













作者 | 崔皓
審校 | 重樓
摘要

在自然語言處理領域,為了讓模型能夠處理特定領域的問題,需要進行Fine-tuning,即在基礎模型上訓練模型以理解和回答特定領域的問題。在這個過程中,Embedding起到了關鍵作用,它將離散型的符號轉換為連續型的數值向量,幫助模型理解文本信息。詞嵌入是一種常用的Embedding方法,通過將每個單詞轉換為多維向量來捕獲其語義信息。本文通過LangChain,ChromaDB以及OpenAI實現Fine-tuning的過程,通過更新Embedding層來讓模型更好地理解特定領域的詞匯。
開篇
在自然語言處理領域,最常見的用例之一是與文檔相關的問題回答。雖然這方面ChatGPT已經做的足夠好了,但它也只能作為一個通才,如果需要了解更多專業領域的內容還需要進一步學習。 你可以想象一下將你所在領域的文檔,包括pdf、txt 或者數據庫中的信息教給模型, 讓模型也具備回答相關領域問題的能力。此時的模型就好像一個行業專家可以回答行業內的各種問題, 當然你需要喂給它大量的數據才能讓它飽讀詩書。
Fine-tuning
假設你正在使用一個預訓練的語言模型來建立一個電影推薦系統。這個語言模型已經在大量的文本數據上進行了訓練,因此它已經學會了理解和生成人類語言。但是,此時該模型并不知道和電影相關的事情,如果你希望這個模型能夠理解和回答有關電影的特定問題,例如“這部電影的評分是多少?”或“這部電影的主角是誰?”。
為了讓模型能夠處理這些特定的問題,你需要對模型進行Fine-tuning。具體來說,就是需要收集一些電影相關的問題和答案,然后使用這些數據來訓練模型。在訓練過程中,模型的參數(或者說“權重”)將會被稍微調整,以使模型更好地理解和回答這些電影相關的問題。這就是Fine-tuning的過程。
需要注意的是,Fine-tuning通常比從零開始訓練模型需要更少的數據和計算資源,因為預訓練的模型已經學會了許多基礎的語言知識。我們所做的Fine-tuning,只是在基礎知識添加相關電影的知識從而幫助模型完成處理電影問答的工作。
Embedding
有了上面的思路,我們知道如果讓一個通才變成我們需要的專才就需要對其進行專業知識的教學,這個就是Fine-tunning 要做的事情。 它在基礎的模型上面進行微調,告訴它更多的專業知識。這些專業的知識是以文本的形式存在,并保存到已經生成的模型庫中。
以電影專業為例,我們會將大量的電影相關的信息轉換成文本,然后將其保存到數據模型庫中。這也就意味著需要將文本的內容拆成一個個的單詞并對其進行保存。
這里我們就需要用到"Embedding", 它是將離散型的符號(比如單詞)轉換為連續型的數值向量的過程。在我們的電影推薦系統例子中,Embedding可以幫助模型理解電影名稱、演員名字、電影類型等文本信息。
例如,當我們談論電影或演員的名稱時,我們通常會使用詞嵌入(word embeddings)。這種嵌入可以把每一個單詞轉換為一個多維的向量,這個向量能捕獲該詞的語義信息。詞嵌入的一個重要特性是,語義相似的詞會被映射到向量空間中相近的位置。如圖1所示,“king,” “queen,” “man,” 和 “woman.”根據經驗直觀地理解這些詞之間的關系。例如,man在概念上比queen更接近king。所以我們將這些詞轉化為笛卡爾空間上的數據,以直觀的方式標注詞在空間中的關系。

但是這還不夠,我們還需要進一步衡量詞與詞之間的關系。從詞義上man和king會更加接近一些,對woman和queen也是這樣。于是,我們將坐標軸中的點變成向量,也就是有長度和方向的量。圖2 中,Man 和King 分別用黃色和藍色的向量線表示,它們形成的夾角就表示了它們之間的關系,這個角越小關系就更緊密。對于Woman 和Queen 來說也是如此。 因此,我們可以通過詞嵌入之后形成的向量夾角來測量詞與詞之間的關系。
說明:
在詞嵌入中,向量的"大小"通常指的是向量的長度,這是由向量的所有元素(或坐標)的平方和的平方根計算出來的。這是一個數學概念,與向量在幾何空間中的實際長度相對應。
然而,這個"大小"或"長度"在詞嵌入中通常沒有明確的語義含義。也就是說,一個詞的嵌入向量的長度并不能告訴我們關于這個詞的具體信息。例如,一個詞的嵌入向量的長度并不能告訴我們這個詞的重要性、頻率、情感等。
在創建詞嵌入時,我們通常不會直接定義向量的大小。相反,向量的大小是由嵌入模型(如Word2Vec或GloVe)在學習過程中自動確定的。這個過程通常是基于大量的文本數據,并考慮到詞語在文本中的上下文信息。
在某些情況下,我們可能會對詞嵌入向量進行歸一化,使得每個向量的長度都為1。這樣做的目的通常是為了消除向量長度的影響,使得我們可以更純粹地比較向量之間的角度,從而衡量詞語之間的語義相似性。
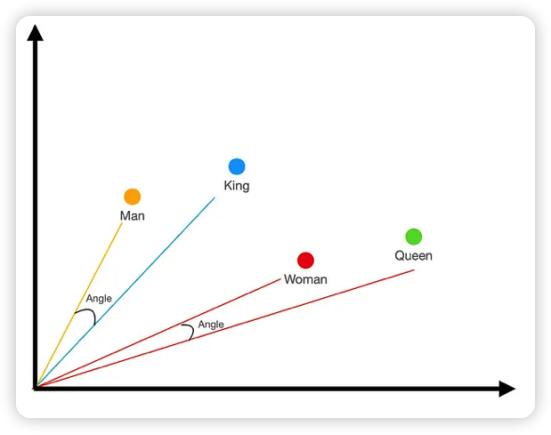 圖2
圖2
實際上在將專業知識不斷更新到模型庫的過程就是Fine-tuning,在更新過程中需要將詞保存到模型的操作就是Embedding。此時,模型的Embedding層會因為Fine-tuning 而被更新。例如,如果預訓練的模型是在通用的文本數據上訓練的,那么它可能并不完全理解電影相關的一些專有名詞或者俚語。在Fine-tuning過程中,我們可以通過更新Embedding層來讓模型更好地理解這些電影相關的詞匯。
需要注意的是,雖然我們有時候會在Fine-tuning過程中更新Embedding層,但不是必須的。如果預訓練的模型已經有很好的詞嵌入,并且新任務的數據不夠多,我們可能會選擇凍結(即不更新)Embedding層,只更新模型的其他部分,以防止模型在小型數據集上過擬合。
假設你正在使用一個預訓練的模型來識別各種影片。你的預訓練模型可能是在數百萬條影片信息上訓練而來的,由于訓練的數據足夠大,模型已經識別各種影片。然而,你想要使用這個模型來識別特定種類的影片,比如說文藝片和紀錄片。
此時,你需要對模型進行Fine-tuning,但是,你手上的文藝片和記錄片的訓練集只有幾百條,這比預訓練模型的幾百萬相差很大, Embedding 的效果就不會太好了。
此時,需要"凍結"模型的Embedding層。這個層已經在預訓練過程中學會了如何從眾多影片信息中提取有用的電影特征。如果執意進行Fine-tuning,并Embedding你手上的 幾百條信息,模型可能會過度適應小型數據集,導致其在未見過的數據上表現不佳。這就是我們所說的過擬合。
如何進行我們的Fine-tuning 和Embedding
有了上面的概念,我們需要確定創建自己專業模型的思路。首先,需要有一個預處理的模型,就是一個已經被別人訓練好的LLM(大語言模型),例如OpenAI的GPT-3等。有了這個LLM之后,把我們的專業知識(文本)Embedding 到其中形成新的模型就齊活了。
為了達到上面的目的,我們使用了LangChain作為管理和創建基于LLMs的應用程序的工具。LangChain是一個軟件開發框架,旨在簡化使用大型語言模型(LLMs)創建應用程序的過程。作為一個語言模型集成框架,LangChain的使用案例大致與一般的語言模型重合,包括文檔分析和摘要,聊天機器人和代碼分析。
說明:
LangChain于2022年10月作為一個開源項目由Harrison Chase在機器學習初創公司Robust Intelligence工作時發起。該項目迅速獲得了人氣,GitHub上有數百名貢獻者進行了改進,Twitter上有熱門討論,項目的Discord服務器活動熱烈,有許多YouTube教程,以及在舊金山和倫敦的見面會。這個新的初創公司在宣布從Benchmark獲得1000萬美元的種子投資一周后,就從風投公司Sequoia Capital籌集了超過2000萬美元的資金,公司估值至少為2億美元。
有了處理LLM的工具,那么再找個LLM 讓我們在上面 Fine-tuning 就好了。 我們選擇了Chroma,它是一個開源的嵌入式數據庫。如圖3所示,Chroma通過使知識、事實和技能可以輕松地為大型語言模型(LLMs)插入信息,從而簡化了LLM應用的構建。它可以存儲嵌入和元數據,嵌入文檔和查詢,搜索嵌入式。我們會使用ChromaDB作為向量庫,用來保存Embedding 的信息。
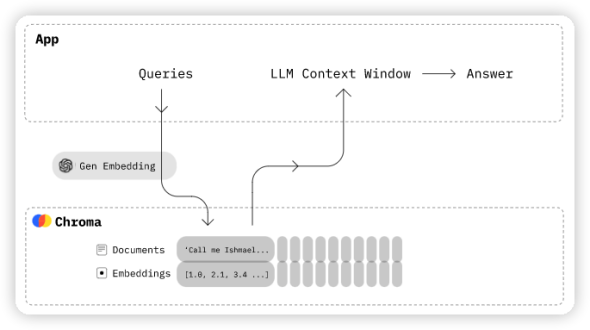 圖3
圖3
當然還需要OpenAI 提供的預處理模型,將文本轉化為機器可以理解的向量形式,方便Embedding。
這個編程環境我使用了CoLab,Google Colab(全名為Google Colaboratory)是一個由Google提供的免費云端Jupyter Notebook環境。用戶可以在其中編寫和執行Python代碼,無需進行任何設置,僅需要一個Google帳戶即可使用。Google Colab被廣泛用于數據分析、機器學習、深度學習等領域。它還提供了免費的計算資源:包括CPU,GPU,甚至TPU(Tensor Processing Units)。這樣就省去了我安裝Python 的煩惱,打開網頁就可以直接使用。
開始編碼
首先,需要安裝一些庫。需要Langchain和OpenAI來實例化和管理LLMs。
每個命令的含義如下:
pip install langchain
pip install openai
pip install chromadb
pip install tiktoken上面的代碼主要是安裝各種工具:
- pip install langchain:安裝Langchain庫。
- pip install openai:安裝OpenAI庫。OpenAI庫提供了一個Python接口,用于訪問OpenAI的各種API,包括用于生成文本的GPT-3等模型的API。
- pip install chromadb:安裝ChromaDB庫。ChromaDB是一個開源的嵌入數據庫,它提供了存儲和搜索嵌入向量的功能。
- pip install tiktoken:安裝TikToken庫。TikToken是OpenAI開發的一個庫,它能夠用于分析如何計算一個給定文本的token數量。這里的token是用來記錄Embedding中字、詞或者句子的個數。
接著,需要一個文本文件,也就是我們需要教模型學習的內容。這里可以通過網絡獲取,為了方便,我就手動寫了幾個字符串,用作測試。
import requests
#text_url = '【輸入你的文本的網絡地址】'
#response = requests.get(text_url)
#data = response.text
data="Bob likes blue. Bob is from China."接著,我們導入需要的類。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma導入了`OpenAIEmbeddings`,用于獲取OpenAI大型語言模型生成的詞向量(或者句向量)。
導入了`CohereEmbeddings`,用于獲取Cohere大型語言模型生成的詞向量(或者句向量)。Cohere是一個提供預訓練語言模型服務的公司。
導入了`CharacterTextSplitter`,用于將文本按照字符進行切割。
導入了`ElasticVectorSearch`,用于在Elasticsearch中進行向量搜索。
導入了`Chroma`,用于操作ChromaDB。
總的來說,是導入一些處理文本、獲取和存儲詞向量、以及進行向量搜索的工具。
接著將導入的文本進行處理,主要是將我們輸入的文本轉換成向量,并且保存到ChromaDB的向量庫中。我將代碼的含義通過注釋的方式展示如下:
import openai
#將你的OpenAI API的密鑰存儲在變量myApiKey中
myApiKey = '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'
#創建了一個CharacterTextSplitter的實例,這是一個用于將文本分割成較小部分的工具
text_splitter = CharacterTextSplitter()
#使用text_splitter將輸入的文本data分割成較小的部分,并將這些部分存儲在變量texts中。
texts = text_splitter.split_text(data)
print(texts)
#創建了一個OpenAIEmbeddings的實例,用于獲取OpenAI大型語言模型生成的詞向量(或者句向量)。
embeddings = OpenAIEmbeddings(openai_api_key=myApiKey)
persist_directory = 'db'
#使用ChromaDB創建了一個文本的詞向量數據庫。它將texts中的文本部分轉換為詞向量,然后將這些詞向量和相應的元數據存儲在指定的持久化目錄中。
docsearch = Chroma.from_texts(
texts,
embeddings,
persist_directory=persist_directory,
metadatas=[{"source":f"{i}-pl"} for i in range(len(texts))]
)既然上面的代碼將我們的文本Embedding到項目庫中了,那么當我們提問的時候就可以從這個庫中讀取相關的信息。下面的代碼使用LangChain庫構建一個檢索型問答(Retrieval-based Question Answering)系統,然后使用這個系統來回答一個特定的問題。
#從LangChain庫中導入了RetrievalQAWithSourcesChain類,這是一個用于構建檢索型問答系統的類。
from langchain.chains.qa_with_sources.retrieval import RetrievalQAWithSourcesChain
#創建了一個RetrievalQAWithSourcesChain的實例,即一個檢索型問答系統。該系統使用OpenAI的大型語言模型(設置了溫度參數為0)進行問答,使用Retriever進行信息檢索,并且設置了返回來源文檔的選項。
chain = RetrievalQAWithSourcesChain.from_chain_type(
llm = OpenAI(openai_api_key=myApiKey,temperature=0),
chain_type="stuff",
retriever = retriever,
return_source_documents = True
)
#一個函數,用于處理問答系統返回的結果。該函數會打印出答案以及來源文檔。
def process_result(result):
print(result['answer'])
print("\n\n Sources: ", result['sources'])
print(result['sources'])
#提出問題
question = '鮑勃喜歡什么顏色'
#使用定義的問答系統來回答問題,并將結果存儲在result變量中
result = chain({"question":question})
#調用定義的函數來處理并打印問答結果。
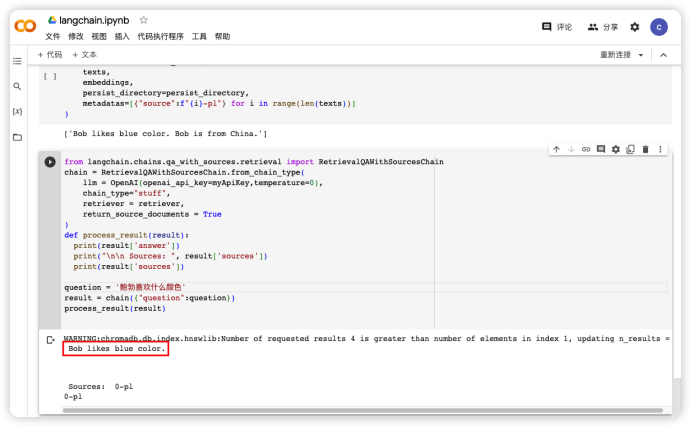
process_result(result)執行上面的代碼得到如圖4 結果。可以看到我們輸入的文本“Bob likes blue color”被作為答案回應了我們的提問。
整體代碼清單
pip install langchain
pip install openai
pip install chromadb
pip install tiktoken
import requests
#text_url = '【輸入你的文本的網絡地址】'
#response = requests.get(text_url)
#data = response.text
data="Bob likes blue. Bob is from China."
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
import openai
#將你的OpenAI API的密鑰存儲在變量myApiKey中
myApiKey = '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'
#創建了一個CharacterTextSplitter的實例,這是一個用于將文本分割成較小部分的工具
text_splitter = CharacterTextSplitter()
#使用text_splitter將輸入的文本data分割成較小的部分,并將這些部分存儲在變量texts中。
texts = text_splitter.split_text(data)
print(texts)
#創建了一個OpenAIEmbeddings的實例,用于獲取OpenAI大型語言模型生成的詞向量(或者句向量)。
embeddings = OpenAIEmbeddings(openai_api_key=myApiKey)
persist_directory = 'db'
#使用ChromaDB創建了一個文本的詞向量數據庫。它將texts中的文本部分轉換為詞向量,然后將這些詞向量和相應的元數據存儲在指定的持久化目錄中。
docsearch = Chroma.from_texts(
texts,
embeddings,
persist_directory=persist_directory,
metadatas=[{"source":f"{i}-pl"} for i in range(len(texts))]
)
#從LangChain庫中導入了RetrievalQAWithSourcesChain類,這是一個用于構建檢索型問答系統的類。
from langchain.chains.qa_with_sources.retrieval import RetrievalQAWithSourcesChain
#創建了一個RetrievalQAWithSourcesChain的實例,即一個檢索型問答系統。該系統使用OpenAI的大型語言模型(設置了溫度參數為0)進行問答,使用Retriever進行信息檢索,并且設置了返回來源文檔的選項。
chain = RetrievalQAWithSourcesChain.from_chain_type(
llm = OpenAI(openai_api_key=myApiKey,temperature=0),
chain_type="stuff",
retriever = retriever,
return_source_documents = True
)
#一個函數,用于處理問答系統返回的結果。該函數會打印出答案以及來源文檔。
def process_result(result):
print(result['answer'])
print("\n\n Sources: ", result['sources'])
print(result['sources'])
#提出問題
question = '鮑勃喜歡什么顏色'
#使用定義的問答系統來回答問題,并將結果存儲在Result變量中
result = chain({"question":question})
#調用定義的函數來處理并打印問答結果。
process_result(result)最后的思考
在自然語言處理領域,為了讓模型能夠處理特定領域的問題,需要進行Fine-tuning,并利用Embedding方法將文本信息轉換為數值向量。這樣的過程使得模型能夠具備特定領域的專業知識,從而能夠回答相關問題。詞嵌入是一種常用的Embedding方法,通過將單詞轉換為多維向量來捕獲其語義信息。在Fine-tuning過程中,我們可以更新Embedding層來增強模型對特定領域詞匯的理解能力。整個過程需要借助工具和庫來實現,如LangChain和ChromaDB。通過這樣的流程,我們可以建立一個專業領域的問答系統,提供準確的答案和相關的來源文檔。
作者介紹
崔皓,51CTO社區編輯,資深架構師,擁有18年的軟件開發和架構經驗,10年分布式架構經驗。





























