英偉達開源福利:視頻生成、機器人都能用的SOTA tokenizer

在討論圖像、視頻生成模型時,人們的焦點更多地集中在模型所采用的架構,比如大名鼎鼎的 DiT。但其實,tokenizer 也是非常重要的組件。
谷歌等機構的研究者曾在一篇題為「Language model Beats diffusion - tokenizer is key to visual generation」的論文中證明,一個好的 tokenizer 接入到語言模型后,能夠立即獲得比當時最好的 diffusion 模型還要好的效果。論文作者蔣路在后來接受采訪時表示,「我們的研究可能會讓社區意識到 tokenizer 是被嚴重忽視的一個領域,值得發力去做」。
在圖像、視頻生成模型中,tokenizer 的核心作用是將連續的、高維的視覺數據(如圖像和視頻幀)轉換成模型可以處理的形式,即緊湊的語義 token,它的視覺表示能力對于模型的訓練和生成過程至關重要。就像上述論文作者所說,「tokenizer 的存在就是通過建立 token 之間的互聯,讓模型明確『我現在要做什么』,互聯建立得越好、LLM 模型越有機會發揮它的全部潛力。」

tokenizer 是生成式 AI 的關鍵組件,它通過無監督學習發現潛在空間,從而將原始數據轉換為高效的壓縮表示。視覺 tokenizer 專門將圖像和視頻等高維視覺數據轉化為緊湊的語義 token,從而實現高效的大型模型訓練,并降低推理的計算需求。圖中展示了一個視頻 token 化過程。
當前,業界有很多可用的開源視頻、圖像 tokenizer,但這些 tokenizer 經常生成質量不佳的數據表示,這會造成采用該 tokenizer 的模型生成失真的圖像、不穩定的視頻。此外,低效的 token 化過程還會導致編解碼速度變慢、訓練和推理時間變長,從而對開發人員的工作效率和用戶體驗產生負面影響。
為了解決這些問題,來自英偉達的研究者開源了一套名為 Cosmos 的全新 tokenizer。

- 研究地址:https://research.nvidia.com/labs/dir/cosmos-tokenizer/
- HuggingFace 地址:https://huggingface.co/collections/nvidia/cosmos-tokenizer-672b93023add81b66a8ff8e6
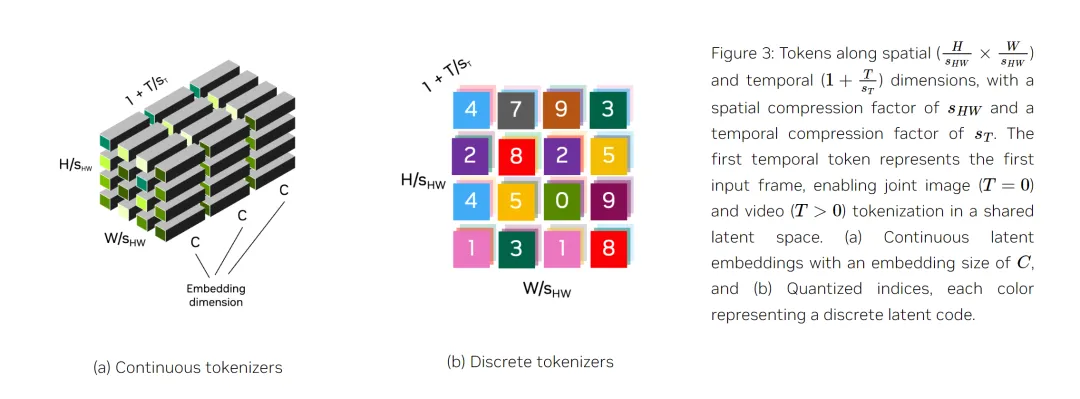
一般來說,tokenizer 有兩種類型:連續型和離散型。連續 tokenizer 將視覺數據映射為連續嵌入,適用于從連續分布中采樣的模型,如 Stable Diffusion。離散 tokenizer 將視覺數據映射為量化指數,適用于 VideoPoet 等依賴交叉熵損失進行訓練的模型,類似于 GPT 模型。下圖比較了這些 token 類型。
tokenizer 必須兼顧高壓縮和高質量,保留潛在空間的視覺細節。Cosmos tokenizer 是一套全面的連續和離散圖像和視頻視覺 tokenizer,可提供出色的壓縮和高質量重建,速度是以前方法的 12 倍。

如表 1 所示,它支持各種圖像和視頻類型,具有靈活的壓縮率,以適應不同的計算限制。

Cosmos tokenizer 基于輕量級時間因果架構,使用因果時間卷積和注意力層來保持視頻幀的順序。這種統一的設計允許對圖像和視頻進行無縫 token 化。
英偉達的研究者在高分辨率圖像和長視頻上訓練 Cosmos tokenizer,涵蓋不同類別數據的寬高比(包括 1:1、3:4、4:3、9:16 和 16:9)。在推理過程中,它不受時間長度的影響,可以處理比訓練時間更長的數據。

- GitHub 地址:https://github.com/NVIDIA/Cosmos-Tokenizer
研究者在標準數據集(包括 MS-COCO 2017、ImageNet-1K、FFHQ、CelebA-HQ 和 DAVIS)上對 Cosmos tokenizer 進行了評估。為了使視頻 tokenizer 評估標準化,他們還策劃了一個名為 TokenBench 的新數據集,涵蓋機器人、駕駛和體育等類別,并在 GitHub 上公開發布。

- TokenBench 地址:https://github.com/NVlabs/TokenBench
結果(圖 1)顯示,Cosmos tokenizer 明顯優于現有方法,在 DAVIS 視頻上的 PSNR 提升了 4 dB。它的 token 化速度是以前方法的 12 倍,并能在配備 80GB 內存的英偉達 A100 GPU 上編碼長達 8 秒的 1080p 和 10 秒的 720p 視頻。空間壓縮率為 8 倍和 16 倍、時間壓縮率為 4 倍和 8 倍的預訓練模型可在 GitHub 上獲取。

試用過 Cosmos 的 1x 機器人公司 AI 副總裁 Eric Jang 表示,Cosmos 是一個非常好的 tokenizer,比根據他們自己的數據進行微調的 Magvit2 好得多。看來,這個新工具值得一試。

以下是 Cosmos 的一些技術細節。
Cosmos tokenizer 架構
Cosmos tokenizer 采用復雜的編碼器 - 解碼器結構,旨在實現高效率和高效學習。其核心是采用 3D 因果卷積塊,這是聯合處理時空信息的專門層,并利用因果時間注意力捕捉數據中的長程依賴關系。
因果結構確保模型在進行 token 化時只使用過去和現在的幀,而避免使用未來幀。這對于與許多真實世界系統的因果性質保持一致至關重要,例如物理 AI 或多模態 LLM 中的系統。

Cosmos tokenizer 架構圖。
使用 3D wavelet 對輸入進行降采樣,這種信號處理技術能更有效地表示像素信息。數據處理完成后,通過反向 wavelet 變換重建原始輸入。
這種方法提高了學習效率,使 tokenizer 編碼器 - 解碼器可學習模塊專注于有意義的特征,而不是多余的像素細節。這些技術與其獨特的訓練方法相結合,使 Cosmos tokenizer 成為了一個高效、強大的架構。
實驗結果
定性結果
圖 6 顯示了使用連續視頻 tokenizer 重建的視頻幀。

圖 9 顯示了使用不同離散圖像 tokenizer 重建的圖像。

圖 8 則顯示了連續圖像 tokenizer 的誤差圖,以突出重建差異。與之前的方法相比,Cosmos tokenizer 能更有效地保留結構和高頻細節(如草地、樹枝、文本),同時將視覺失真(如人臉、文本)和偽影降到最低。

這些定性結果表明,Cosmos tokenizer 能夠編碼和解碼各種視覺內容,并有能力保持圖像和視頻的最高視覺質量。
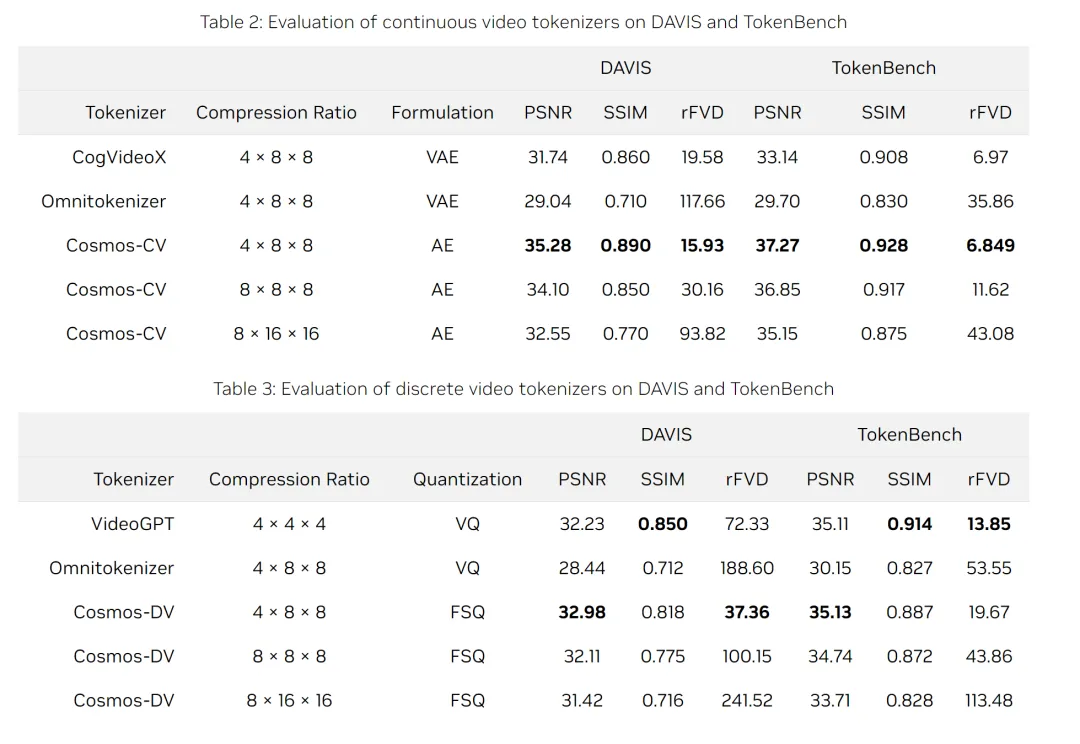
定量結果
表 2 和表 3 列出了連續和離散視頻 tokenizer 在各種基準上的平均定量指標。Cosmos tokenizer 在 4×8×8 壓縮率的 DAVIS 和 TokenBench 數據集上都達到了 SOTA 性能。即使在更高的壓縮率(8×8×8 和 8×16×16)下,Cosmos tokenizer 的性能也優于以前的方法,顯示了出色的壓縮質量權衡。