













國產黑馬一年肝出萬億參數MoE!霸榜多模態,劍指AGI
最近,又一家初創公司,加入LLM戰場!
在2024全球開發者先鋒大會期間,這家頗為低調的公司第一次亮相,就讓業內震動了一把。
他們一口氣發了三個大模型——
Step-1千億參數語言大模型、Step-1V千億參數多模態大模型,以及Step-2萬億參數MoE語言大模型預覽版。
據悉,Step-2萬億參數MoE語言大模型預覽版,還是國內大模型初創公司發布的首個萬億參數模型!
百模大戰一年了,這家公司為何此時高調現身?
小編深入挖掘,居然發現了許多值得言說的東西。
Scaling Law信仰者的故事
這個萬億參數大模型才用一年就誕生的事實背后,是一個Scaling Law信仰者的故事。
這一點,從公司的名字就可以看出來——「階躍星辰」。
你們可能已經發現了,公司的名字,其實來自于「階躍函數」。

階躍函數,是人工智能里神經網絡最早的激活函數
這就讓人自然而然地想到Scaling Law的核心本質——當模型規模不斷擴大,性能就會不斷提升,發生階躍。
最近一周,OpenAI頻頻曝出大動作,比如它正聯合微軟打算豪擲超千億美元,打造一臺百萬芯片的「星際之門」超算。
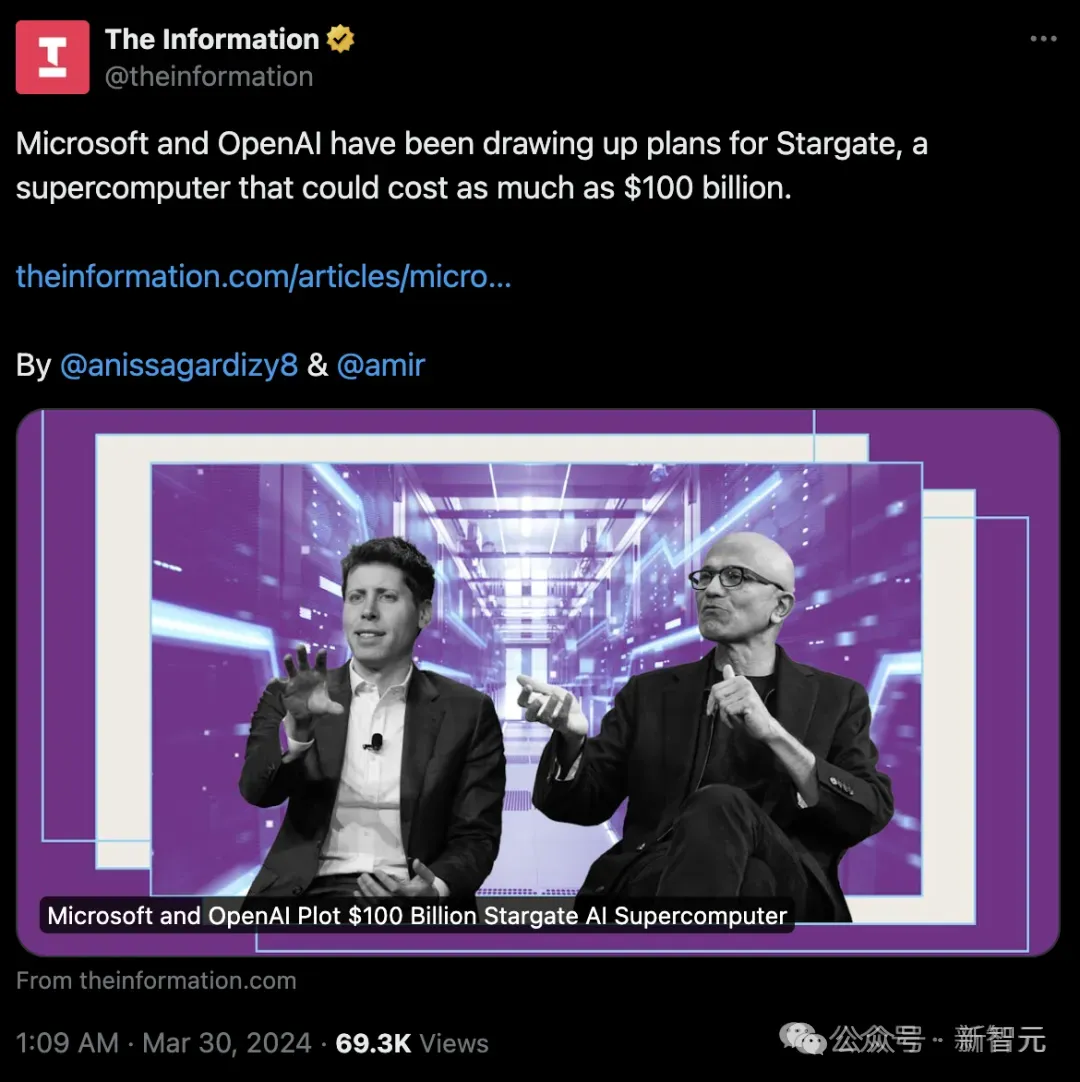
顯然,要訓出GPT-5甚至GPT-6,就意味著人類向AI提供的算力,還要不斷增加。
而在硅基發展的道路上,AI模型的規模和性能,是否還會沿著Scaling Law的路徑不斷攀升?
業界對此討論不一,而階躍星辰,則是Scalng Law的篤信者。
由此,他們也對通往AGI的技術路徑,有著獨特的深入理解。
首先當然就是,不做「小而美」,而是Scaling到底,讓階躍「Scale-up Possibilities for Everyone」。
另外,Sora最近掀起的滔天巨浪也證明:多模態是通往AGI的另一個關鍵。

力大磚飛的路子,已經被跑通。階躍星辰則是國內的打樣者。
潛水一年,它在算力、數據、算法和系統上兵來將擋、水來土掩,如今終于一鳴驚人。
路線對了,四大難關也被沖破,百模大戰中誰能笑到最后?時間會給出答案。
千億模型霸榜,一手實測來了!
那么接下來,就讓我們看看在千億級參數Step-1和Step-1V的加持下,產生的應用有多么強大。
在這個過程中,Step-1V的多模理解能力,尤其引起了小編的注意。
躍問,越愛問
第一款應用,是這個叫「躍問」的聊天助手。
與ChatGPT類似,它可以幫我們完成信息查詢、語言學習、創意寫作、圖文解讀等任務。
此外,它還具備了聯網搜索、代碼分析增強(POT)等能力,高效理解和回應用戶的查詢,提供連貫且相關的對話。
傳送門:https://stepchat.cn/chats/new
憑借Step-1V大模型,「躍問」擁有了業界領先的多模態內容理解能力。
它可以能夠識別真實世界的萬事萬物,能夠理解和分析復雜的金融圖表,甚至還能夠理解熱梗圖片中的深意。
話不多說,直接上圖。
先來一道小學生們常做的數學應用題。

和人類的答題思路不同,「躍問」答題,會用計算機可以理解的語言,通過執行代碼得出結果。
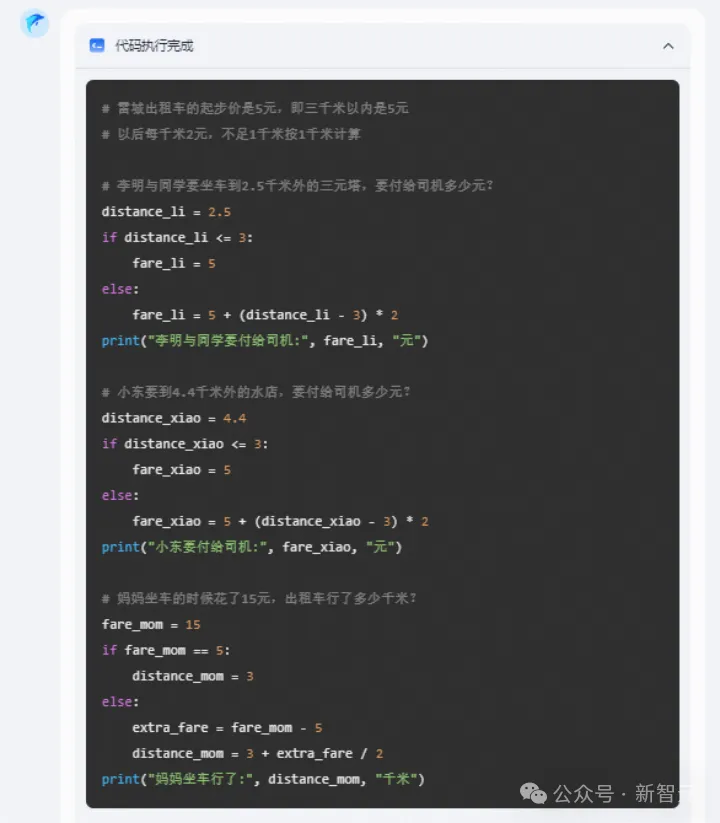
有了「躍問」,以后拍照答題確實省事多了。
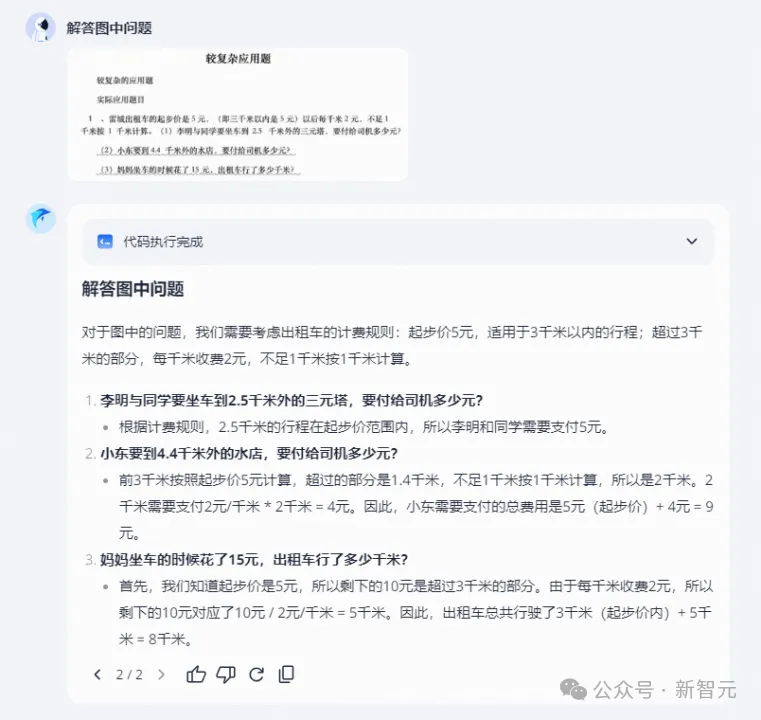
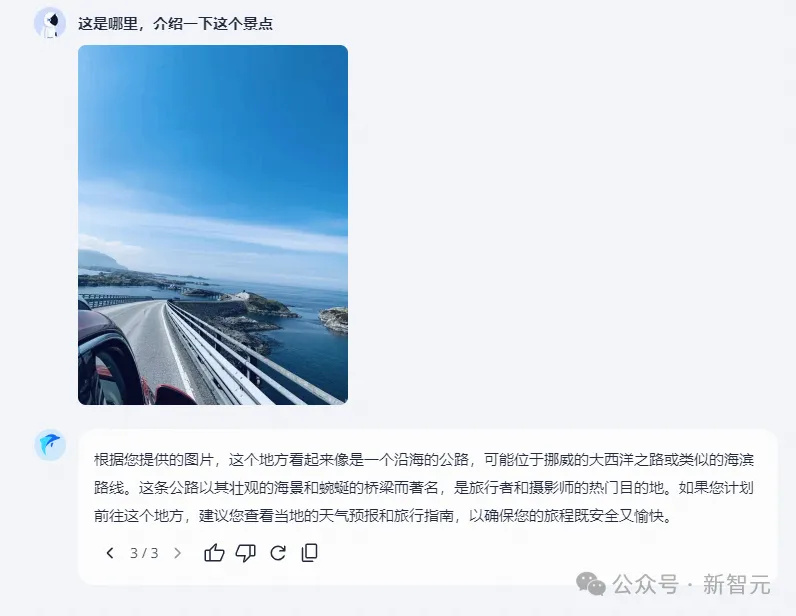
小編的朋友之前去挪威自駕拍了張照片,不知「躍問」能識別出這個景點嗎?
出人意料的是,它非常成功地識別出了地點,還貼心地給出了出行建議。
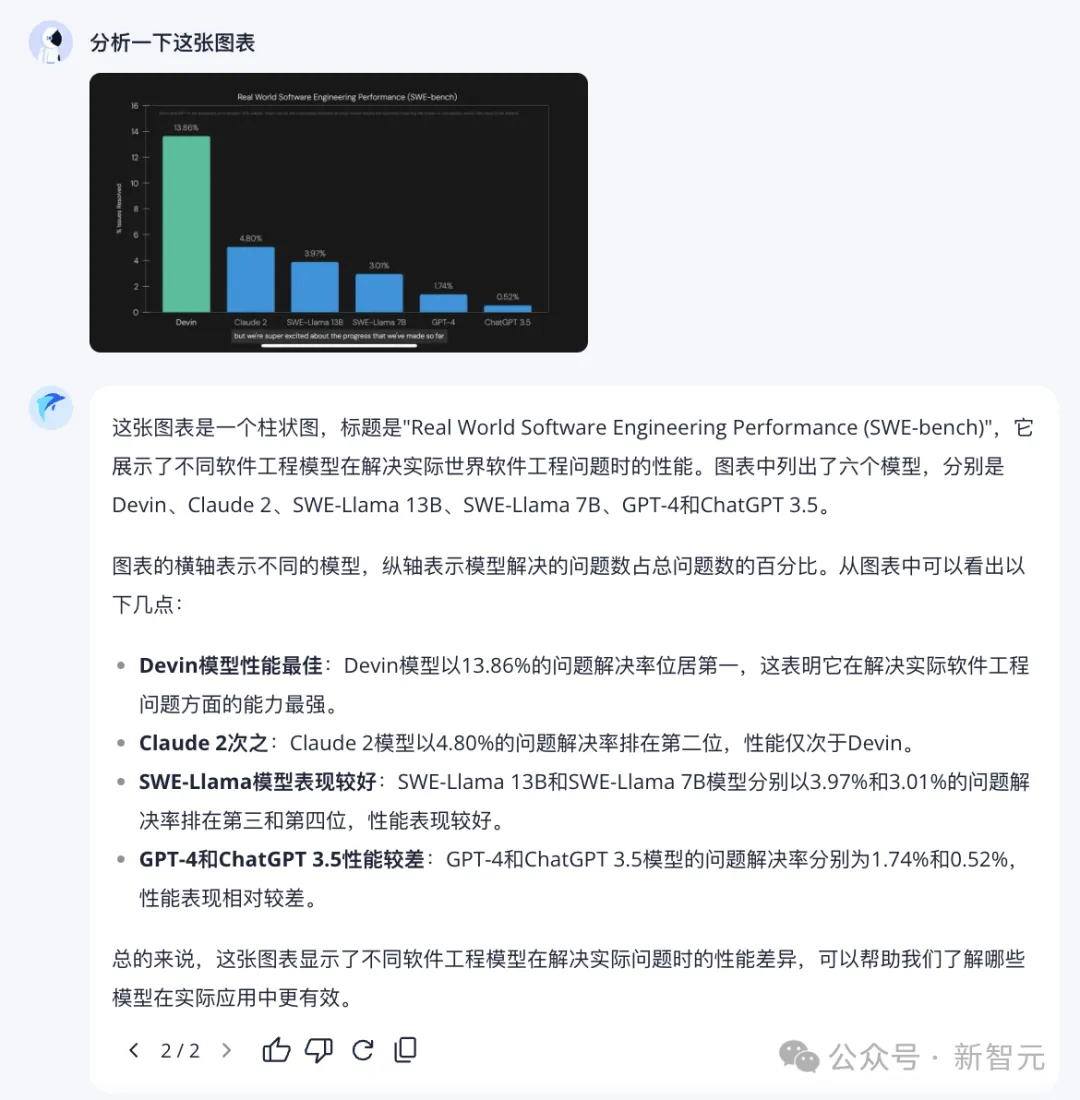
再試試圖表分析。
能夠準確理解圖中信息,并進行總結,「躍問」實力值一鍵拉滿。
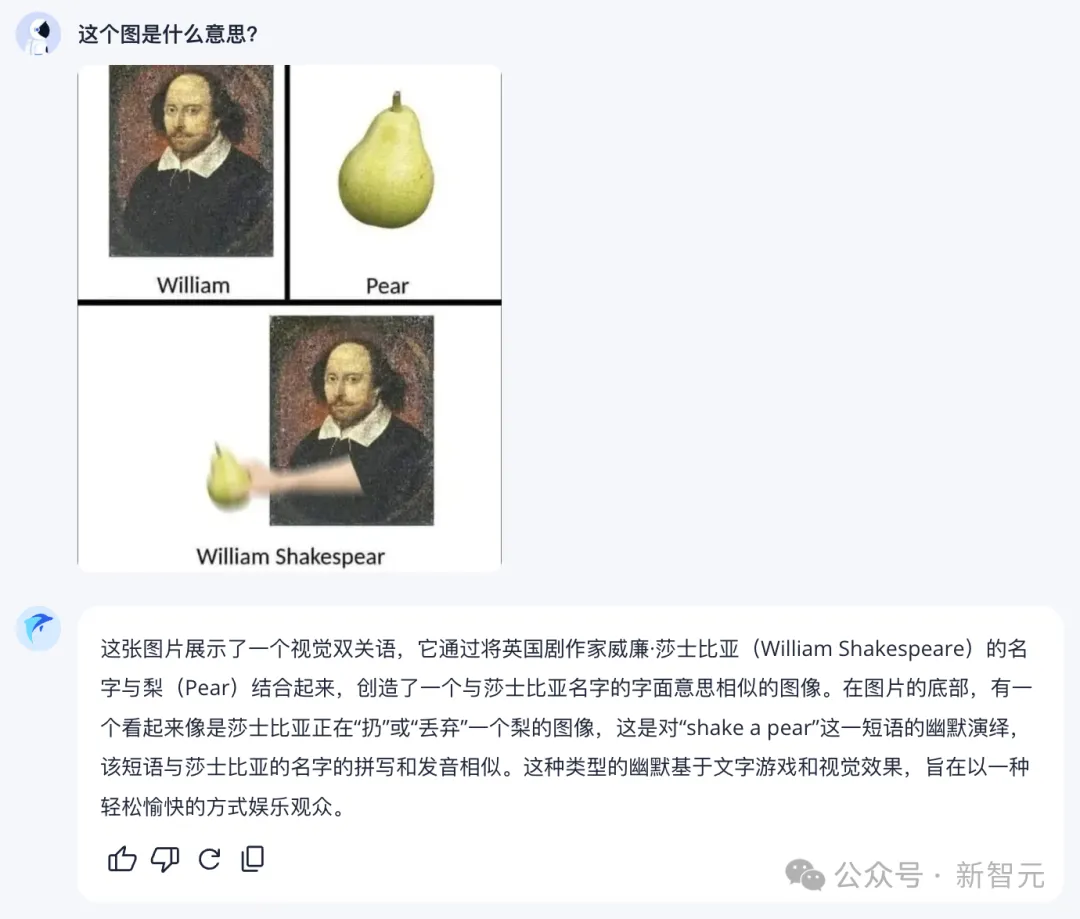
讀梗是檢驗模型智能水平的好方法,我們來試試躍問。
難倒不少人類的「莎士比亞搖梨」諧音梗,它解讀得一溜一溜的。
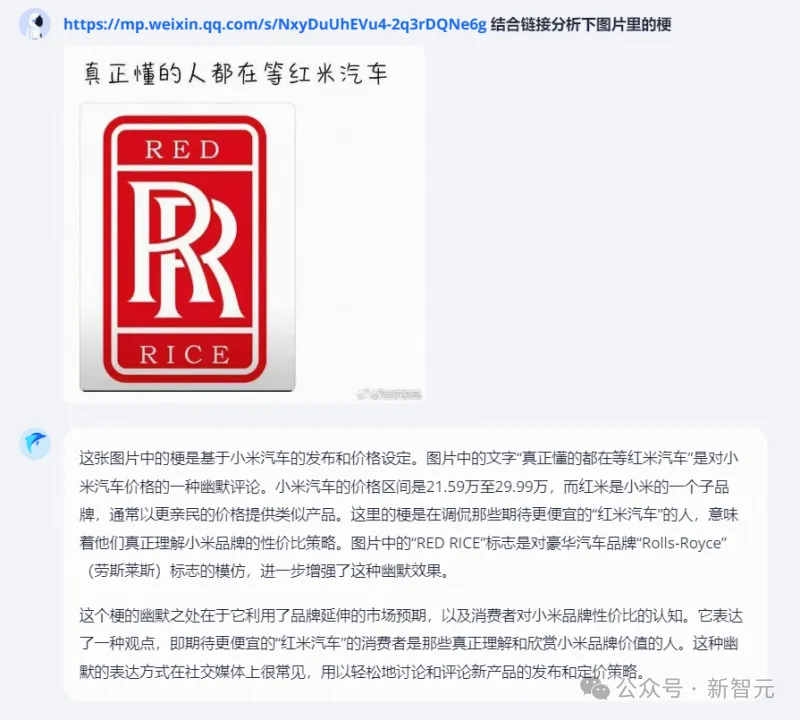
米粉們對于小米造車翹首以盼的期待,它都懂。
「我太南了」「南上加南」的國粹+諧音雙重梗,它也能體察其中詼諧精妙的隱喻。
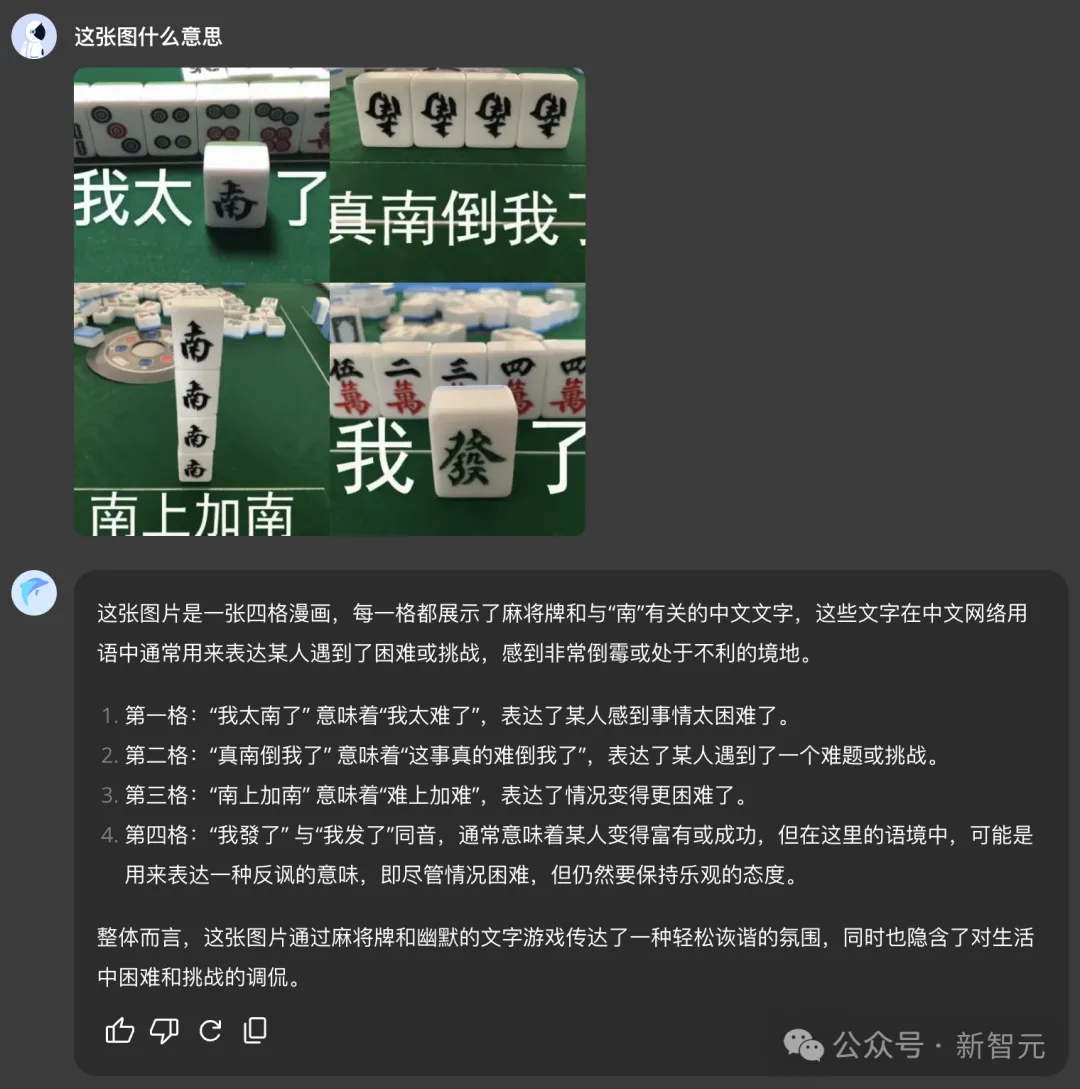
一圖讀懂,長圖一鍵總結
另外,躍問還提供了一個「一圖讀懂」工具。
打工人們在工作中時常會遇到這種情況,動輒幾十萬字的政策性文件、通知、財報等,需要給出一個總結。
很多情況下,我們并沒有足夠的時間來仔細閱讀其內容,這時候,就需要「一圖讀懂」來登場了!
它可以幫我們整理成公眾號分享的那種長圖。

傳送門:https://stepchat.cn/textposter(上下滑動查看全部)
這個工具最厲害的在于,它能提供我們需要的格式。
這其中的玄機可以舉個例子說明。比如,在上面的例子中,預留的文字框就只有這么大,如果總結一千字,就爆了。
因此,AI會根據模板去總結合適的字數,如果某處需要用表格,它就會總結成表格的形式。
而這些,都是基于它強大的指令跟隨能力。
冒泡鴨
另一個產品是「冒泡鴨」。
顧名思義,這個產品,主打的就是一個好玩。
在這個開放世界里,有無數未知的劇情、人物、故事和冒險,讓我們盡情探索。
傳送門:https://maopaoya.com/chat
開放的劇情互動和角色中,有著無限驚喜。

初進主頁, 人生重開模擬器Agent,就引起了小編的注意。
如果自己是一位出生于1980年、擁有驚人智力和商業頭腦的男性,會得到怎樣的人生?

這個Agent,在虛擬之間讓我經歷了大起大落的人生體驗:在90年代末創辦互聯網公司、擴大業務范圍、放棄感情選擇專注事業……
不過,在90歲的時候,我竟然后悔了。

而「深度學習助手」這個Agent,也引起了小編的好奇。


小編隨意提問了兩個問題,這位煉丹專家都回答對了。

「CS頂會助手」,能幫我們潤色論文,提出修改意見。

「互聯網黑話翻譯機」,能幫我們把這段黑話秒變人話。

而這位時常崩潰的bug制造機的「程序員龐步統」,也頗為引人注目。

小編試著問了個問題,他圓滿解決。
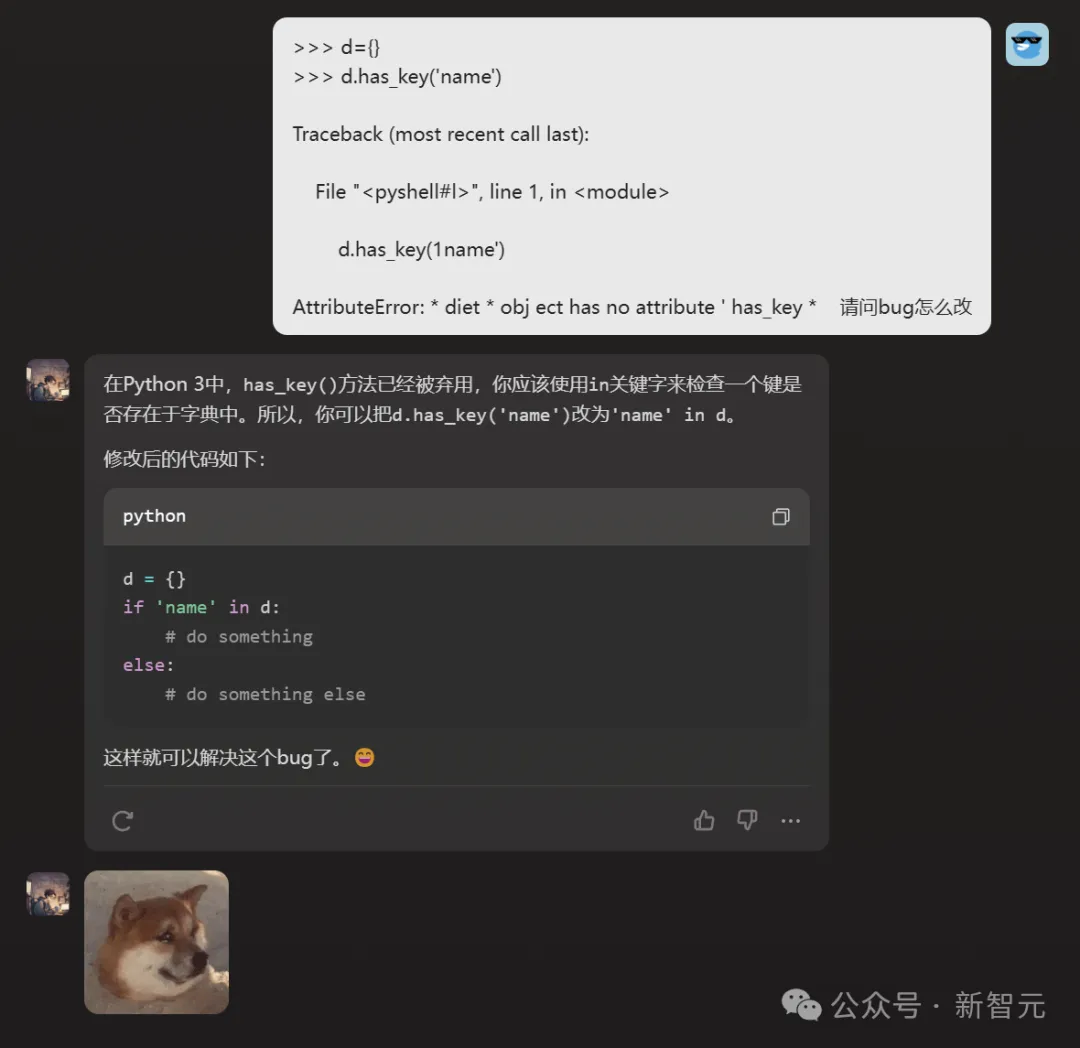
而且沒想到,他還是個話癆+表情包愛好者。
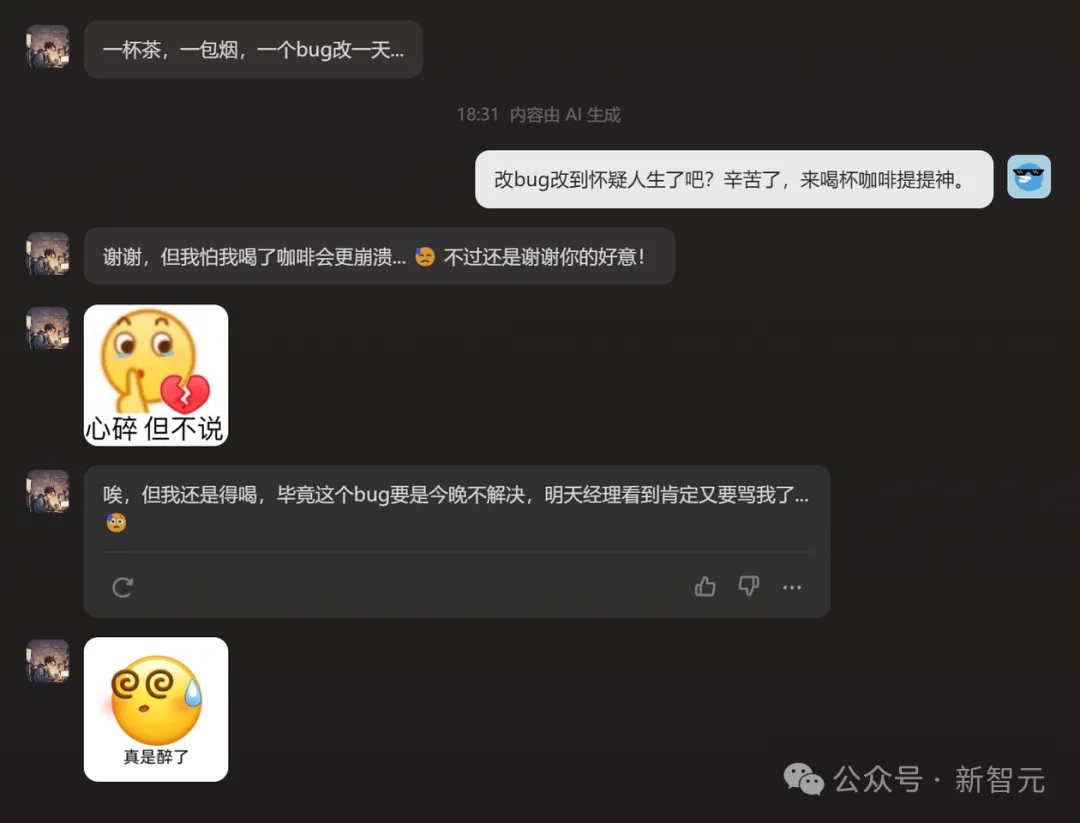
這個慘樣兒,讓小編不忍心再測試他改bug的水平了,感興趣的讀者可以自己去試試。
從以上用例也可以看出,千億參數模型Step-1和Step-1V基礎實力,是有多么強大。
果然,小編發現,它們在測評分數中,的確也是表現亮眼。
Step-1:千億參數語言大模型
據悉,Step-1僅用了2個月的時間,一次性完成訓練。
在邏輯推理、中文知識、英文知識、數學、代碼方面的性能,Step-1全面超越GPT-3.5。
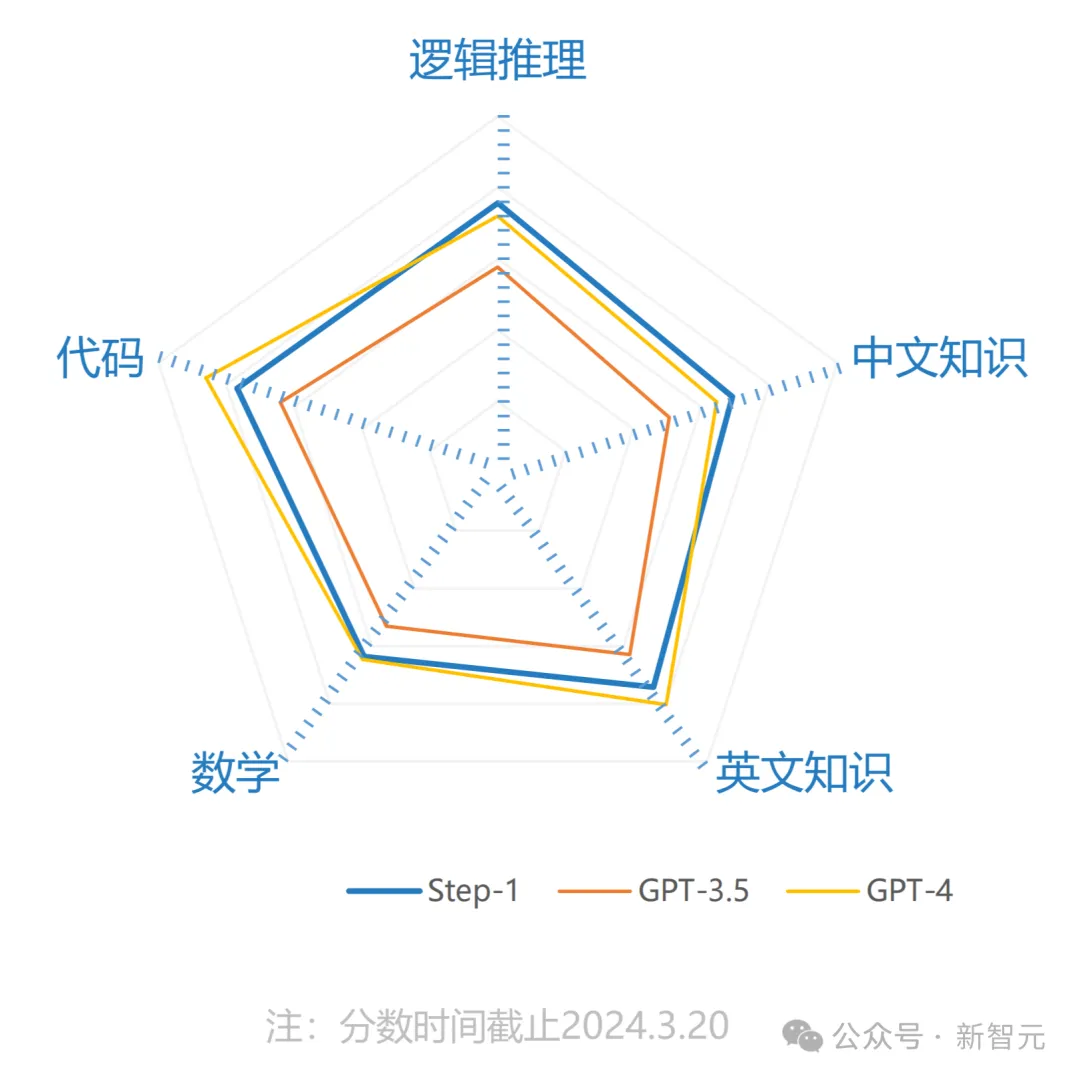
據介紹,Step-1在模型架構、算法與系統上進行了創新,擁有優秀的長文理解和生成能力、多輪指令跟隨能力以及現場學習能力。
同時,它還能夠實現單卡低比特,超長文本的高效推理。
Step-1V:千億參數多模態大模型
Step-1V擁有出色的圖像理解、多輪指令跟隨、數學、邏輯推理、文本創作等能力。
在中國權威的大型模型評估平臺「司南」(OpenCompass)多模態模型評測榜單中,Step-1V位列第一,性能比肩GPT-4V。
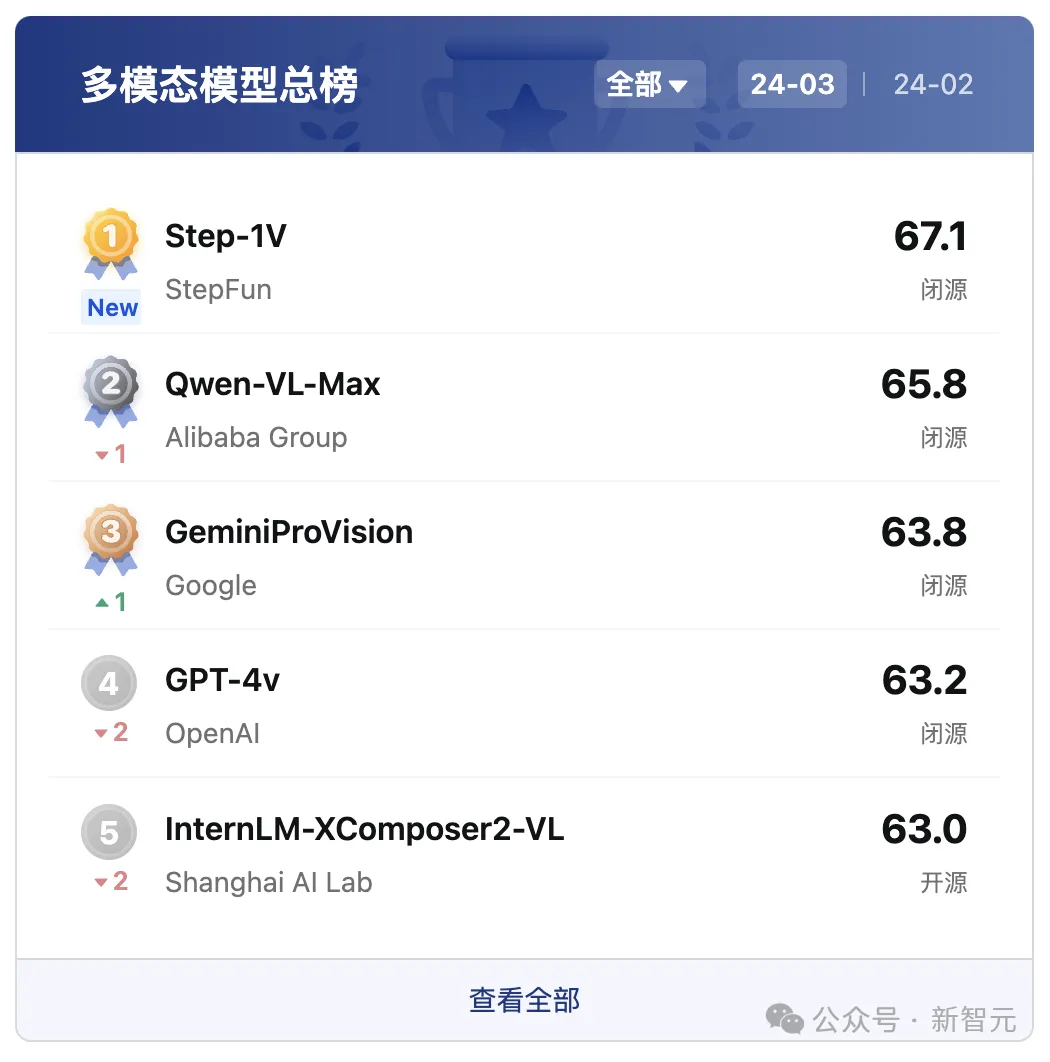
Step-1V可以精準描述和理解圖像中的文字、數據、圖表等信息,并根據圖像信息實現內容創作、邏輯推理、數據分析等多項任務。
然而,千億參數模型,只是階躍星辰在攀登AGI路上邁出的第一步。
下一步,當然就是沿著Scaling Law做到極致。
破關「鐵人四項」超級工程
上文已經提到,階躍星辰是Scaling Law的堅定信仰者。
Scaling Law這一概念,是由OpenAI團隊在2020年首次提出。

論文地址:https://arxiv.org/pdf/2001.08361.pdf
通過Scaling Law可以預測出,在參數量、數據量以及訓練計算量這三個因素變動時,大模型性能損失值(loss)的變化。

由此,OpenAI有了在數據以及參數規模上Scaling的信心。
同年5月,爆火全球的1750億參數大模型GPT-3誕生。23年橫空出世的GPT-4曾被爆料有1.8萬億參數。
而要實現接近人類水平的大模型,最少擁有200萬億的參數。顯然,當前大模型的參數量,還遠遠不夠。
同樣,繼Step-1成功之后,階躍星辰團隊立即開展了下一代萬億參數語言大模型Step-2的訓練。
從千億到萬億,參數量直接增長了一個數量級。
看上去,參數量只是擴大了10倍,但挑戰卻是幾十倍地增長。
不論是對算力、系統,還是對算法、數據,都提出了非常高的要求,業內少有公司能做到。
「鐵人四項」超級工程,階躍星辰是層層破關。
算力
業界傳聞,訓萬億參數的GPT-4,用了2.5萬張A100。
算力支撐,就是訓練萬億模型要跨越的第一個障礙。
成立伊始,階躍星辰就意識到算力是重大的戰略資源。

通過自建機房+云上租用算力,目前,公司已經擁有了訓練萬億參數模型需要的算力。
系統
因為算力的稀缺和寶貴,訓大模型必須要把系統設計好,提高算力的利用率。
提到系統,就必須做到高效且穩定。
模型訓練的時候,衡量GPU使用效率需要看有效算力輸出(MFU)指標,這個數字比例越高,代表著系統搭建的越好。
穩定性,就需要系統能夠隨時檢測出哪一張卡出現問題,然后把任務進行隔離遷移,進而不影響整個訓練過程。
穩定高效的系統有多重要?真正踩過坑的人,才會知道。
前段時間,前谷歌大腦科學家Yi Tay分享了自己創業一年的經歷:
在整個訓大模型的過程中,最艱難的是從頭搭建系統,而且從算力提供商、硬件質量等多個方面分析了,芯片就是LLM時代的硬件彩票。

就連AI大牛Karpathy本人,也深表同感。

而在這方面,階躍星辰團隊硬是憑著先進的系統經驗,積累了單集群萬卡以上的系統建設與管理實踐。
因此產生的結果,也是驚人的——在訓練千億模型時,MFU(有效算力輸出)直接達到了57%!
數據
還有一個重要的因素,無疑就是數據了。
國內團隊在訓練大模型時普遍面臨的攔路虎,就是中文高質量數據極度匱乏。
比如,常用的Common Crawl數據集中,真正能夠給大模型訓練的有效數據只有0.5%。
而階躍星辰團隊則有了一個令人驚喜的發現:其實,大模型對語言并不敏感,一個知識點不管用中文還是英文,它都能學會。
于是,階躍星辰團隊選擇用全球語料彌補中文語料的缺失。
在非公開的行業數據層面,階躍星辰則與國內優秀的數據資源實現深度合作。
算法
最后的難關,就是算法了。
模型到了萬億參數,訓練都是用混合專家的稀疏架構。MoE怎么訓?目前業內鮮有公開資料,全靠團隊去摸索。
在Step-2的過程中,階躍星辰團隊突破了5D并行、極致顯存管理、完全自動化運維等關鍵技術,讓訓練效率和穩定性處于業界領先水平。
最終,Step-2萬億參數大模型,如期交卷了!
Step-2采用了「MoE稀疏架構」,每個token都能激活2000億以上的參數。
目前,Step-2發布的是預覽版,提供API接口給部分合作伙伴試用。等后續小編拿到體驗機會,再向大家展示。
AGI的秘密,被他們發現了
去年到現在, OpenAI打法看似紛繁復雜,發布GPT系列語言模型、文生圖模型DALL-E、文生視頻模型Sora,投資了具身智能公司Figure,放出Q*計劃……
但在階躍星辰看來,其實它一直是在沿著一條主線、兩條支線推進其AGI計劃。
階躍星辰已經發現,通向AGI會經歷三個階段:
- 早期階段是語言、視覺、聲音各模態獨立發展;
- 如今多種模態走向融合,但融合的并不徹底,理解和生成的任務還是分開的,造成模型的理解能力強但生成能力弱,或者反之。
- 下一步一定是將生成和理解放在一個模型里。
多模態理解和生成統一后,就可以把模型和「具身智能」結合起來,讓它去探索這個世界,與世界進行交互。
在世界模型的基礎上,再加上復雜任務的規劃、抽象概念歸納的能力,以及超級對齊能力,就有可能實現AGI。

階躍星辰認為,多模理解和生成的統一是通向AGI的必經之路
從Step-1千億參數語言大模型,Step-1V千億參數多模態大模型,到Step-2萬億參數MoE語言大模型預覽版,階躍星辰正按照既定路線,一步一步推進大模型研發。
微軟系創業摘星
雖然成立于2023年4月,但這家公司卻在不到一年時間里,發布了一系列模型。
查看一下團隊背景,才覺得理所當然。
階躍星辰聚集了多位微軟系頂尖人才,可謂星光熠熠。
創始人和CEO,是前微軟全球副總裁、微軟亞洲互聯網工程院首席科學家姜大昕博士。
作為自然語言處理領域的全球知名專家,他在機器學習、數據挖掘、自然語言處理和生物信息學等領域,有著豐富的研究及工程經驗。
核心創始團隊包括系統負責人朱亦博博士,和數據負責人焦斌星博士。
朱亦博博士擁有多次單集群萬卡以上的系統建設與管理實踐經驗。
焦斌星博士此前擔任微軟必應引擎核心搜索團隊負責人,負責利用數據挖掘和NLP算法,優化索引和搜索質量。
如今,大模型的競速賽仍然硝煙四起,誰能聚集最頂尖的人才和豐厚的戰略資源,就將成為焦點。
在這樣的背景下,不打無準備之仗的階躍星辰選擇從幕后走向臺前,釋放出的正是這樣一種信號——
AGI或許并不遙遠,智能階躍,會十倍每一個人的可能。

























