













LLaVA-Mini來了!每張圖像所需視覺token壓縮至1個,兼顧效率內存
以 GPT-4o 為代表的實時交互多模態大模型(LMMs)引發了研究者對高效 LMM 的廣泛關注。現有主流模型通過將視覺輸入轉化為大量視覺 tokens,并將其嵌入大語言模型(LLM)上下文來實現視覺信息理解。然而,龐大的視覺 token(vision token)量顯著增加了 LMMs 的計算復雜度和推理延遲,尤其在高分辨率圖像或視頻處理的場景下,效率問題愈加突出。因此,提高多模態大模型的計算效率成為實現低延時實時交互的核心挑戰之一。
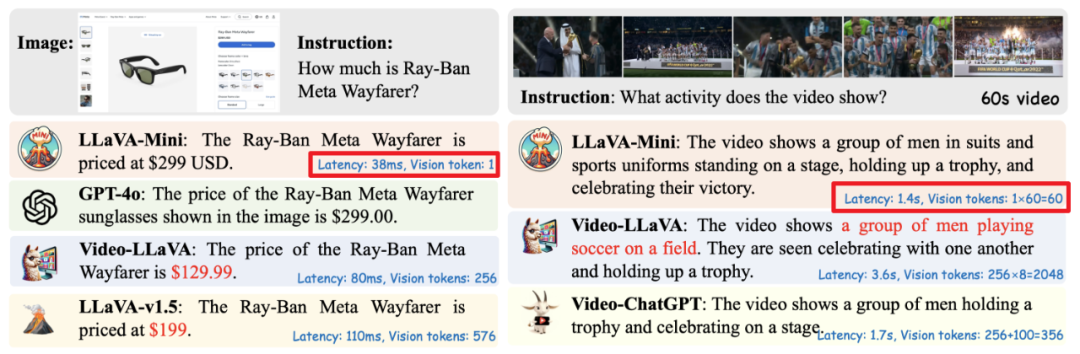
為了應對這一挑戰,中國科學院計算技術研究所自然語言處理團隊創新性的提出了高效多模態大模型 ——LLaVA-Mini。通過對 LMMs 中視覺 tokens 處理過程的可解釋性分析,LLaVA-Mini 將每張圖像所需的視覺 tokens 壓縮至 1 個,并在確保視覺理解能力的同時顯著提升了圖像和視頻理解的效率,包括:計算效率提升(FLOPs 減少 77%)、響應時延降低(響應延時降至 40 毫秒)、顯存占用減少(從 360 MB / 圖像降至 0.6MB / 圖像,支持 24GB GPU 上進行長達 3 小時的視頻處理)。

- 論文題目:LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token
- 論文鏈接:https://arxiv.org/abs/2501.03895
- 開源代碼:https://github.com/ictnlp/LLaVA-Mini
- 模型下載:https://huggingface.co/ICTNLP/llava-mini-llama-3.1-8b
多模態大模型如何理解視覺 Tokens?
為了在減少視覺 token 的同時保持視覺理解能力,研究者首先分析了 LMMs 如何處理和理解大量視覺 token。分析集中在 LLaVA 架構,特別從注意力機制的角度探討了視覺 token 的作用及其數量對 LMMs 性能的影響。具體而言,實驗評估了視覺 token 在 LMMs 不同層中的重要性,涵蓋了多種 LMMs,以識別不同規模和訓練數據集的模型之間的共性。

視覺 token 在 LMMs 不同層中獲取的注意力權重

LMMs 中不同層的注意力可視化
分析發現:
1. 視覺 token 在前幾層中的重要性較高:在 LMMs 的前幾層,視覺 token 獲得了更多的注意力,但隨著層數增加,注意力迅速轉向指令 token(文本),超過 80% 的注意力集中在指令 token 上。這表明,視覺 token 主要在前層發揮作用,文本 token 通過注意力機制從視覺 token 中獲取視覺信息,而后續層則依賴于已經融合視覺信息的指令 token 來生成回復。
2. 大部分視覺 token 在前幾層中被關注:如上圖注意力可視化所示,早期層中幾乎所有視覺 token 都受到均勻關注,而在后期層,模型則集中注意力于少數幾個視覺 token。這表明,直接減少所有層中的視覺 token 數量不可避免地會導致視覺信息的丟失。
更多分析請參考論文。通過預先分析,研究者發現視覺 token 在 LMMs 的早期層中起著至關重要的作用,在這一階段,文本 token 通過關注視覺 token 融合視覺信息。這一發現為 LLaVA-Mini 極限壓縮視覺 token 的策略提供了重要的指導。
LLaVA-Mini 介紹
LLaVA-Mini 使用視覺編碼器將圖像編碼為若干視覺 token。為了提升效率,LLaVA-Mini 通過壓縮模塊大幅減少輸入 LLM 底座的視覺 token 數量。為了在壓縮過程中保留視覺信息,基于先前的研究發現,視覺 token 在早期層中對于融合視覺信息至關重要,LLaVA-Mini 在 LLM 底座之前引入了模態預融合模塊,將視覺信息融入文本 token 中,從而確保視覺理解能力。
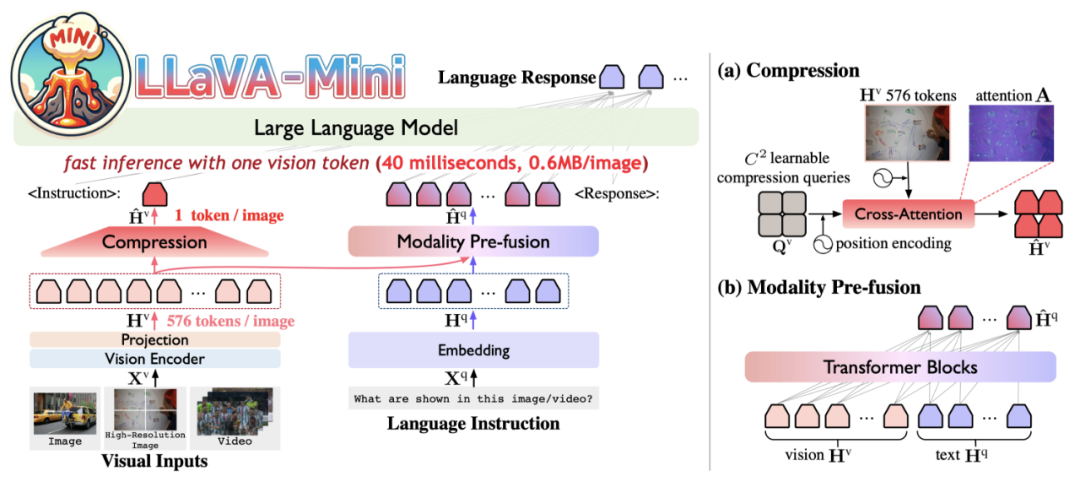
視覺 token 壓縮
LLaVA-Mini 通過基于查詢的壓縮模塊(query-based compression)減少輸入 LLM 底座的視覺 token 數量。為學習視覺 token 的壓縮,LLaVA-Mini 引入若干可學習的壓縮查詢(query),通過交叉注意力機制與所有視覺 token 交互,選擇性提取關鍵的視覺信息,生成壓縮后的視覺 token。當壓縮查詢數量為 1 時,LLaVA-Mini 僅用一個視覺 token 表示一張圖像。
模態預融合
視覺 token 的壓縮不可避免地會丟失部分視覺信息。為了在壓縮過程中盡可能保留更多的視覺信息,LLaVA-Mini 在 LLM 底座前引入模態預融合模塊,文本 token 預先融合來自所有視覺 token 的相關視覺信息。基于之前的發現,視覺文本信息融合通常發生在 LLM 底座的早期層,而 LLaVA-Mini 將這種融合過程顯示地提取到 LLM 外部進行,從而減少計算量。
最終,LLaVA-Mini 將輸入 LLM 底座的 token 數量從 “576 個視覺 token+N 個文本 token” 壓縮至 “1 個視覺 token+ N 個模態融合 token”。通過此,LLaVA-Mini 能夠更高效地完成圖像理解和視頻理解。
實驗結果
在本文的實驗中,研究者在 11 個圖像理解基準和 7 個視覺理解基準上評估了 LLaVA-Mini 的性能以及效率優勢,以下是所得的關鍵實驗結果。
圖像理解評估
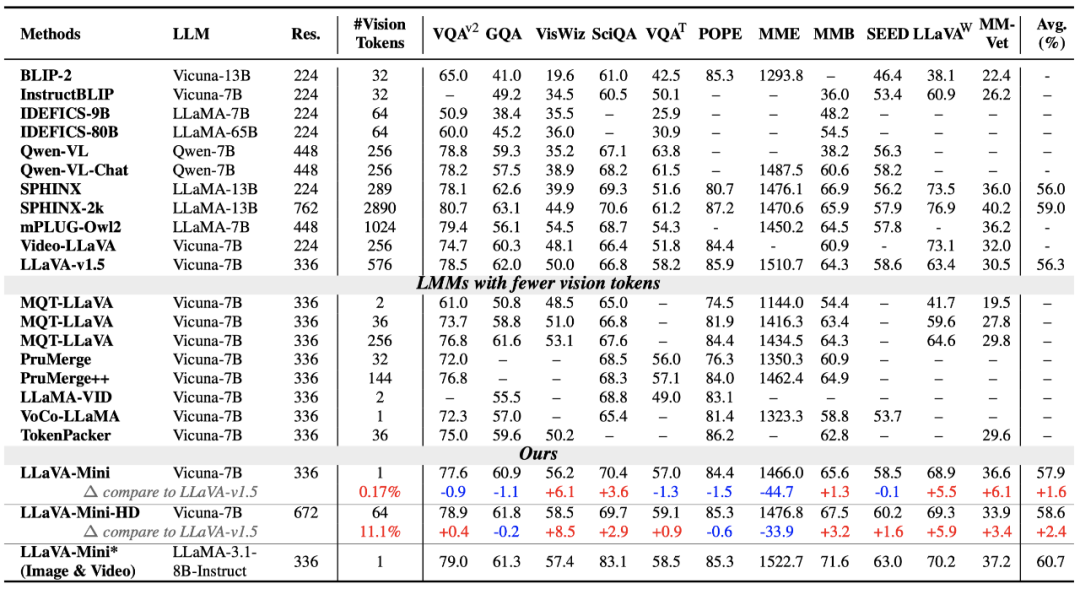
如上表所示,研究者在 11 個基準測試上比較了 LLaVA-Mini 和 LLaVA-v1.5。結果表明,LLaVA-Mini 僅使用 1 個視覺 token(壓縮率 0.17%),遠低于 LLaVA-v1.5 的 576 個視覺 token,取得與 LLaVA-v1.5 相當的圖像理解能力。
視頻理解評估
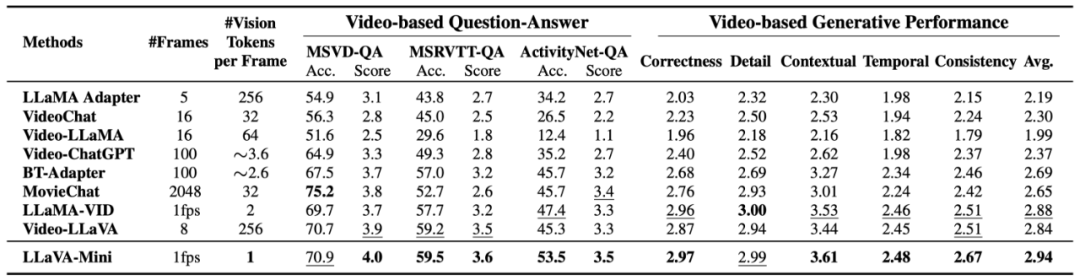
如上表所示,LLaVA-Mini 在視頻理解上優于目前先進的視頻 LMMs。這些視頻 LMMs 使用大量視覺 token 表示每幀(224 或 576),受限于上下文長度,僅能提取 8-16 幀,可能導致部分視頻信息丟失。相比之下,LLaVA-Mini 通過 1 個視覺 token 表示每張圖像,能夠以每秒 1 幀的速度提取視頻幀,從而在視頻理解上表現更佳。
長視頻理解評估
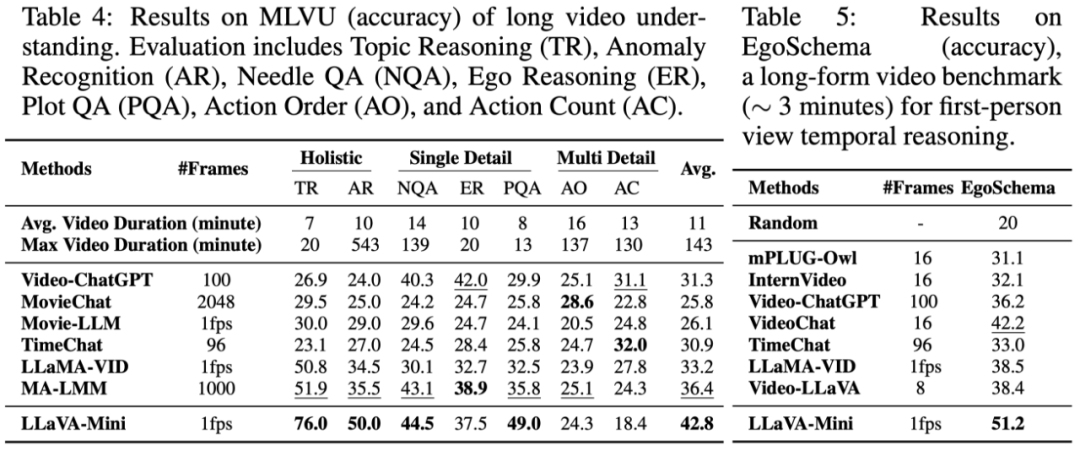
研究者進一步將 LLaVA-Mini 與先進的長視頻 LMMs(能夠處理超過 100 幀的視頻)在長視頻基準 MLVU 和 EgoSchema 上進行比較。
如上表所示,LLaVA-Mini 在長視頻理解上具有顯著優勢。通過將每幀表示為一個視覺 token,LLaVA-Mini 在推理時能夠輕松擴展到更長的視頻,并且通過 token 之間的位置編碼隱式建模時序關系。特別地,LLaVA-Mini 僅在少于 1 分鐘(< 60 幀)的視頻上進行訓練,且在推理時能夠處理超過 2 小時(> 7200 幀)的長視頻。
LLaVA-Mini 效率提升
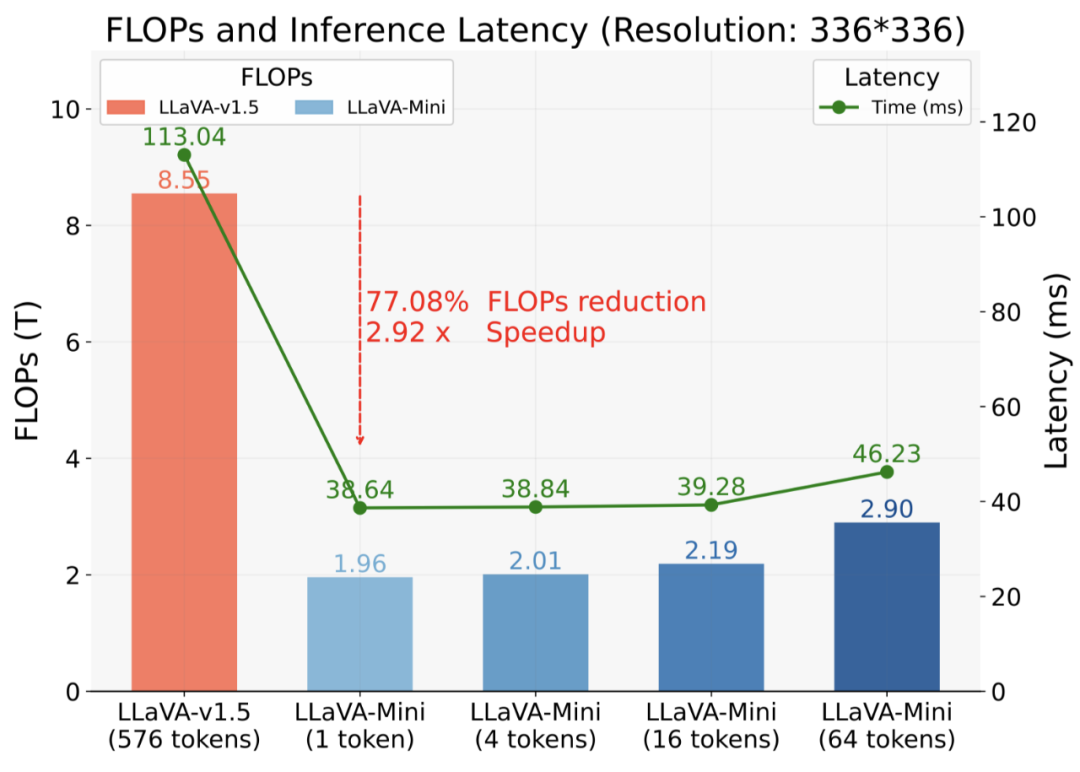
效率優勢是 LLaVA-Mini 的一大亮點。如上圖所示,與 LLaVA-v1.5 相比,LLaVA-Mini 顯著減少了 77% 的計算負載,實現了 2.9 倍的加速。LLaVA-Mini 的響應延遲低于 40 毫秒,這對于開發低延遲實時 LMMs 至關重要。
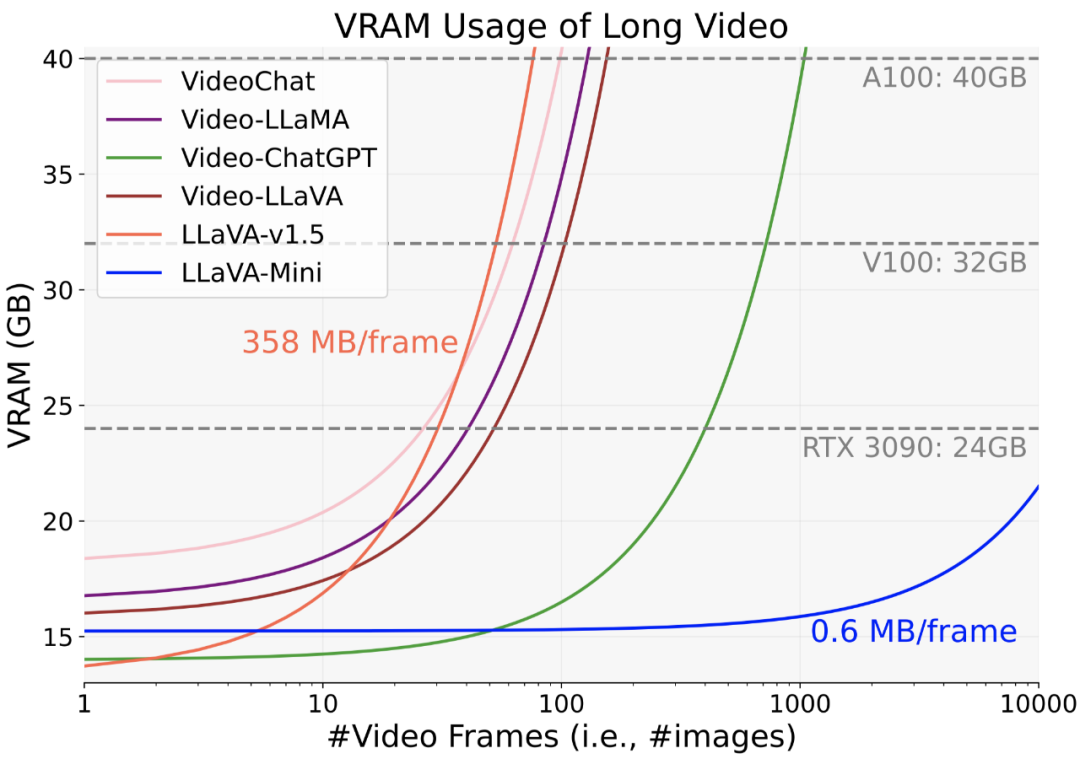
視頻處理是 LMMs 面臨的另一個挑戰,特別是在顯存消耗方面。上圖展示了 LMMs 在處理不同長度視頻時的內存需求。以往的方法每張圖像需要約 200-358 MB 的內存,使得它們在 40GB GPU 上僅能處理約 100 幀。相比之下,LLaVA-Mini 僅需 0.6 MB 內存即可處理每張圖像,理論上可在 24GB 內存的 RTX 3090 上支持處理超過 10,000 幀的視頻。
視覺 token 壓縮效果
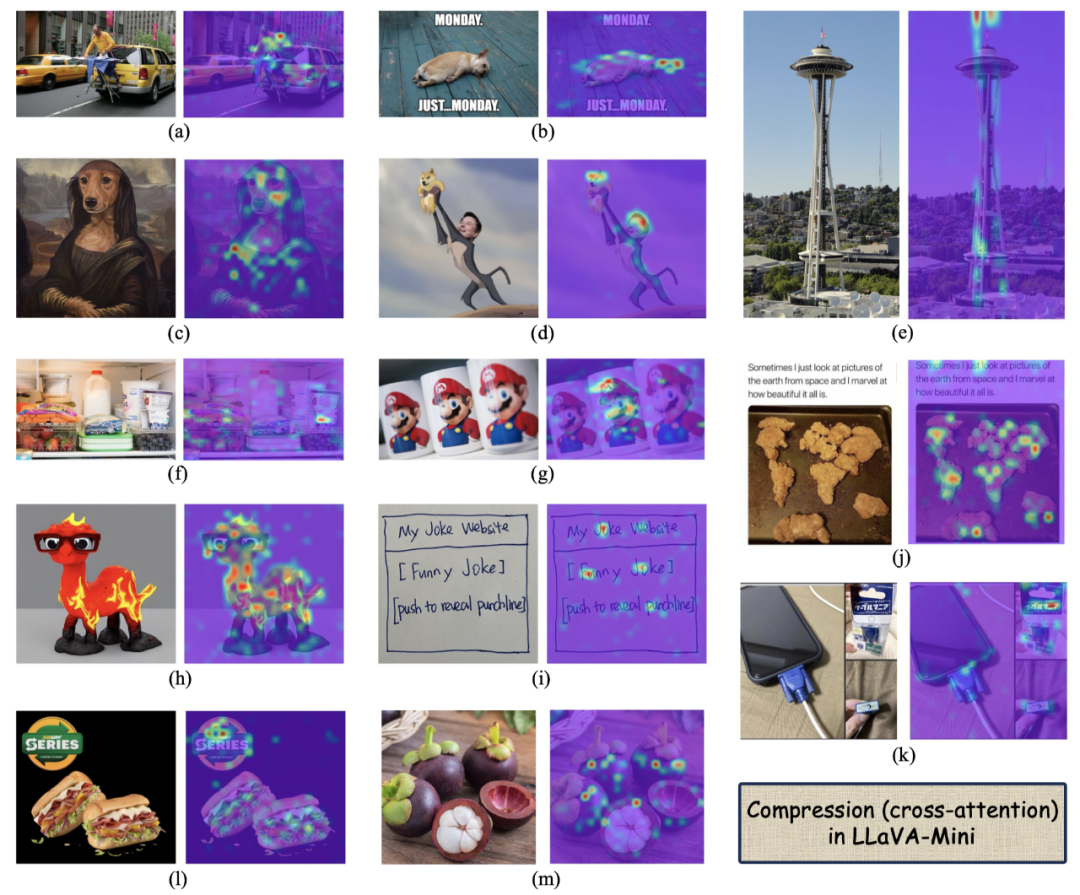
為驗證 LLaVA-Mini 將圖片壓縮成 1 個視覺 token 的有效性,上圖可視化了壓縮過程中的交叉注意力。在不同類型和風格的圖像(如照片、文本、截圖和卡通圖)中,LLaVA-Mini 的壓縮展現了強大的可解釋性,能夠有效地從圖像中提取關鍵的視覺信息。
總結
LLaVA-Mini 是一個統一的多模態大模型,能夠高效地支持圖像、高分辨率圖像和視頻的理解。LLaVA-Mini 在圖像和視頻理解方面表現出色,同時在計算效率、推理延遲和內存使用上具有優勢,促進了高效 LMM 的實時多模態交互。
不過,LLaVA-Mini 也存在一些局限,主要表現在處理一些 OCR 等精細化視覺任務時,壓縮成 1 個視覺 token 勢必會影響其性能。但由于 LLaVA-Mini 的靈活性,在使用時可根據具體場景設置壓縮后的視覺 token 數量,從而在性能和效率中取得權衡。























