













從零開始手搓GPU,照著英偉達CUDA來,只用兩個星期
「我花兩周時間零經驗從頭開始構建 GPU,這可比想象的要難多了。」

總有人說老黃的芯片供不應求,大家恨不得去手搓 GPU,現在真的有人試了。
近日,美國一家 web3 開發公司的創始工程師之一 Adam Majmudar 分享了他「手搓 GPU」成功的經歷,引發了網友們的一大片點贊。令人驚訝的是,他僅用兩周時間就完成了這一腦力壯舉。在 Twitter/X 的主題帖子中,Majmudar 進行了直播,一步步帶我們回顧了整個過程。

自造 GPU 的實踐當然也被公開在 GitHub 上,現在這個項目已有 5300 的 Star 量了。

項目鏈接:https://github.com/adam-maj/tiny-gpu
需要明確的是,該項目目前的節點是在 Verilog 中的芯片布局,最終通過 OpenLane EDA 軟件進行了驗證。在這之后,GPU 還將通過 Tiny Tapeout 7 提交流片,因此注定會在未來幾個月內成為物理形態的芯片。

Majmudar 詳細列出了設計 GPU 所完成的任務流程。顯然,作為一個「從頭開始」的項目,在試探性邁出第一步之前就需要進行大量的研究和思考。由于專有技術的主導地位,GPU 是一個相對復雜的研究領域,想想就難,實踐起來更難。
手搓 GPU 要分幾步?
實際上對于 Majmudar 來說,操作比這個步驟還要多,因為他真的沒啥技術基礎,是從學習 GPU 架構的基礎知識開始的。
他首先開始嘗試通過學習英偉達的 CUDA 框架來理解 GPU 軟件模式,進而理解了用于編寫 GPU 程序(稱為內核)的相同指令多數據 (SIMD) 編程模式。
有了這些背景,Majmudar 開始深入學習 GPU 的核心元素:從全局內存、計算核心、分層緩存、內存控制器到程序調度。
然后在每個計算核心中,我們還要了解其中的主要單元:包括寄存器、本地 / 共享內存、加載存儲單元 (LSU) 、計算單元 、調度程序、獲取器和解碼器。

好了,你已經是一個了解了現代 GPU 架構的人了,下面讓我們來手搓一塊 GPU 吧。
此處 Majmudar 表示,由于復雜性如此之高,我們必須將 GPU 簡化到新手能夠設計的水平,否則項目就工期爆炸了。
接下來就是創建一個自己的 GPU 架構。我們的目標是創造一個最小的 GPU 來突出 GPU 的核心概念,并消除不必要的復雜性,以便其他人可以更輕松地了解 GPU。
Majmudar 表示,設計自己的 GPU 架構是一項令人難以置信的實踐。
他一邊學習一邊操作,隨后決定在設計中強調以下幾點:
- 并行化 - 在硬件中實現 SIMD 模式;
- 內存訪問 - 觀察 GPU 如何應對從緩慢且帶寬有限的內存訪問大量數據的挑戰;
- 資源管理 - 最大限度提高資源利用率和效率。
通過對上述架構的多次迭代,Majmudar 決定專注于通用并行計算 (GPGPU) 功能,面向機器學習(machine learning)的更廣泛用例。
設計稱得上緊跟時代。
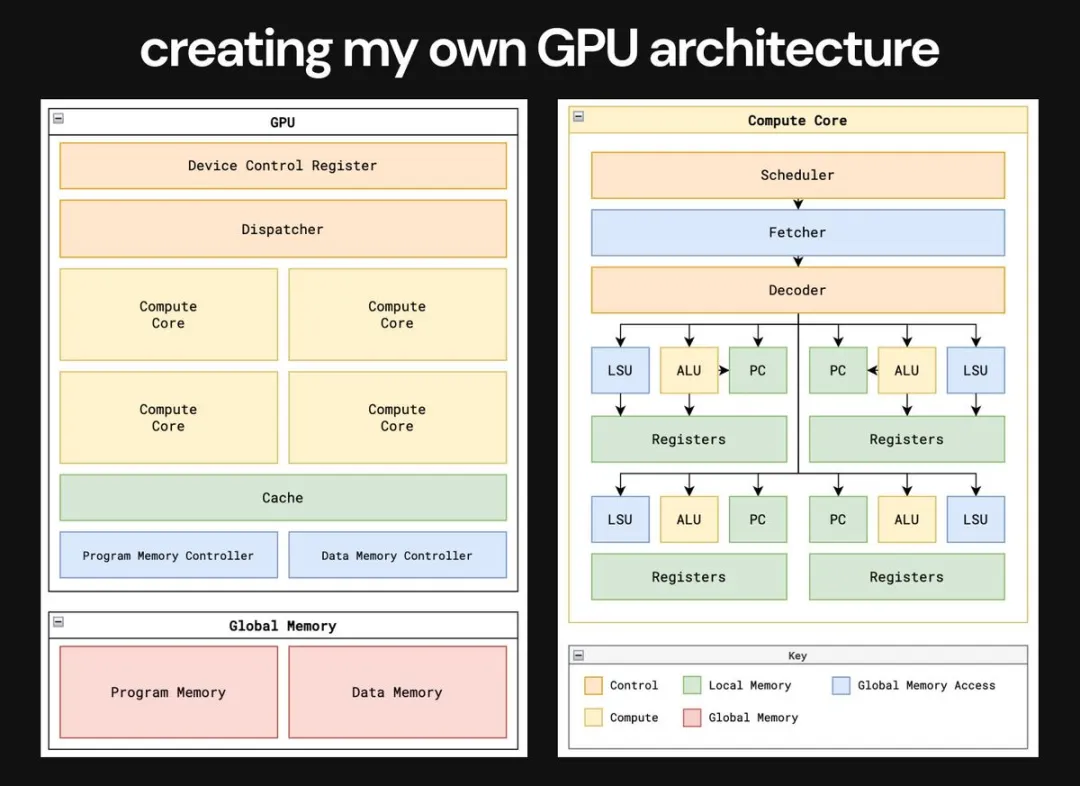
這里的一切都是最簡單的形式。
第三步是為這塊 GPU 編寫自定義的匯編語言。
Majmudar 表示,其中一個最關鍵的因素是他 GPU 實際上可以執行用 SIMD 編程模式編寫的內核。為了實現這一點,就必須為 GPU 設計自己的指令集架構(ISA),以便用來編寫內核。他制作了自己的 11 條小型指令 ISA,該 ISA 受到 LC4 ISA 的啟發。在這之后,他又編寫一些簡單的矩陣數學內核作為概念證明。

這是 Adam Majmudar 提出的 ISA 的完整表格,其中包括每條指令的確切結構。
接下來,Majmudar 編寫了兩個在其 GPU 上運行的矩陣數學內核。這些矩陣加法和乘法內核將演示 GPU 的關鍵功能,并提供其在圖形和機器學習任務中應用有效的證據。

為矩陣加法和乘法編寫的內核。
Majmudar 用 Verilog 構建 GPU 帶來了許多問題。這是最困難的部分,學會了很多知識,但也多次重寫了代碼。值得一提的是,Majmudar 得到了 George Hotz 的建議與幫助。
最初,他將全局內存實現為 SRAM,大佬給出的反饋說這違背了構建 GPU 的整個目的 ——GPU 的最大設計挑戰是管理訪問有限帶寬的異步內存(DRAM)延遲。
因此,Majmudar 最終使用外部異步內存重建了設計,并最終意識到還需要添加內存控制器。
其次,Majmudar 一開始是用 warp-scheduler 來實現 GPU 的,這是一個很大的錯誤,對于該項目來說太復雜且沒有必要。還好 George Hotz 及時提出了反饋。當一開始收到反饋時,Majmudar 甚至沒有足夠的背景知識來完全理解它,所以花了很多時間嘗試構建一個 Warp 調度程序,這才醒悟過來。
這還沒有完,一開始的設計中,Majmudar 沒有在每個計算核心內正確實現調度,因此不得不回過頭,分階段設計計算核心執行以獲得正確的控制流。
最終,Majmudar 對代碼的第三次重寫實現了目標,修復了計算核心的執行調度。
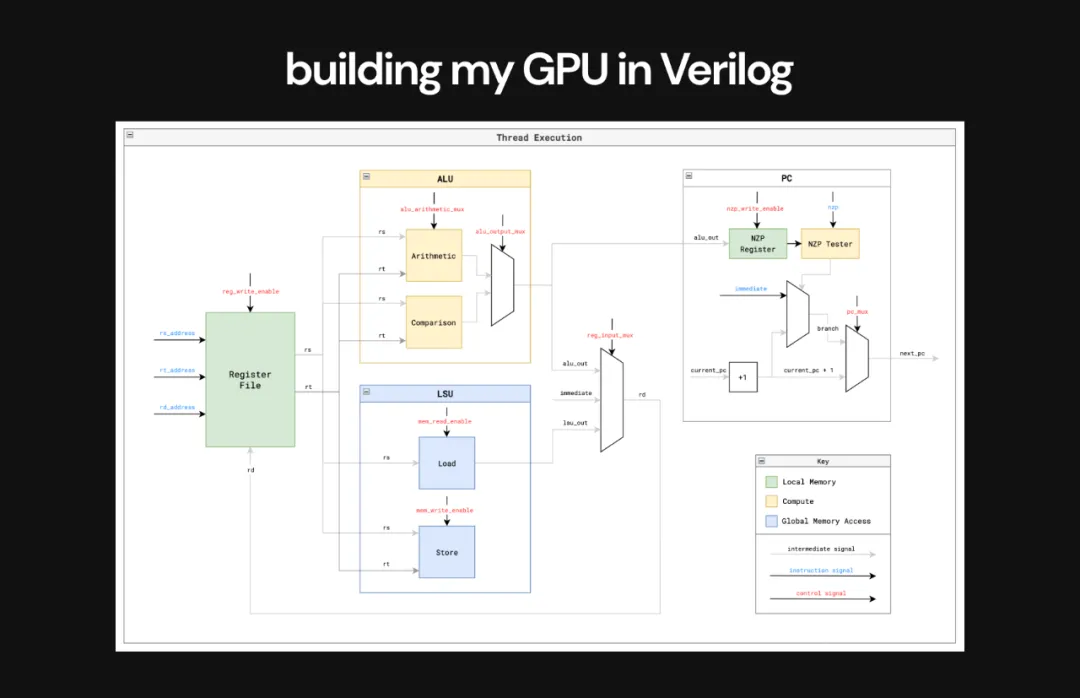
這是用 Verilog 構建的 GPU 中單個線程的執行流程,它的執行方式與 CPU 非常相似。
經過大量重新設計后,我們終于可以看到 GPU 運行矩陣加法和乘法時內核的景象了。看到一切正常工作,GPU 輸出了正確的結果,這是一種不可思議的感覺。

然后,我們還需要將設計通過 EDA 流程,轉換為完整的芯片布局。

完整的 Verilog 設計是通過 OpenLane EDA 實現的,采用 Skywater 130nm 工藝節點(用于 Tiny Tapeout)。Majmudar 特別解釋說,一些設計規則檢查 (DRC) 失敗,需要返工。
經過兩周的努力,Majmudar 的 GPU 設計的 3D 可視化如下圖所示:

CPU、GPU 都做了出來
Adam Majmudar 表示自己在很短的時間內,了解了芯片架構的基礎知識,掌握了芯片制造的細節,并使用 EDA 工具完成了他的第一個完整芯片布局,即手搓 CPU。
談到如何能做到「手搓芯片」,Majmudar 總結主要分 6 步:
- 學習芯片架構的基礎知識;
- 學習芯片制造的基礎知識,包括材料、晶圓制備、圖案化和封裝等;
- 通過逐層制作 CMOS 晶體管開始電子設計自動化;
- 用 Verilog 創建第一個完整電路;
- 為電路實施仿真和形式驗證;
設計完整芯片布局,使用 OpenLane(一種開源 EDA 工具)進行設計和優化。
在工程師圈子里,時不時會有人去嘗試「手搓芯片」,用最硬核的方式去了解芯片架構的基礎知識。不過在以前,大多數人因為難度,嘗試的是 CPU。
2020 年,中國科學院大學公布了首期「一生一芯」計劃的結果,曾經引發了人們的熱議。該計劃是在國內首次以流片為目標,由 5 位 2016 級本科生主導完成一款 64 位 RISC-V 處理器 SoC 芯片設計并實現流片。
此項目還得到了 RISC 體系奠基人、圖靈獎得主 David Patterson 教授的關注。
得益于開源芯片、敏捷設計等行業新趨勢的發展,芯片的設計門檻正在越來越低。
或許手搓 GPU 的先例出現后,我們會看到更多、性能更加強大的自造芯片實踐。






















