance 數據集,Champ 評估了圖像生成與視頻生成的量化效果,它在多個評估指標上均有較大的提升,如下表 1 所示。

更多技術細節以及實驗結果請參閱 Champ 原論文與代碼,也可在 HuggingFace 或下載官方源碼動手體驗。



























