模塊化重構LLaVA,替換組件只需添加1-2個文件,開源TinyLLaVA Factory來了
TinyLLaVA 項目由清華大學電子系多媒體信號與智能信息處理實驗室 (MSIIP) 吳及教授團隊和北京航空航天大學人工智能學院黃雷老師團隊聯袂打造。清華大學 MSIIP 實驗室長期致力于智慧醫療、自然語言處理與知識發現、多模態等研究領域。北航團隊長期致力于深度學習、多模態、計算機視覺等研究領域。
近日,清華和北航聯合推出了 TinyLLaVA Factory, 一款支持定制、訓練、評估多模態大模型的代碼庫,代碼和模型全部開源。該代碼庫以軟件工程的工廠模式作為設計理念,模塊化地重構了 LLaVA 代碼庫,注重代碼的可讀性、功能的擴展性、和實驗效果的可復現性。方便研究者和實踐家們更容易地探索多模態大模型的訓練和設計空間。

- Github 項目:https://github.com/TinyLLaVA/TinyLLaVA_Factory
- 論文地址:https://arxiv.org/abs/2405.11788
- Hugging Face 模型地址:https://huggingface.co/tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B or https://huggingface.co/bczhou/TinyLLaVA-3.1B-SigLIP
- 機器之心 SOTA 模型地址:https://sota.jiqizhixin.com/project/tinyllava
LLaVA 作為多模態社區的優質開源項目,備受研究者和開發者的青睞;新入坑多模態大模型的初學者們也習慣以 LLaVA 項目作為起點,學習和訓練多模態大模型。但是 LLaVA 項目的代碼較為晦澀難懂,一旦不慎更改錯誤,就可能會影響訓練效果,對于新手來說,往往不敢輕易修改其中的細節,給理解和探索多模態大模型的本質細節造成了一定的困難。
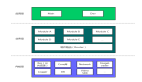
近日,清華和北航聯合推出 TinyLLaVA Factory,將本來的 LLaVA 代碼進行模塊化重構,專注于簡潔的代碼實現、新功能的可擴展性、以及訓練結果的可復現性,讓你以最小的代碼量,定制并訓練屬于自己的多模態大模型,同時減少代碼錯誤率!相同的模型配置、訓練數據和訓練策略條件下,使用 TinyLLaVA Factory 可訓練出比用 LLaVA 代碼性能略勝一籌的模型。為了讓用戶更容易地讀懂代碼和使用模型,TinyLLaVA Factory 項目還配備了代碼文檔和 Demo 網站。其總體架構圖如下。

數據預處理部分,TinyLLaVA Factory 摒棄了 LLaVA 代碼中燒腦的圖片處理和 Prompt 處理過程,提供了標準的、可擴展的圖片和文本預處理過程,清晰明了。其中,圖片預處理可自定義 Processor,也可使用一些官方視覺編碼器的 Processor,如 CLIP ViT 和 SigCLIP ViT 自帶的 Image Processor。對于文本預處理,定義了基類 Template,提供了基本的、共用的函數,如添加 System Message (Prompt)、Tokenize、和生成標簽 Ground Truth 的函數,用戶可通過繼承基類就可輕松擴展至不同 LLM 的 Chat Template。


模型部分,TinyLLaVA Factory 很自然地將多模態大模型模塊化成 3 個組件 —— 大語言模型組件、視覺編碼器組件、中間的連接器組件。每個組件由一個工廠對象控制,負責新模型的注冊和替換,使用戶能夠更容易地替換其中任何一個組件,而不會牽連到其他部分。

TinyLLaVA Factory 為每個組件提供了當前主流的模型,如下表所示。

訓練器仍然仿照 LLaVA,采取 Hugging Face 自帶的 Trainer,集成了 Gradient Accumulation,Wandb 做日志記錄等特性,同樣支持 DeepSpeed ZeRO2/ZeRO3 并行訓練。對于評估部分,TinyLLaVA Factory 提供了 SQA/GQA/TextVQA/VQAv2/POPE/MME/MM-Vet/MMMU 8 個 Benchmark 的評估。
接下來,劃重點!TinyLLaVA Factory Github 項目還手把手教你定制自己的多模態大模型。只需簡單地添加 1-2 個文件,就可以輕松替換 LLM 組件、視覺編碼器組件、連接器組件。
拿替換 LLM 模型舉例。據使用過 LLaVA 代碼庫的同學反應,LLaVA 代碼想替換非 Llama 系列的語言模型容易出錯。而 TinyLLaVA Factory 可以方便地替換語言模型,只需添加 2 個 py 文件,一個是 Chat Template 文件,一個是模型文件。替換視覺編碼器時,也只需添加 1 個 py 文件,繼承視覺編碼器的基類即可。

TinyLLaVA Factory 還支持對訓練策略進行定制,對使用者來說只需在配置文件中進行修改,就能在 pretraining 和 finetuning 階段對 3 個模塊組件(LLM / 視覺編碼器 / 連接器)實現凍住 / 全量微調 / 部分微調 /lora 微調的任意組合。堪稱小白易上手式的教程!

早在今年 2 月,TinyLLaVA 項目就敏銳地捕捉到了 3B 以下 LLM 在多模態大模型中的潛力,利用市面主流的小規模 LLM,訓練了一系列多模態大模型,參數量在 0.89B-3.1B。實驗結果表明經過高質量的數據選擇和更加細致的訓練策略,利用小規模 LLM 同樣可以實現和大模型相近甚至更加優越的任務表現。(細節詳見技術報告 https://arxiv.org/abs/2402.14289)