Fine-Tuning Vs RAG ,該如何選擇?
Hello folks,我是 Luga,今天我們來聊一下人工智能(AI)生態領域相關的技術 - LLM 構建塊:向量、令牌和嵌入 。
隨著技術的不斷進步,LLM 帶來了前所未有的機遇,吸引了開發者和組織紛紛嘗試利用其強大的能力構建應用程序。然而,當預訓練的 LLM 在實際應用中無法達到預期的性能水平時,人們將不由自主地開始思考:我們到底應該使用哪種技術來改善這些模型在特定場景下的表現?
Fine-Tuning(微調)和 RAG(檢索增強生成),作為兩種常見的 LLM 性能優化方法,在很多人眼中可能還帶有一絲神秘感。在深入探討兩者的利弊之前,我們有必要先了解這兩種方法的基本原理和特點。

一、高效賦能 LM 的利器—Fine-Tuning
什么是 Fine-Tuning (微調)?
在當今的自然語言處理領域,預訓練語言模型(PLM)憑借其在大規模語料上學習到的通用語義知識,儼然已成為各類下游任務的強力基石。但要充分發揮 PLM 在特定場景中的專業能力,就需要有一種高效的"定制化"方法,那便是 Fine-Tuning(微調)。
Fine-Tuning (微調)過程的核心,是在新的任務和數據集上對預訓練模型的參數進行微小的調整,使其能精準契合目標場景的需求。不同于完全從頭訓練一個全新模型,Fine-Tuning (微調)巧妙地利用了 PLM 在大規模語料上學習到的通用語義表征,在此基礎上進行"權重調校",從而大幅提高了模型收斂的速度和效率。
以情感分析任務為例,假設我們需要對電影評論進行正負面情緒判斷。此時,與從零開始構建一個全新模型不同,我們可以選擇像 GPT-3 這樣在海量文本上預訓練過的 PLM,并使用標注好的電影評論數據集對其進行微調。通過這一調整權重的過程,原本通用的語義模型就被"賦能"了情感分析的專業技能,可以高精度地捕捉評論中的情感傾向。

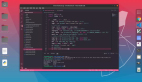
Fine-Tuning (微調)參考架構示意圖
二、開辟 LLM 智能認知的新領域—RAG
LLM (大型語言模型)正以其驚人的學習能力和泛化性能,開辟著認知智能的全新境界,而 RAG(檢索增強生成)便是為其插上智能利用外部知識的強力翅膀。
那么,什么是 Retrieval-Augmented Generation(檢索增強生成)?
RAG(檢索增強生成)是一種優化大型語言模型輸出的技術,在生成響應之前,讓模型除了查詢訓練數據源外,還能同時查閱可靠的知識庫。 LLM (大型語言模型)在訓練過程中使用了數十億參數和大量數據,能夠對問答、語言翻譯、句子補全等任務生成獨特的輸出。RAG 無需重新訓練模型,便能擴展 LLM 已有的強大能力,讓其能夠適用于新的領域或組織的內部知識庫。這是一種經濟高效的方式,能夠提升 LLM 輸出的準確性、相關性和實用性,使其在各種環境中依然保持出色表現。

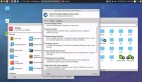
RAG(檢索增強生成)參考架構示意圖
在 RAG 的智能架構下,語言模型不再是相對封閉的"語義孤島"。它們將與龐大的異構知識庫無縫集成,在生成響應之前,先通過智能檢索系統獲取與任務相關的外部知識作為補充。由此,語言模型的認知能力得以突破自身訓練語料的局限,注入更為廣博、專業的知識維度。無論是回答一個特定領域的問題,還是完成專業化的文本生成任務,LLM 均能依托 RAG 的知識補給,提供更加準確、流暢、內容充實的輸出,大大增強了其在特殊場景下的適用性。
除了認知能力的開放突破,RAG 還為 LLM 的訓練和應用效率帶來了全新的優化。采用傳統方式,我們需要用特定領域的大量數據反復訓練 LLM,從而使其"學會"相關知識。這種重新訓練的過程不僅代價昂貴、效率低下,同時,知識的覆蓋面和時效性也極為有限。而 RAG 則通過靈活、高效的知識檢索和融合,快速賦能了 LLM 在新領域的應用能力,無需進行大規模的重復訓練。我們只需構建合適的知識庫,RAG 就能自動獲取與任務相關的最新信息,為 LLM 提供有力補充。
三、評估 Fine-Tuning & RAG 5 要素解析
在評估和應用 Fine-Tuning (微調)與 RAG(檢索增強生成)等語言 AI 技術時,我們需要全面審視和深入權衡諸多關鍵因素,方能最大限度發揮它們的能力,并將其貫徹落實到實際場景中。
1. 動態數據挑戰 vs 靜態數據局限
面對瞬息萬變的動態數據環境,RAG 憑借其獨特的檢索增強生成架構,展現出了卓越的適應能力和實時更新優勢。通過持續從外部知識源中查詢并融合最新信息,RAG 能夠確保模型的輸出始終保持高度時效性,完全無需頻繁的重新訓練過程。
相比之下,傳統的 Fine-Tuning (微調)方法則面臨著更多的困難和局限性。由于微調后的模型實際上只是訓練數據的靜態快照,在高速變化的數據場景中,很快就會被動態信息所超越而過時失效。更為棘手的是,微調無法保證模型對知識的持久記憶和回憶能力,從而使其在特定任務上的表現難以可靠把控。
綜上所述,RAG 作為一種全新的語言模型架構,憑借其對動態外部信息的高度敏感性和融合能力,使其成為應對多變數據環境的不二之選。無論是確保輸出時效性,還是保證知識覆蓋的廣度和深度,RAG 都展現出了其獨特的優越性。
2. 外部知識融合
在智能語言時代,知識獲取的廣度和深度決定了模型的天花板。面對海量異構知識庫,RAG 以其超越者的氣概,為語言模型賦能于外部知識融合的非凡能力。
作為一種革命性的語言模型架構,RAG 被誕生于充分利用外部知識源的終極需求。它通過智能檢索機制,高效地從各類結構化、非結構化的知識庫中獲取與任務相關的信息,并將其與內部語義表征相融合,生成增強后的最終響應。無論是查詢數據庫、文檔,還是其他異構數據存儲庫,RAG 均能輕松駕馭,展現出卓越的外部知識利用能力。
反觀傳統的 Fine-Tuning (微調)方式,其知識獲取能力受到了諸多束縛。雖然通過微調,可以使大型語言模型"學習"特定領域的知識,但這種學習過程無法適應頻繁變化的外部數據源,并且每一次模型重新訓練,都需要付出極高的計算代價,效率顯著低下。更為關鍵的是,微調模型的知識種類和來源也受到了較大限制,難以全面獲取和利用互聯網上的異構海量知識。
綜上所述,對于高度依賴外部知識源、且知識存儲形式多變的應用場景而言,RAG 無疑是當前最具前景的解決方案。它為語言模型賦予了無與倫比的知識檢索與融合能力,輕松突破了傳統 Fine-Tuning (微調)方式的種種局限,讓模型的輸出質量和知識覆蓋面得到了極大的提升。
3. 幻覺減少
通常而言,RAG 系統的設計本質上可以降低其產生幻覺的可能性。這是因為 RAG 系統不是單純地根據生成模型的輸出生成響應,而是將每個響應都基于實際檢索到的證據進行構建。
具體來說,RAG 系統由兩個主要組件組成:一個檢索模塊和一個生成模塊。檢索模塊負責從大規模的知識庫中找到與輸入相關的信息片段。而生成模塊則根據這些檢索到的證據來生成最終的響應。
這種基于檢索的方式限制了模型單憑自身的生成能力來構造響應的可能性。相比于僅依賴生成模型的純粹生成式系統,RAG 需要嚴格遵循檢索到的事實性信息,從而降低了模型制造虛假或幻覺性響應的風險。
Fine-Tuning (微調)技術確實可以通過使用特定領域的訓練數據來幫助降低模型產生幻覺的可能性。因為微調過程可以使模型的參數更好地適應某個特定的應用場景或領域,從而減少模型在這些熟悉領域外產生虛假或無根據的響應。
然而,即使經過微調,模型在面對不熟悉的輸入或領域時,仍然可能會嘗試編造一些看似合理但實際上是虛假的反應。這是因為即使經過微調,模型的基本生成機制和推理能力并沒有根本性的改變。在缺乏足夠的相關訓練數據和背景知識的情況下,模型仍可能傾向于根據自身的推測或猜測來生成響應,而非嚴格基于事實。
因此,微調雖然可以在一定程度上緩解模型產生幻覺的傾向,但并不能完全消除這一風險。在使用微調后的模型時,仍需要格外謹慎,并結合其他技術手段,如增強模型的可解釋性,來進一步降低模型制造虛假信息的可能性。只有通過多管齊下,我們才能更好地確保模型在各種情況下都能給出可靠、事實性的響應。
4. 模型定制化需求
基于架構設計角度而言,RAG 主要專注于信息檢索,其設計可能無法根據檢索到的內容自動調整模型的語言風格或領域特定性。雖然 RAG 擅長將外部知識整合到生成過程中,但可能缺乏完全定制模型行為和寫作風格的能力。也就是說,RAG 系統更側重于利用豐富的背景知識來提升生成質量,而不是對模型本身進行深度定制。
相比之下, Fine-Tuning (微調)技術為調整大型語言模型的行為、寫作風格和領域專有知識提供了更直接的路徑。通過微調,我們可以使模型的行為、語氣和術語更貼合特定的應用需求和細節。這種針對性的定制能夠實現模型與特定風格或專業領域的深度融合。
因此,如果我們的應用程序需要專門的寫作風格或深度契合特定領域的詞匯和慣例,那么 Fine-Tuning (微調)技術無疑提供了更直接和有效的定制途徑。相比之下,雖然 RAG 系統擅長利用外部知識,但在定制模型的語言特性和行為方面可能存在一定局限性。
當然,RAG 和 Fine-Tuning (微調)并非完全互斥,在某些情況下可以結合使用以發揮各自的優勢。關鍵在于根據具體的應用需求,選擇最合適的定制技術來提升模型的性能和行為特性。無論采用哪種方法,合理的模型定制都是提升應用效果的關鍵所在。
5. 模型成本效益
在實際的業務場景中,RAG 系統本身并不支持使用更小型的模型。它需要依賴較大的基礎模型來執行信息檢索和生成任務,無法通過縮小模型規模來獲得成本優勢。
相比之下, Fine-Tuning (微調)技術可以在很大程度上提高小型模型的效率和性能。這意味著在部署和維護時,小型模型所需的硬件基礎設施更少,從而能夠帶來云計算開支或硬件采購方面的成本節省。
當成本考量成為首要因素時,訓練和部署小型模型能夠帶來顯著的成本優勢,特別是在大規模應用場景下。這是 Fine-Tuning (微調)技術的一大優勢。
與 RAG 系統需要依賴較大模型的限制相比, Fine-Tuning (微調)可以充分利用小型模型的優勢。通過精心的微調過程,小型模型可以在特定任務上展現出媲美甚至超越大型模型的性能。同時,小型模型的部署和維護成本也大幅降低。
因此,對于追求成本效益的應用場景而言, Fine-Tuning (微調)技術能夠充分發揮小型模型的優勢,為項目帶來顯著的經濟收益。這是 RAG 系統所無法提供的。簡而言之,在成本優先的情況下, Fine-Tuning (微調)方法顯然具有更強的優勢。
四、關于 Fine-Tuning vs RAG 一點見解
在語言人工智能的探索進程中,技術創新往往是一場場思想的碰撞與融合。而微調和檢索增強生成(RAG)這兩大范式,正是智能語言模型發展歷程中的里程碑式進展。但我們不應將其等同于一場"這一家喻戶曉或彼一家臭"的技術范式之爭,因為在更高的智能進化視角下,兩者實則是有機統一、相輔相成的共生體。

1.Fine-Tuning 微調:賦能語言模型任務專注的秘鑰
微調技術的核心功能,是通過對預訓練語言模型權重的精細調校,將其通用的語義認知能力定制化為某一特定任務或領域的專注技能。這種"通過少量數據開啟定制化"的高效方式,讓語言模型得以脫胎于通用知識的卵殼,孵化出應對特殊場景的專業能力。
2.RAG:外延語言模型認知邊界的知識加持
而檢索增強生成則是另一種智能范式,賦予了語言模型高效獲取和利用外部異構知識的能力。通過智能檢索系統,語言模型可在生成響應前,從海量專業知識庫中獲取與之相關的補充信息,從而突破了其受限于訓練數據集的知識邊界,使輸出更加準確、專業、內容豐富。
Reference :
- [1] https://ai.plainenglish.io/fine-tuning-vs-rag-in-generative-ai-64d592eca407
- [2] https://www.goml.io/rag-vs-finetuning-which-is-the-best-tool-for-llm-application/