













GPU暴增的GenAI時代,AMD正跨越英偉達的CUDA軟件護城河
如今,當人們談論起生成式 AI(GenAI)時,GPU 以及相應的性能和訪問性幾乎是繞不過的話題。而英偉達又是 GPU 的代名詞,在國際 GPU 市場上占據絕對優勢的份額。同時,近年來 AMD 也逐漸崛起,占有了一定市場份額。
不過,AMD 與英偉達仍存在較大差距。此前市場調研機構 Jon Peddie Research 發布的 2022 年 GPU 市場數據統計報告顯示,英偉達 PC GPU 出貨量高達 3034 萬塊,是 AMD 的近 4.5 倍。
就英偉達而言,其 GPU 與生成式 AI 的緊密聯系絕非偶然。一直以來,英偉達認識到需要利用工具和應用來幫助擴展自己的市場。因此,英偉達為人們獲取自身硬件設置了非常低的門檻,包括 CUDA 工具包和 cuDNN 優化庫等。
在被稱為硬件公司之外,正如英偉達應用深度學習研究副總裁 Bryan Catanzaro 所言,「很多人不知道的一點是,英偉達的軟件工程師比硬件工程師還要多。」
可以說,英偉達圍繞其硬件構建了強大的軟件護城河。雖然 CUDA 不開源,但免費提供,并處于英偉達的嚴格控制之下。英偉達從中受益,但也給那些希望通過開發替代硬件搶占 HPC 和生成式 AI 市場的公司和用戶帶來了挑戰。
「城堡地基」上的建筑
我們知道,為生成式 AI 開發的基礎模型數量持續增長,其中很多是開源的,可以自由使用和共享,如 Meta 的 Llama 系列大模型。這些模型需要大量資源(如人力和機器)來構建,并且局限于擁有大量 GPU 的超大規模企業,比如 AWS、微軟 Azure、Google Cloud、Meta Platforms 等。此外其他公司也購買大量 GPU 來構建自己的基礎模型。
從研究的角度來看,這些模型很有趣,可以用于各種任務。但是,對更多生成式 AI 計算資源的預期使用和需求越來越大,比如模型微調和推理,前者將特定領域的數據添加到基礎模型中,使之適合自己的用例;后者在微調后,實際使用(即問問題)需要消耗資源。
這些任務需要加速計算的參與,即 GPU。顯而易見的解決方案是購買更多的英偉達 GPU。但隨著供不應求,AMD 迎來了很好的機會。英特爾和其他一些公司也準備好進入這一市場。隨著微調和推理變得更加普遍,生成式 AI 將繼續擠壓 GPU 的可用性,這時使用任何 GPU(或加速器)都比沒有 GPU 好。
放棄英偉達硬件意味著其他供應商的 GPU 和加速器必須支持 CUDA 才能運行很多模型和工具。AMD 通過 HIP(類 CUDA)轉換工具使這一情況成為可能。
PyTorch 放下軟件護城河「吊橋」
在 HPC 領域,支持 CUDA 的應用程序統治著 GPU 加速的世界。使用 GPU 和 CUDA 時,移植代碼通常可以實現 5-6 倍的加速。但在生成式 AI 中,情況卻截然不同。
最開始,TensorFlow 是使用 GPU 創建 AI 應用的首選工具,它既可以與 CPU 配合使用,也能夠通過 CUDA 實現加速。不過,這一情況正在快速發生改變。
PyTorch 成為了 TensorFlow 的強有力替代品,作為一個開源機器學習庫,它主要用于開發和訓練基于神經網絡的深度學習模型。
最近 AssemblyAI 的一位開發者 educator Ryan O’Connor 在一篇博客中指出,在流行的 HuggingFace 網站上,92% 的可用模型都是 PyTorch 獨有的。
此外如下圖所示,機器學習論文的比較也顯示出放棄 TensorFlow、轉投 PyTorch 的顯著趨勢。
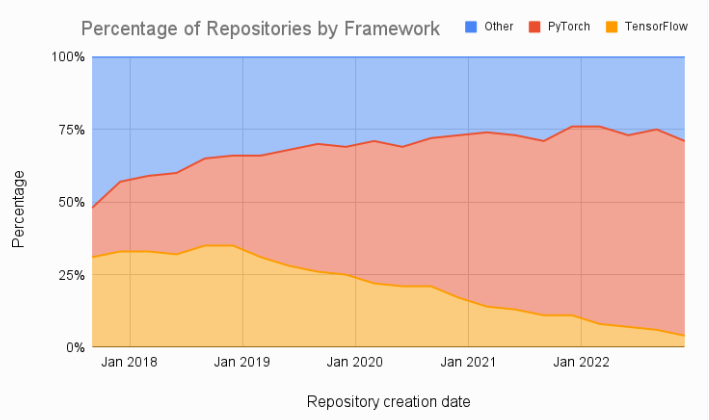
當然,PyTorch 底層對 CUDA 進行調用,但不是必需的,這是因為 PyTorch 將用戶與底層 GPU 架構隔離開來。AMD 還有一個使用 AMD ROCm 的 PyTorch 版本,它是一個用于 AMD GPU 編程的開源軟件堆棧。
現在,對于 AMD GPU 而言,跨越 CUDA 護城河就像使用 PyTorch 一樣簡單。
推理的本能
在 HPC 和生成式 AI 中,配有 H100 GPU 共享內存的英偉達 72 核、且基于 ARM 的 Grace-Hopper 超級芯片(以及 144 核 Grace-Grace 版本)備受期待。
迄今,英偉達發布的所有基準測試表明,該芯片的性能比通過 PCIe 總線連接和訪問 GPU 的傳統服務器要好得多。Grace-Hopper 是面向 HPC 和生成式 AI 的優化硬件,有望在微調和推理方面得到廣泛應用,需求預計會很高。
而 AMD 從 2006 年(于當年收購了顯卡公司 ATI)就已經出現了帶有共享內存的 CPU-GPU 設計。從 Fusion 品牌開始,很多 AMD x86_64 處理器都作為 APU(加速處理單元)的組合 CPU/GPU 來實現。
AMD 推出的 Instinct MI300A 處理器(APU)將與英偉達的 Grace-Hopper 超級芯片展開競爭。集成的 MI300A 處理器將最多提供 24 個 Zen4 核心,并結合 CDNA 3 GPU 架構和最多 192GB 的 HBM3 內存,為所有 CPU 和 GPU 核心提供了統一的訪問內存。
可以說,芯片級緩存一致性內存減少了 CPU 和 GPU 之間的數據移動,消除了 PCIe 總線瓶頸,提升了性能和能效。
AMD 正在為模型推理市場準備 MI300A 處理器。如 AMD CEO 蘇姿豐所言,「實際上,得益于架構上的一些選擇,我們認為自己將成為推理解決方案的行業領導者。」
對于 AMD 和很多其他硬件供應商而言,PyTorch 已經在圍繞基礎模型的 CUDA 護城河上放下了吊橋。AMD 的 Instinct MI300A 處理器將打頭陣。
生成式 AI 市場的硬件之戰將憑借性能、可移植性和可用性等多因素來取勝。未來鹿死誰手,尚未可知。

























