PVTransformer: 可擴展3D檢測的點到體素Transformer
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
原標題:PVTransformer: Point-to-Voxel Transformer for Scalable 3D Object Detection
論文鏈接:https://arxiv.org/pdf/2405.02811
作者單位:Waymo Research

論文思路:
點云的3D目標檢測器通常依賴于基于池化的PointNet [20],將稀疏點編碼成類似網格的體素或 pillars。本文識別出常見的PointNet設計引入了一個信息瓶頸,限制了3D目標檢測的準確性和可擴展性。為了解決這一限制,本文提出了PVTransformer:一種基于Transformer的點到體素架構用于3D檢測。本文的關鍵思想是用注意力模塊替換PointNet的池化操作,從而實現更好的點到體素聚合函數。本文的設計尊重稀疏3D點的置換不變性,同時比基于池化的PointNet更具表現力。實驗結果顯示,本文的PVTransformer在性能上比最新的3D目標檢測器有顯著提升。在廣泛使用的Waymo Open Dataset上,本文的PVTransformer達到了76.5 mAPH L2的最新水平,超越了之前的SWFormer [27] +1.7 mAPH L2。
主要貢獻:
新架構:引入了一種基于注意力的點-體素架構,即PVTransformer,旨在解決PointNet的池化限制問題。
新穎的擴展研究:啟動對基于Transformer的3D檢測器架構可擴展性的探索。
廣泛研究:通過廣泛的架構搜索,本文展示了所提出的PVTransformer架構的有效性,其在Waymo Open Dataset上達到了76.5 mAPH L2的最新水平。
網絡設計:
在城市環境中的自動駕駛3D目標檢測需要處理大量稀疏且無序的點,這些點散布在開放的三維空間中。為了管理點的不規則分布,現有方法將點聚合成二維或三維體素表示 [35],利用PointNet類型的特征編碼器 [20] 將點特征聚合到體素中,隨后通過主干網絡和檢測頭進行處理。然而,現有的點架構往往被忽視,并因其簡約設計而受到限制,即少數幾個全連接層后跟一個最大池化層。正如原始論文 [20] 所強調的,PointNet類型模塊的關鍵在于最大池化層,它從無序點中提取信息并作為聚合函數。盡管利用了眾多全連接層進行特征提取,但體素內所有點的特征通過一個簡單的池化層進行組合。本文觀察到,3D目標檢測中的普通池化操作引入了信息瓶頸,阻礙了現代3D目標檢測器的性能。與圖像識別中的標準2D最大池化不同,后者作用于有限的像素集,3D檢測器中的點-體素池化層必須聚合大量無序點。例如,在Waymo Open Dataset [26] 中,常見一個0.32m × 0.32m的體素中有超過100個點,這些點被池化成一個單一的體素特征向量。這導致了在池化層之后點特征的顯著信息損失。
為了解決基于池化的PointNet架構的局限性,本文引入了PVTransformer,這是一種基于Transformer [29] 的新型注意力點-體素架構,用于3D目標檢測。PVTransformer的目標是通過注意力模塊端到端學習點到體素的編碼函數,以緩解現代3D目標檢測器中由于池化操作引入的信息瓶頸。在PVTransformer中,每個體素中的每個點被視為一個token,并使用單個查詢向量來查詢所有點tokens,從而聚合并編碼體素內所有點特征到單一的體素特征向量中。PVTransformer中的基于注意力的聚合模塊作為一個集合操作符(set operator),保持了排列不變性,但比最大池化更具表現力。值得注意的是,與其他基于Transformer的點網絡如Point Transformer [32] 使用池化來聚合點不同,PVTransformer旨在學習特征聚合函數,而無需依賴啟發式的池化操作。
本文在Waymo Open Dataset上評估了PVTransformer,這是目前最大的公開3D點云數據集 [26]。實驗結果表明,PVTransformer通過改進點到體素的聚合,顯著優于之前基于PointNet的3D目標檢測器。此外,PVTransformer使本文能夠擴展模型,實現了新的最先進水平:在車輛和行人檢測中分別達到了76.1 mAPH L2和85.0/84.7 AP L1。值得注意的是,本文的體素主干網絡和損失設計主要基于先前的SWFormer [27],但本文新提出的點到體素Transformer相比基線SWFormer提高了+1.7 mAPH L2。

圖1:PVTransformer(PVT)作為一種可擴展的架構。PVTransformer解決了之前基于體素的3D檢測器中的池化瓶頸,并展示了相較于擴展PointNet(Scale Point)和體素架構(Scale Voxel)更好的可擴展性。每個點的大小表示模型的Flops。更多細節請參見圖4和圖5。

圖2:PVTransformer架構概述。PVTransformer架構包含點架構和體素架構。其創新之處在于點架構,用一種新穎的Transformer設計替代了PointNet。在點架構中,點被分組到pillars內,每個pillars被視為一個token。在一個體素內,點首先經過自注意力Transformer,然后通過交叉注意力Transformer將點特征聚合為體素特征,詳細信息見圖3(b)。稀疏的BEV體素特征隨后進入體素架構,采用多尺度稀疏窗口Transformer(SWFormer Block)[27]進行編碼,并使用CenterNet頭進行邊界框預測[31]。

圖3:PVTransformer中的點到體素聚合。該模塊使用Transformer層替代了PointNet的最大池化[20]。
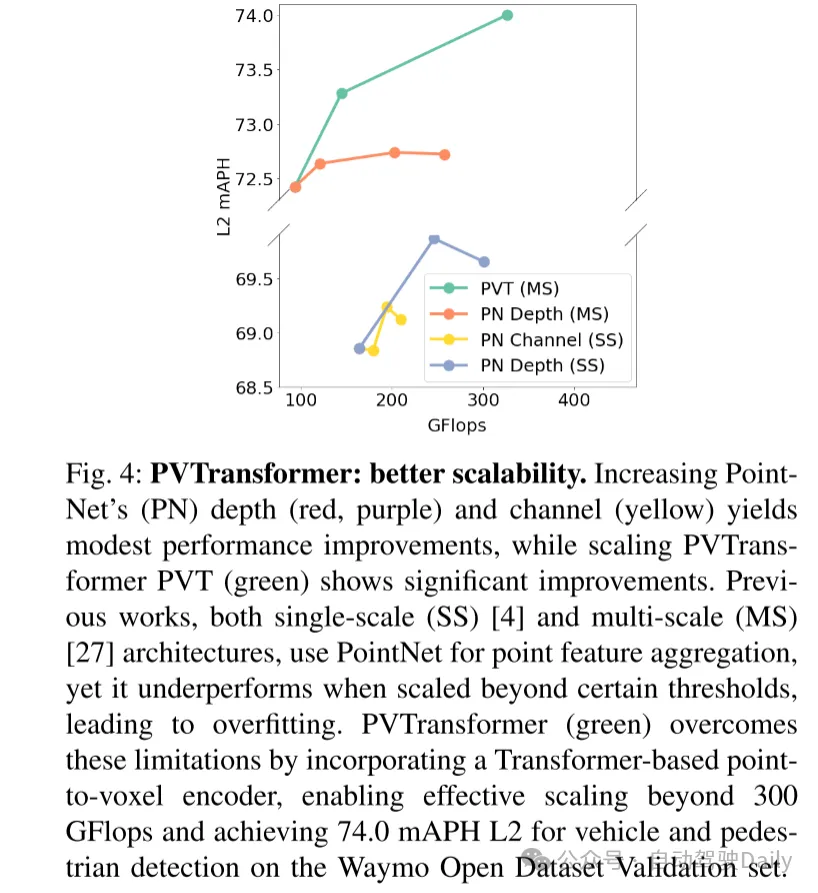
圖4:PVTransformer:更好的可擴展性。增加PointNet(PN)的深度(紅色,紫色)和通道(黃色)僅帶來適度的性能提升,而擴展PVTransformer PVT(綠色)則顯示出顯著的性能提升。之前的工作中,無論是單尺度(SS)[4]還是多尺度(MS)[27]架構,都使用PointNet進行點特征聚合,但在超過某些閾值時性能不佳,導致過擬合。PVTransformer(綠色)通過引入基于Transformer的點到體素編碼器,克服了這些限制,使其能夠有效擴展超過 300 GFlops,并在Waymo Open Dataset驗證集上實現了車輛和行人檢測的74.0 mAPH L2。

圖5:當使用PointNet(PN)來聚合點特征時,體素架構的可擴展性有限。右圖:使用Transformer來聚合點特征(PVT L)(綠色)顯著優于使用PointNet并僅在體素架構中將通道擴展到256(藍色),在相似的Flops下提高了3.5 mAPH L2。左圖:從搜索空間(見表V)中隨機采樣的體素架構在訓練12.8個epoch后的性能表現。本文觀察到,使用PointNet擴展體素架構可能導致次優性能。帕累托曲線(紅色曲線)顯示,將體素架構的通道數從128擴展到192和256會導致過擬合。在Waymo Open Dataset驗證集上報告了車輛和行人的mAPH L2。
實驗結果:

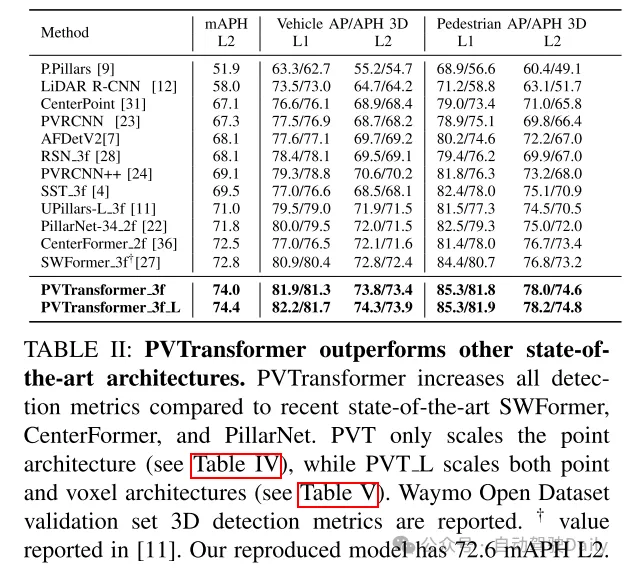




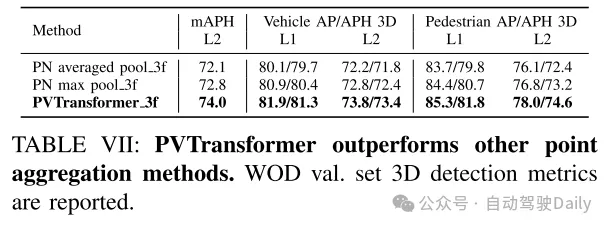
總結:
本文旨在為大規模3D目標檢測器實現更好的可擴展性,并發現基于池化的PointNet為現代3D目標檢測器引入了信息瓶頸。為了解決這一限制,本文提出了一個新的PVTransformer架構,該架構使用基于注意力機制的Transformer將點特征聚合到體素特征中。本文證明了這種點到體素的Transformer比簡單的PointNet池化層更具表現力,因此在性能上遠遠超過了以往的3D目標檢測器。本文的PVTransformer顯著優于之前的技術,如SWFormer,并在具有挑戰性的Waymo Open Dataset上實現了新的最先進的結果。