













力壓Transformer?首篇Mamba綜述來了!
本文經(jīng)自動駕駛之心公眾號授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
寫在前面&筆者的個人理解
Mamba是一種新的選擇性結(jié)構(gòu)狀態(tài)空間模型,在長序列建模任務(wù)中表現(xiàn)出色。Mamba通過全局感受野和動態(tài)加權(quán),緩解了卷積神經(jīng)網(wǎng)絡(luò)的建模約束,并提供了類似于Transformers的高級建模能力。至關(guān)重要的是,它實現(xiàn)了這一點,而不會產(chǎn)生通常與Transformer相關(guān)的二次計算復(fù)雜性。由于其相對于前兩種主流基礎(chǔ)模型的優(yōu)勢,曼巴展示了其作為視覺基礎(chǔ)模型的巨大潛力。研究人員正在積極地將曼巴應(yīng)用于各種計算機視覺任務(wù),導(dǎo)致了許多新興的工作。為了跟上計算機視覺的快速發(fā)展,本文旨在對視覺曼巴方法進行全面綜述。本文首先描述了原始曼巴模型的公式。隨后,我們對視覺曼巴的綜述深入研究了幾個具有代表性的骨干網(wǎng)絡(luò),以闡明視覺曼巴中的核心見解。然后,我們使用不同的模式對相關(guān)作品進行分類,包括圖像、視頻、點云、多模態(tài)等。具體來說,對于圖像應(yīng)用程序,我們將它們進一步組織成不同的任務(wù),以促進更結(jié)構(gòu)化的討論。最后,我們討論了視覺曼巴的挑戰(zhàn)和未來的研究方向,為這個快速發(fā)展的領(lǐng)域的未來研究提供了見解。
開源鏈接:https://github.com/Ruixxxx/Awesome-Vision-Mamba-Models
總結(jié)來說,本文的主要貢獻如下:
- 曼巴的形成:本文提供了曼巴和狀態(tài)空間模型的操作原理的介紹性概述。
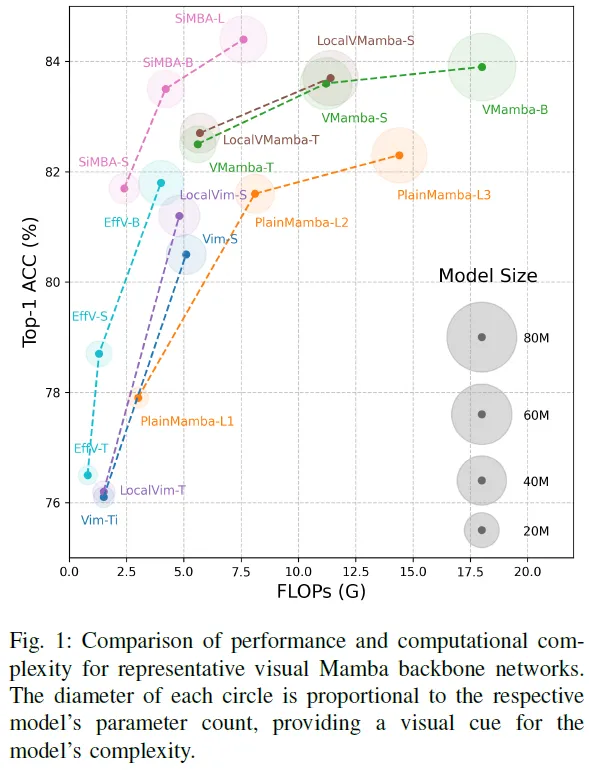
- 主干網(wǎng)絡(luò):我們提供了幾個具有代表性的視覺曼巴骨干網(wǎng)絡(luò)的詳細檢查。本分析旨在闡明支撐Visual Mamba框架的核心原則和創(chuàng)新。
- 應(yīng)用:我們根據(jù)不同的模態(tài)對曼巴的其他應(yīng)用進行分類,如圖像、視頻、點云、多模態(tài)數(shù)據(jù)等。深入探討了每個類別,以突出曼巴框架如何適應(yīng)每種模態(tài)并使其受益。對于涉及圖像的應(yīng)用,我們進一步將其劃分為各種任務(wù),包括但不限于分類、檢測和分割。
- 挑戰(zhàn):我們通過分析視覺數(shù)據(jù)的獨特特征、算法的潛在機制以及現(xiàn)實世界應(yīng)用程序的實際問題,來研究與CV相關(guān)的挑戰(zhàn)。
- 未來方向:我們探索視覺曼巴的未來研究方向,重點關(guān)注數(shù)據(jù)利用和算法開發(fā)方面的潛在進展。
Mamba公式
Mamba是最近的一個序列模型,旨在通過簡單地將其參數(shù)作為輸入的函數(shù)來提高SSM基于上下文的推理能力。這里的SSM特別指的是結(jié)構(gòu)化狀態(tài)空間序列模型(S4)中使用的序列變換,它可以被納入深度神經(jīng)網(wǎng)絡(luò)。Mamba簡化了常用的SSM塊,形成了簡化的SSM架構(gòu)。在下文中,我們將詳細闡述曼巴的核心概念。
SSM




Selective SSM

Mamba結(jié)構(gòu)
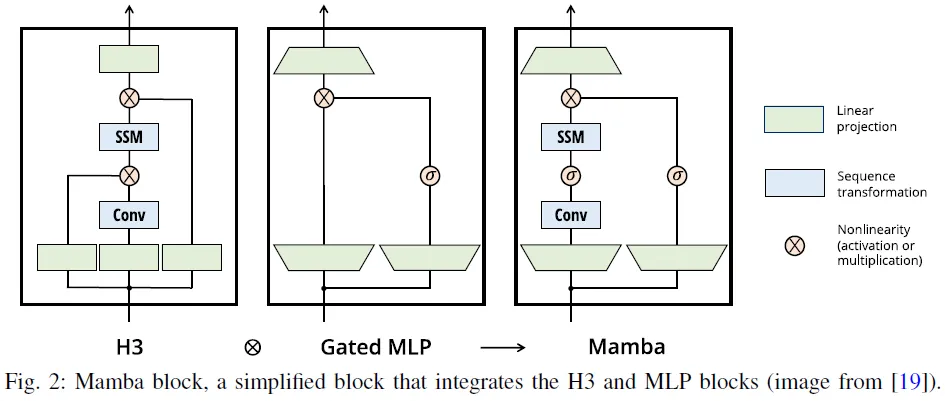
Mamba是一種簡化的SSM架構(gòu)。與通常使用的SSM架構(gòu)不同,后者將類似線性注意力的塊和多層感知器(MLP)塊堆疊為Transformer,Mamba將這兩個基本塊集成起來構(gòu)建Mamba塊。如圖2所示,曼巴區(qū)塊可以從兩個不同的角度進行觀察。首先,它用激活函數(shù)代替線性類注意力或H3塊中的乘法門。其次,它將SSM轉(zhuǎn)化納入MLP阻斷的主要途徑。Mamba的總體架構(gòu)由重復(fù)的Mamba塊組成,這些塊與標準規(guī)范化層和殘差連接交織在一起。
Mamba繼承了狀態(tài)空間模型序列長度的線性可伸縮性,同時實現(xiàn)了Transformer的建模能力。Mamba結(jié)合了CV中兩種主要類型的基礎(chǔ)模型(即CNN和Transformer)的顯著優(yōu)勢,使其成為一種很有前途的CV基礎(chǔ)模型。與依賴于顯式存儲整個上下文進行基于上下文的推理的Transformer相比,Mamba利用了一種選擇機制。因此,這種選擇機制的1D和因果特征成為研究人員將曼巴應(yīng)用于CV的焦點。
表征學(xué)習的主干
Pure Mamba
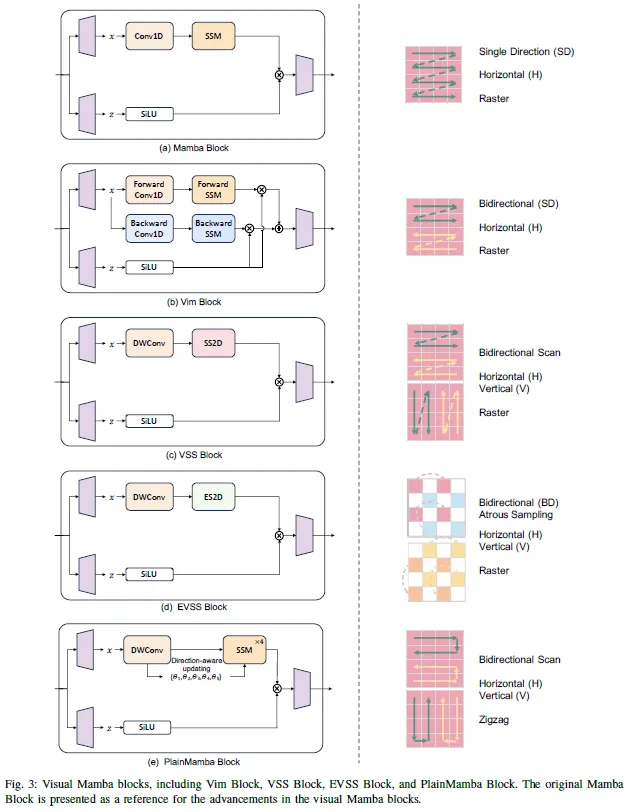
1)Vim:Vim是一種基于Mamba的架構(gòu),直接在類似于ViT的圖像補丁序列上操作。首先將輸入圖像轉(zhuǎn)換為平坦的2D塊,然后使用線性投影層對其進行矢量化,并添加位置嵌入以保留空間信息。在ViT和BERT之后,將類令牌附加到補丁令牌序列。然后將整個令牌序列饋送到Vim編碼器,該編碼器由相同的Vim塊組成。如圖6所示,如圖3(b)所示,Vim塊是一個Mamba塊,它將后向SSM路徑與前向路徑集成在一起。
2)VMamba:VMamba確定了將曼巴應(yīng)用于2D圖像的兩個挑戰(zhàn),這是由曼巴中選擇機制的1D和因果屬性引起的。對輸入數(shù)據(jù)的因果處理使曼巴無法吸收來自未掃描數(shù)據(jù)部分的信息。此外,1D掃描對于涉及在局部和全局尺度上相關(guān)的2D空間信息的圖像來說不是最優(yōu)的。
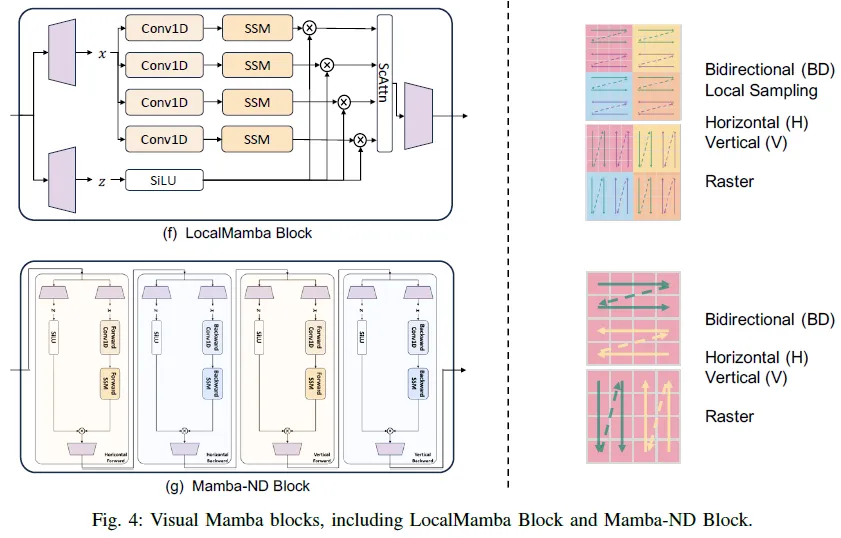
3)Mamba ND:Mamba ND旨在將Mamba擴展到包括圖像和視頻在內(nèi)的多維數(shù)據(jù)。它將1D曼巴層視為一個黑匣子,并探索如何解開和排序多維數(shù)據(jù)。它主要解決數(shù)據(jù)缺乏預(yù)定義的排序,同時具有固有的空間維度所帶來的挑戰(zhàn)。考慮到將數(shù)據(jù)平坦化為1D序列的大量可能方式,Mamba ND僅包括通過沿其維度軸在向前或向后方向上平坦化數(shù)據(jù)的掃描排序。然后,它將作為1D曼巴層的組合的曼巴ND塊以交替順序應(yīng)用于序列。作者進行了廣泛的實驗來探索排序的不同組合。此外,他們將輸入數(shù)據(jù)的一維劃分為多個排序,采用不同的曼巴層排列,并將序列分解為更小的序列。結(jié)果表明,曼巴層鏈和簡單的交替方向排序?qū)崿F(xiàn)了優(yōu)越的性能。曼巴ND區(qū)塊的最終設(shè)計如圖4(g)所示。
4)PlainMamba:PlainMamba是一種非層次結(jié)構(gòu),旨在實現(xiàn)以下幾個目標:(1)非層次結(jié)構(gòu)有助于多層次特征融合,增強不同規(guī)模的集成;(2) 它支持多模態(tài)數(shù)據(jù)的有效融合;(3) 其更簡單的體系結(jié)構(gòu)往往提供更好的泛化能力;(4) 它適用于硬件加速的優(yōu)化。
Hybrid Mamba
1)LocalMamba:LocalMamba解決了在Vim和VMamba模型中觀察到的一個顯著限制,即在單個掃描過程中空間局部令牌之間的依賴性被破壞。為了克服這個問題,如圖5所示的局部采樣,LocalMamba將輸入圖像劃分為多個局部窗口,以在不同方向上執(zhí)行SSM,如VMamba所示,同時還保持全局SSM操作。此外,LocalMamba在補丁合并之前實現(xiàn)了空間和通道注意力模塊,以增強方向特征的集成,減少冗余。LocalMamba區(qū)塊如圖4(f)所示。此外,它還采用了為每層選擇最有效掃描方向的策略,從而優(yōu)化了計算效率。
2)EfficientVMamba:EfficientVMamba引入了高效二維掃描(ES2D)技術(shù),該技術(shù)采用對特征圖上的斑塊進行異步采樣來減少計算負擔。萎縮采樣如圖5所示。ES2D用于提取全局特征,而并行卷積分支用于提取局部特征。機器人特征類型然后由擠壓和激勵(SE)塊單獨處理。ES2D、卷積分支和SE塊共同構(gòu)成了有效視覺狀態(tài)空間(EVSS)塊的核心組件。EVSS塊的輸出是調(diào)制的全局和局部特征的總和。EVSS塊如圖3(d)所示。EVSS塊形成EfficientVMamba的早期階段,而EfficientNet塊反過來形成后期階段。
3)SiMBA:SiMBA旨在解決Mamba在視覺數(shù)據(jù)集上擴展到大型網(wǎng)絡(luò)的不穩(wěn)定性問題。它提出了一種新的信道建模技術(shù),稱為EinFFT,并使用Mamba進行序列建模。換言之,SiMBA塊由Mamba塊和EinFFT塊組成,兩者都與LN層、丟棄和殘差連接交織。
關(guān)鍵提升
1)主干:為了處理2D圖像,首先通過主干模塊將其轉(zhuǎn)換為視覺標記序列,主干模塊通常包括卷積層和線性投影層。位置嵌入的添加是可選的,因為SSM操作固有地具有因果特性。包含類標記也是可選的。現(xiàn)有方法通過將圖像序列視為用于基于曼巴的塊中的SSM變換和卷積運算的1D或2D結(jié)構(gòu)來處理圖像序列。鑒于掃描技術(shù)在這些過程中的整體作用,我們將在下一節(jié)中對這些方法進行系統(tǒng)分類和更詳細的研究。在本節(jié)中,我們將區(qū)分基于Mamba的層次結(jié)構(gòu)和非層次結(jié)構(gòu)。
2)掃描:選擇性掃描機制是曼巴的關(guān)鍵組成部分。然而,其針對1D因果序列的原始設(shè)計在將其適應(yīng)2D非因果圖像時帶來了挑戰(zhàn)。為應(yīng)對這些挑戰(zhàn),進行了大量的研究工作。在下一節(jié)中,我們將這些工作分類并討論為三個主要組,掃描模式、掃描軸和掃描連續(xù)性。這種分類是基于掃描技術(shù)的目標。掃描模式處理視覺數(shù)據(jù)的非因果特性;掃描軸處理視覺數(shù)據(jù)中固有的高維度;掃描連續(xù)性考慮了貼片沿著掃描路徑的空間連續(xù)性;掃描采樣將整個圖像劃分為子圖像。這四組的圖示如圖5所示。
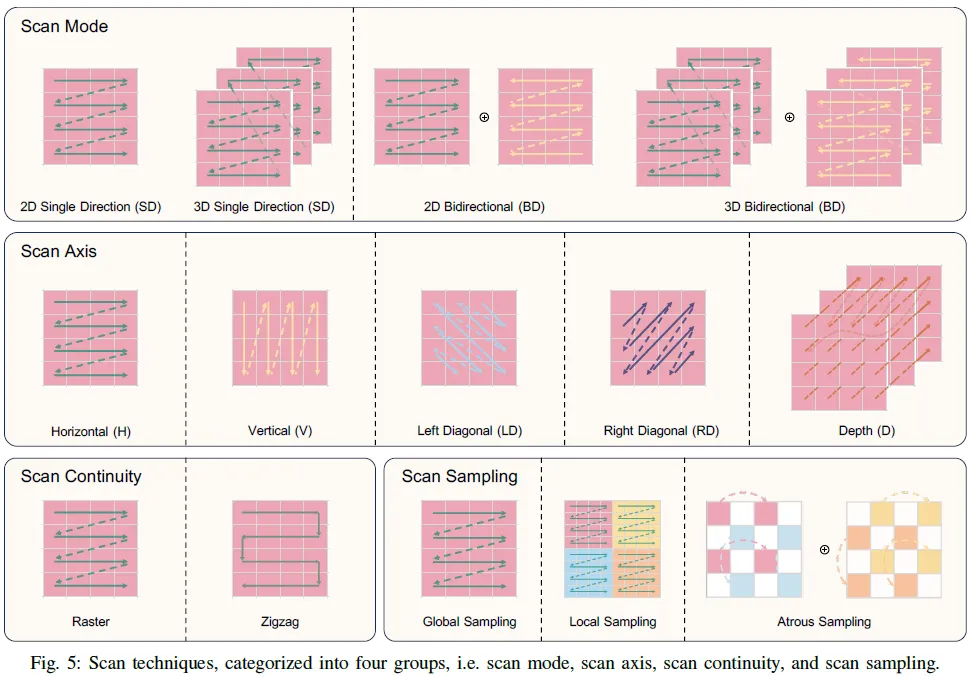
3)Block:前面提到的掃描技術(shù)和選擇性SSM變換的不同組合形成了各種塊,這些塊是基于Mambab的架構(gòu)的組成部分。在討論視覺曼巴骨干網(wǎng)絡(luò)時,我們對這些區(qū)塊進行了概述,并在相應(yīng)的圖中給出了詳細的說明。這些數(shù)字也驗證了我們對掃描技術(shù)進行分類背后的邏輯。這些塊在應(yīng)用方法中被廣泛使用,將在下一節(jié)中詳細介紹。為了清楚起見,最初的曼巴區(qū)塊簡稱為曼巴。代表性塊由諸如VSS和Vim之類的名稱表示。對這些塊的修改由星號(*)表示,并且諸如+CNN之類的標簽表示類CNN特征的集成。圖3和圖4說明了一套視覺Mamba區(qū)塊,包括Vim區(qū)塊、VSS區(qū)塊、EVSS區(qū)塊、PlainMamba區(qū)塊、LocalMamba區(qū)塊和Mamba ND區(qū)塊。曼巴區(qū)塊也包括在內(nèi),以便于直接比較,突出這些區(qū)塊在視覺領(lǐng)域的進化設(shè)計。
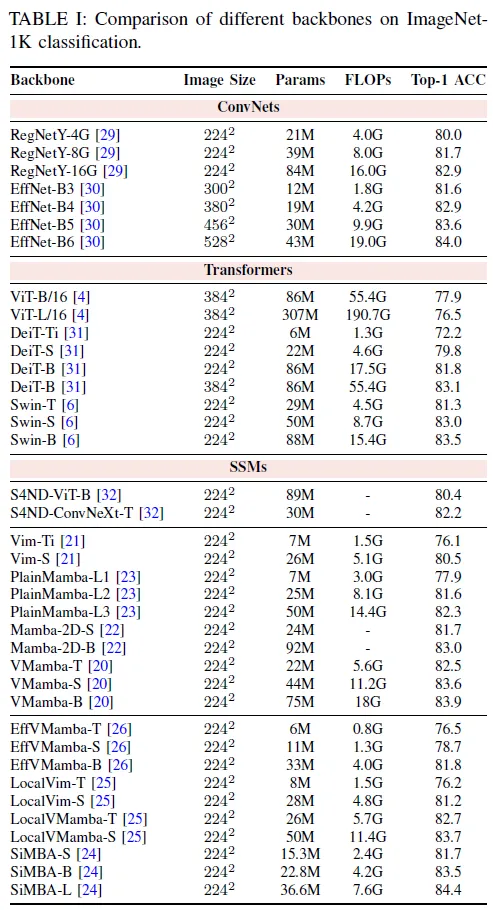
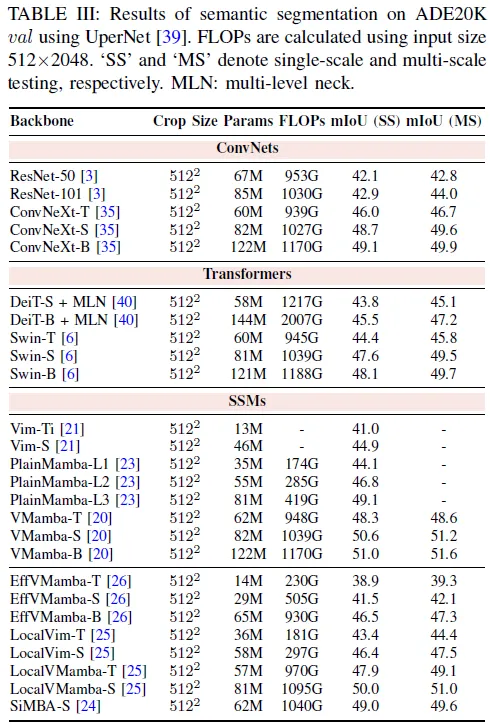
在本節(jié)中,我們在表中的標準基準上展示了各種可視曼巴骨干網(wǎng)絡(luò)的性能。表I、表II和表III:ImageNet-1K上的分類,通過Mask R-CNN在MS COCO上的目標檢測和實例分割,以及利用UperNet在ADE20K上的語義分割。

應(yīng)用
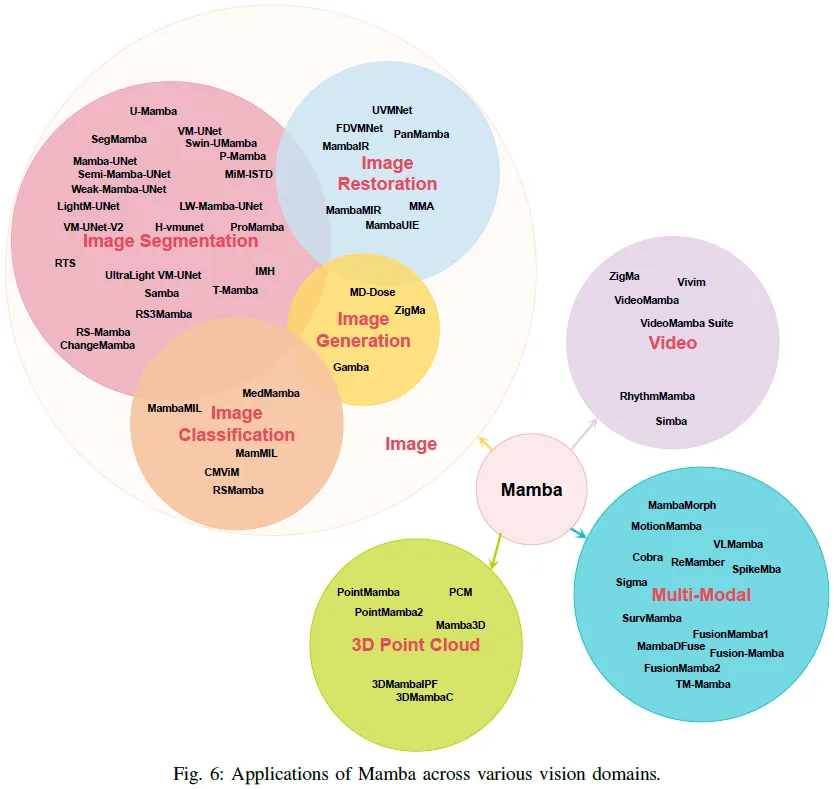
本節(jié)系統(tǒng)地對曼巴在計算機視覺領(lǐng)域的各種應(yīng)用進行了分類和討論。分類方案以及本次調(diào)查中回顧的相關(guān)文獻概述如圖6所示。
A.圖像
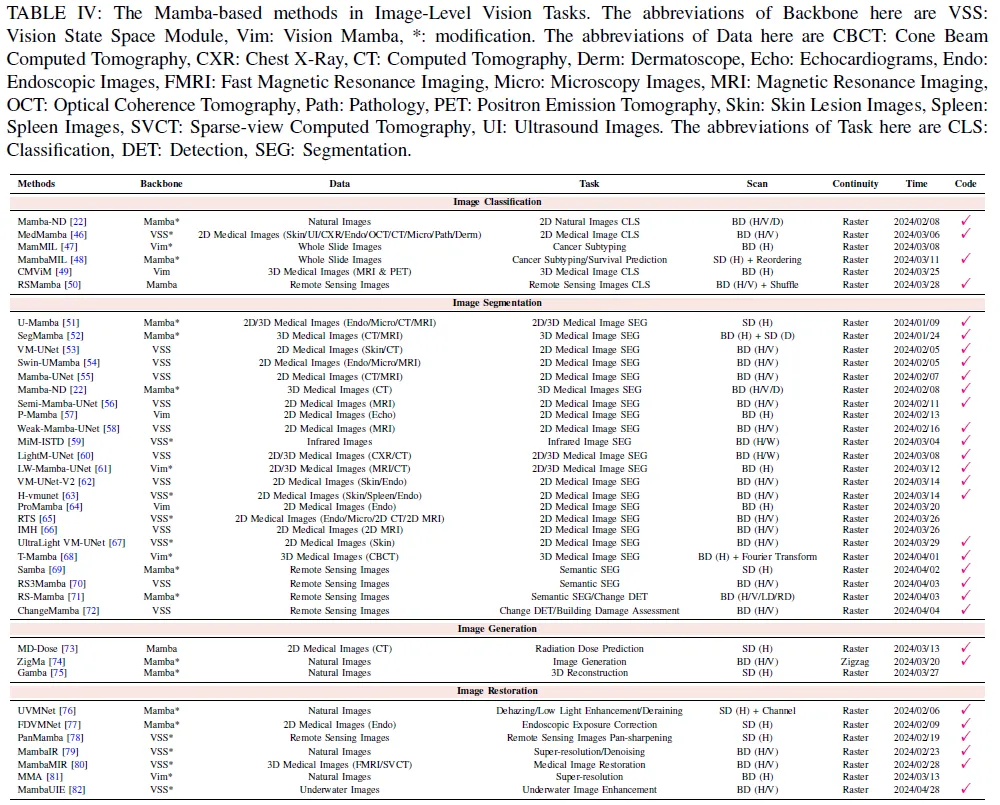
1)分類:除了主干進行圖像分類以進行表示學(xué)習外,Mamba ND還引入了一種處理多維數(shù)據(jù)的新方法,通過按照行主順序交替分解不同維度的輸入數(shù)據(jù)。在自然圖像分類的背景下,與基于Transformer的方法相比,該技術(shù)以顯著更少的參數(shù)展示了優(yōu)越的性能。同時,Mamba ND可以很容易地擴展到涉及多維數(shù)據(jù)的視頻動作識別和3D分割等多項任務(wù)。基于Mamba的架構(gòu)對更大補丁序列的可擴展性導(dǎo)致它們被用于高分辨率圖像(例如,全幻燈片圖像和遙感圖像)和高維圖像(例如3D醫(yī)學(xué)圖像)的分析以用于識別目的。
2)分割:分割仍然是計算機視覺領(lǐng)域的一個重要和突出的研究領(lǐng)域,對不同的現(xiàn)實世界應(yīng)用具有巨大的價值。通過使用基于CNN的模型和基于transformer的模型,分割技術(shù)的最新進展取得了顯著成就。基于細胞神經(jīng)網(wǎng)絡(luò)的方法擅長通過卷積運算捕捉局部特征,而基于變換器的方法則通過利用自注意機制來理解全局上下文,表現(xiàn)出非凡的能力。然而,基于變換器的方法的一個局限性是,隨著輸入大小的增加,自注意的計算復(fù)雜度呈二次增長。特別是對于高分辨率圖像或高緯度圖像,Transformer架構(gòu)及其整體注意力層對有限窗口之外的任何事物進行建模的能力有限,并表現(xiàn)出二次復(fù)雜性,導(dǎo)致性能次優(yōu)。
3) 生成:直觀地說,將Mamba架構(gòu)應(yīng)用于一系列生成任務(wù),以實現(xiàn)足夠的長序列交互,有可能實現(xiàn)令人印象深刻的性能。
4) 圖像恢復(fù):最近,曼巴架構(gòu)也被廣泛應(yīng)用于幾個低級別的任務(wù),包括圖像去霧、曝光校正、泛銳化、超分辨率、去噪、醫(yī)學(xué)圖像重建和水下圖像增強。
B.視頻
視頻理解是計算機視覺研究的基本方向之一。視頻理解的主要目標是有效地掌握長上下文中的時空表示。Mamba憑借其選擇性狀態(tài)空間模型在這一領(lǐng)域表現(xiàn)出色,在保持線性復(fù)雜性和實現(xiàn)有效的長期動態(tài)建模之間實現(xiàn)了平衡。這種創(chuàng)新方法促進了其在各種視頻分析任務(wù)中的廣泛采用,如視頻目標分割、視頻動作識別、視頻生成和表示學(xué)習。
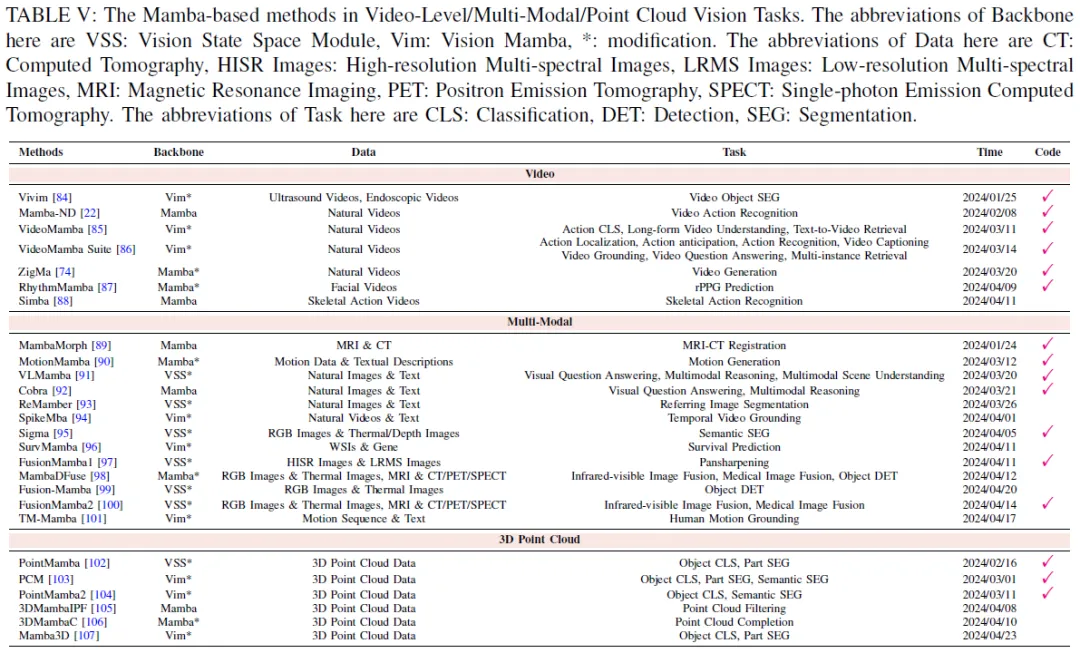
C.多模態(tài)
多莫泰任務(wù)在CV領(lǐng)域發(fā)揮著至關(guān)重要的作用,因為它們有助于整合各種信息源,豐富視覺數(shù)據(jù)的理解和分析。這些任務(wù)的目標是聚合多種模態(tài),包括文本和視覺信息、具有附加組件(如深度或熱圖像)的RGB圖像以及各種形式的醫(yī)學(xué)成像數(shù)據(jù)。然而,實現(xiàn)多模式目標的一個重大挑戰(zhàn)在于有效地捕捉不同模式之間的相關(guān)性。最近,有幾種方法將Mamba架構(gòu)用于許多多模式任務(wù),包括多模式大語言模型、多模態(tài)配準、參考圖像分割、時間視頻基礎(chǔ)、語義分割、運動生成和醫(yī)學(xué)應(yīng)用。
D.點云
點云是一種基本的三維表示,它提供具有三維坐標的連續(xù)空間位置信息。點云的內(nèi)在無序性和不規(guī)則性一直是三維視覺中的一個挑戰(zhàn)。受Mamba的線性復(fù)雜性和全局建模能力的啟發(fā),在點云處理領(lǐng)域研究了幾種基于SSM的通用主干。
PointMamba直接使用VSS塊作為編碼器,并提出了一種重新排序策略,通過提供更符合邏輯的幾何掃描順序來增強SSM的全局建模能力。PCM結(jié)合了幾何仿射塊和Vim塊作為基本塊,并提出了一致遍歷串行化(CTS)將點云串行化為1D點序列,同時確保空間連續(xù)性。具體而言,CTS通過排列3D坐標的順序產(chǎn)生六種變體,從而全面觀測點云數(shù)據(jù)。PointMamba采用Vim進行長序列建模,并引入了基于八叉樹的排序機制來生成輸入序列,以獲得原始輸入點的因果關(guān)系。3DMamba IPF結(jié)合了Mamba架構(gòu),以順序處理來自大型場景的大量點云,并集成了穩(wěn)健且快速可微分的渲染損失,以約束曲面周圍的噪聲點。3DMambaC引入了一個超點生成模塊來生成新的形狀表示超點,其中包括用于增強采樣點特征和預(yù)測超點的Mamba編碼器。Mamba3D采用了具有通道翻轉(zhuǎn)的雙向SSM,并引入了局部范數(shù)池(LNP)塊來提取局部幾何特征。
挑戰(zhàn)
A. Algorithm
1)可擴展性和穩(wěn)定性:目前,Mamba架構(gòu)在應(yīng)用于ImageNet等大規(guī)模數(shù)據(jù)集時表現(xiàn)出穩(wěn)定性挑戰(zhàn)。曼巴在擴展到更廣泛的網(wǎng)絡(luò)配置時不穩(wěn)定的根本原因尚不清楚。這種不穩(wěn)定性經(jīng)常導(dǎo)致曼巴框架內(nèi)的梯度消失或爆炸,這阻礙了其在大規(guī)模視覺任務(wù)中的部署。
2)因果關(guān)系問題:鑒于曼巴模型最初是為因果序列數(shù)據(jù)設(shè)計的,將其選擇性掃描技術(shù)應(yīng)用于非因果視覺數(shù)據(jù)帶來了重大挑戰(zhàn)。目前的方法通過采用雙向掃描等掃描技術(shù)來解決這一問題,其中向前和向后掃描都被用來相互補償感受野中單向掃描的固有限制。然而,這仍然是一個懸而未決的問題,繼續(xù)帶來挑戰(zhàn)。
3)空間信息:曼巴選擇性掃描技術(shù)固有的1D特性在應(yīng)用于2D或更高維度的視覺數(shù)據(jù)時帶來了挑戰(zhàn),因為它可能導(dǎo)致關(guān)鍵空間信息的丟失。為了解決這一限制,當前的方法通常從各個方向展開圖像塊,從而允許跨多個維度的空間信息的集成。然而,這個問題仍然是一個懸而未決的問題,需要進一步調(diào)查。
4)冗余和計算:如前所述,雙向掃描方法和多個掃描方向的使用會導(dǎo)致顯著的信息冗余和計算需求的增加。這些可能會降低模型性能,并降低曼巴線性復(fù)雜度的優(yōu)勢。根據(jù)研究結(jié)果,與Transformer模型相比,Mamba模型的GPU消耗并不一致。這是一個重要挑戰(zhàn),需要進一步調(diào)查。
B. 應(yīng)用
1)可解釋性:一些研究提供了實驗證據(jù)來闡明曼巴模型在NLP中的潛在機制,重點是其上下文學(xué)習能力、和事實回憶能力。此外,其他工作為曼巴在NLP中的應(yīng)用奠定了理論基礎(chǔ)。盡管取得了這些進步,但解釋為什么曼巴能有效地完成視覺任務(wù)仍然具有挑戰(zhàn)性。然而,視覺曼巴的獨特學(xué)習特征及其與其他基礎(chǔ)模型(如RNN、CNNs和ViTs)的相似之處仍然需要更深入的解釋。
2)泛化和魯棒性:Mamba中的隱藏狀態(tài)可能會積累甚至放大特定領(lǐng)域的信息,這可能會對其泛化性能產(chǎn)生不利影響。此外,模型固有的1D掃描策略可能會無意中捕捉到特定領(lǐng)域的偏差,而當前的掃描技術(shù)往往無法滿足對領(lǐng)域不可知信息處理的需求。[118]中的研究證明了VMamba在對抗性彈性和總體穩(wěn)健性方面的優(yōu)勢。然而,在處理這些任務(wù)時,它也指出了可擴展性方面的局限性。該研究包括對VMamba的白盒攻擊,以檢查其新組件在對抗性條件下的行為。研究結(jié)果表明,雖然參數(shù)Δ表現(xiàn)出魯棒性,但參數(shù)B和C容易受到攻擊。參數(shù)之間的這種差異漏洞導(dǎo)致了VMamba在保持健壯性方面的可擴展性挑戰(zhàn)。此外,結(jié)果表明,VMamba對其掃描軌跡的連續(xù)性和空間信息的完整性的中斷表現(xiàn)出特別的敏感性。增強視覺曼巴的泛化能力和魯棒性仍然是該領(lǐng)域尚未解決的挑戰(zhàn)。
未來方向
A.數(shù)據(jù)
1)數(shù)據(jù)效率:考慮到Mamba的計算成本與CNN相當,即使不依賴大規(guī)模數(shù)據(jù)集,它也具有提供最佳性能的巨大潛力。這一屬性將曼巴定位為各種下游任務(wù)/多任務(wù)和涉及預(yù)訓(xùn)練模型自適應(yīng)的任務(wù)的有前途的候選者。
2)高分辨率數(shù)據(jù):由于SSM的架構(gòu)在理論上簡化了計算復(fù)雜性,因此其有效處理高分辨率數(shù)據(jù)(如遙感和全切片圖像)或長期序列數(shù)據(jù)(如長期視頻幀)的潛力具有相當大的價值。
3)多模態(tài)數(shù)據(jù):正如Transformer架構(gòu)已經(jīng)證明了其在統(tǒng)一框架內(nèi)對自然語言和圖像進行建模的能力一樣,Mamba模型在處理擴展序列方面的熟練程度大大拓寬了其在多模式學(xué)習中的適用性。
4)上下文學(xué)習:在深度學(xué)習的動態(tài)環(huán)境中,上下文學(xué)習已經(jīng)發(fā)展到包含越來越復(fù)雜和新穎的方法,以解決NLP、CV和多模式領(lǐng)域的復(fù)雜任務(wù)。這種方法上的進步對于突破現(xiàn)有深度學(xué)習框架的極限至關(guān)重要。Mamba模型憑借其精通上下文建模能力和捕獲長程依賴關(guān)系的能力,在上下文學(xué)習應(yīng)用程序中顯示出更深入的語義理解和增強性能的潛力。
B.算法
1)掃描技術(shù):選擇性掃描機制是曼巴模型的核心組成部分,最初針對1D因果序列數(shù)據(jù)進行了優(yōu)化。為了解決視覺數(shù)據(jù)固有的非因果性質(zhì),許多現(xiàn)有方法采用雙向掃描。此外,為了捕獲2D或高維視覺數(shù)據(jù)中固有的空間信息,當前的方法通常擴展掃描方向。盡管有這些調(diào)整,但迫切需要更具創(chuàng)新性的掃描方案,以更有效地利用高維非因果視覺數(shù)據(jù)的全部潛力。
2)融合技術(shù):使曼巴模型適應(yīng)視覺任務(wù)往往會引入冗余,使掃描輸出特征的有效融合成為進一步探索的重要領(lǐng)域。此外,計算機視覺的基礎(chǔ)模型各有其獨特的優(yōu)勢;例如,細胞神經(jīng)網(wǎng)絡(luò)固有地捕捉歸納偏差,如翻譯等變,而ViT以其強大的建模能力而聞名。探索融合這些不同網(wǎng)絡(luò)架構(gòu)提取的特征以最大限度地發(fā)揮其優(yōu)勢的方法是一個寶貴的研究機會。
3)計算效率:Mamba在序列長度方面實現(xiàn)了線性可擴展性,但由于需要在多個路徑中掃描,將其用于視覺任務(wù)會導(dǎo)致計算需求增加。因此,在開發(fā)更高效、更有效的視覺曼巴模型方面有著重要的研究機會。此外,Mamba模型在計算效率方面并不總是優(yōu)于Transformer,這突出了為視覺任務(wù)量身定制的優(yōu)化、硬件感知的Mamba算法的必要性。這為研究提供了一條很有前途的途徑,特別是在開發(fā)減少計算開銷同時保持或提高性能的方法方面。提高視覺曼巴模型的計算效率可以極大地提高其在現(xiàn)實世界場景中的適用性。
結(jié)論
Mamba已迅速成為一種變革性的長序列建模架構(gòu),以其卓越的性能和高效的計算實現(xiàn)而聞名。隨著它在計算機視覺領(lǐng)域的不斷發(fā)展,本文對視覺曼巴方法進行了全面的綜述。我們首先對Mamba架構(gòu)進行深入概述,然后詳細檢查具有代表性的可視化Mamba骨干網(wǎng)絡(luò)及其在各個可視化領(lǐng)域的廣泛應(yīng)用。這些應(yīng)用程序按不同的模式進行系統(tǒng)分類,包括圖像、視頻、點云和多模式數(shù)據(jù)等。最后,我們批判性地分析了與視覺曼巴相關(guān)的挑戰(zhàn),強調(diào)了這種架構(gòu)在推進計算機視覺方面尚未開發(fā)的潛力。根據(jù)這一分析,我們描繪了視覺曼巴未來的研究方向,提供了有價值的見解,可能會影響這一動態(tài)發(fā)展領(lǐng)域的持續(xù)和未來發(fā)展。





























