數據驅動與 LLM 微調:打造 E2E 任務型對話 Agent
作者 | Thought Agent 社區
在對話系統的設計和實現中,傳統的基于 Rasa-like 框架的方法往往需要依賴于多個模塊的緊密協作,例如我們在之前的文章中提到的基于大模型(LLM)構建的任務型對話 Agent,Thought Agent,其由自然語言理解(NLU)、對話管理(DM)和對話策略(DP)等模塊共同協作組成。這種模塊化的設計雖然在理論上具有靈活性,但在實踐中卻帶來了諸多挑戰,尤其是在系統集成、錯誤傳播、維護更新以及開發門檻等方面。

為了克服這些挑戰,構建一個端到端(E2E)的模型顯得尤為關鍵。E2E 的模型通過將對話的各個階段集成到一個統一的框架中,極大地簡化了系統架構,提高了處理效率,并減少了錯誤傳遞的可能性。此外,由于其簡化的架構,也更易于維護和更新,從而降低了開發和維護的成本。
在我們看來,端到端的對話 Agent 不僅在技術上更具優勢,而且在實際應用中也展現了其獨特的價值和潛力,例如能夠快速構建幫助用戶查詢信息、調度技能的 Agent。
本文將指導讀者如何采用蒙特卡洛方法(Monte Carlo)模擬用戶行為并結合 LLM 的方法來構建訓練數據集;使用 LLaMA Factory 對多種 LLM 進行高效微調構建任務型對話 Agent。該方案允許用戶快速創建出能夠精準調用外部工具的 Agent。
挑戰
任務型對話系統的核心需求包括意圖識別、槽位填充、狀態管理和策略決策。我們識別了以下幾個關鍵挑戰:
- 微調后的 LLM 需要從用戶的問題中識別到用戶意圖和關鍵信息(槽位)
- 微調后的 LLM 需要對用戶的問題有判斷邊界的能力,容易混淆的內容將觸發意圖確認,完全無關的內容將觸發兜底話術
- 微調后的 LLM 需要根據槽位填充狀態判斷合適的觸發功能調用(Function calling)的時機
- 微調后的 LLM 需要對根據上下文正確的識別到需要用于調用功能的關鍵信息
構造數據集
為了應對上述挑戰,首先我們需要構造能夠覆蓋大部分場景的對話數據集,我們面臨的核心難點是如何模擬真實世界中用戶的多樣化行為和對話系統的有效響應。但是對于任務型對話 Agent 來說,用戶和 Agent 之間的對話域是有限的,因為 Agent 只需要處理業務范圍內的用戶意圖,超出處理范圍的內容,只需要返回一些固定的兜底話術即可。
因此我們可以采用了狀態圖對對話的過程進行建模,使用蒙特卡洛方法對真實的對話過程進行模擬,接著使用 LLM 的生成能力來創建符合狀態、角色定義的對話內容從而達到構建數據集的目的。
1.基于圖的對話流程圖的建模
我們使用有向圖(Directed Graph)的數據結構來對通用的任務型對話流程進行建模,這比傳統的有限狀態機更加靈活和通用。在構建對話流程圖時,我們首先定義了一組節點,每個節點代表了對話中的一個關鍵狀態。例如,一個理想的對話過程至少包含以下節點:
- Start: 對話開始
- IntentAcquire: Agent 詢問用戶意圖
- UserInquiry: 用戶發起新的提問
- IntentConfirm: Agent 向用戶確認意圖 (用戶意圖不明確時)
- UserConfirm: 用戶確認意圖
- UserDeny: 用戶否認意圖
- AskSlot: 追問用戶關于該意圖的關鍵信息(槽位)
- ProvideSlot: 用戶提供或更新關鍵信息
- FunctionCalling: 調用功能,傳遞槽位信息
- Chitchat: 用戶閑聊
- End: 對話結束
在定義了節點之后,我們使用邊將可以進行狀態轉移的節點連接起來,從而構建一個有向圖用來表征對話過程中所有可能的轉移關系,如下圖。在這個圖中,主要的變量是用戶對話內容,Agent 的回復內容是隨著用戶的對話意圖和槽位狀態發生的變化而變化。對于每個原子對話來說,我們認為在用戶提供了清晰的意圖以及提供了全部的必填槽位信息之后,這個原子對話就算結束了,即可以觸發 Function Calling 的指令。
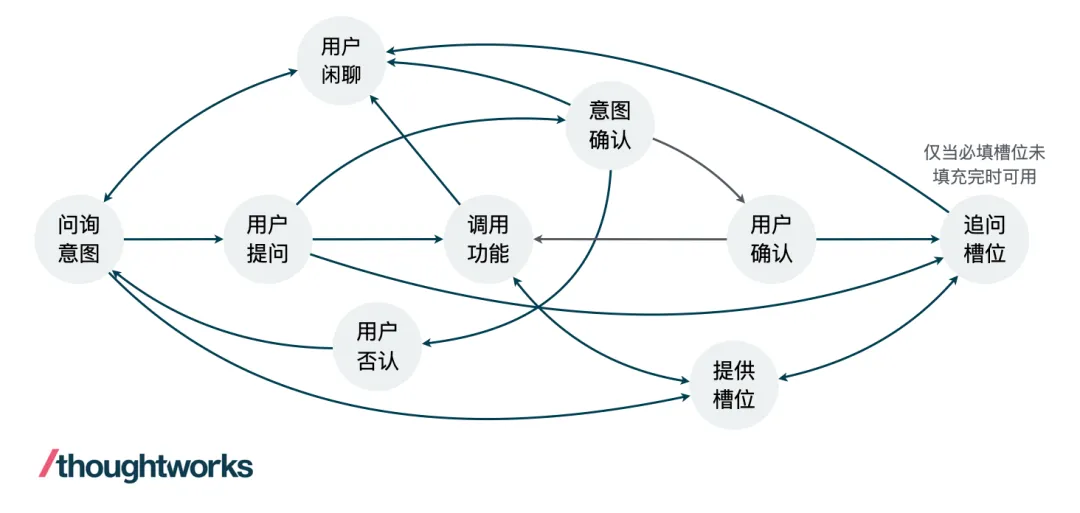
圖 1. 對話流程轉移圖示例(可能沒有覆蓋全部場景)
2.初始狀態隨機生成
在對話系統的開始階段,用戶的首次提問可能包含從零到全部所需槽位的不同信息量。為了模擬這種多樣性,我們可以使用蒙特卡洛方法來隨機決定哪些槽位在用戶的首次提問中被提及。具體來說,對于一個意圖中的所有槽位,我們可以生成一個由 0 或 1 組成的隨機數組,其中 0 表示該槽位不能再首次提問中提及,而 1 表示需要被提及。
例如,考慮一個酒店預訂任務,可能的關鍵信息包括「入住日期」、「退房日期」 和 「房間類型」。利用上述的方法,我們可以為每個槽位生成一個對應的隨機值,從而決定用戶的首次提問中需要包含哪些信息。這不僅增加了對話樣本的多樣性,也使得訓練數據集更加貼近真實世界的對話情況。
3.隨機游走模擬用戶行為
初始狀態生成了之后,我們需要生成生成多樣化的對話路徑,這里采用蒙特卡洛方法使得當前的對話狀態在建立好的對話轉移狀態圖中隨機游走。在每個狀態完成之后,將隨機選擇下一個狀態,各狀態的轉移概率可以根據經驗進行定義,從而模擬用戶可能采取的不同行動。例如,用戶在首問中沒有提供全部的必填槽位, Agent 將發起槽位的追問,對于 Agent 的追問,用戶可能認真的回答槽位信息,也有可能發起閑聊,還有可能改變了主意,問了一個新的問題,不同的轉移路徑我們可以設置不同的概率,例如上面的轉移路徑我們根據經驗分為設置概率為 [0.8, 0.1, 0.1]。
通過這種隨機游走的方式,可以生成不同的對話狀態路徑,每條路徑都代表了一種可能的用戶行為和 Agent 響應。這些路徑為我們提供了豐富的訓練數據,幫助對話系統學習如何處理各種情況。
4.對上下文理解能力的增強
在實際對話中,用戶通常不會在每個回合都重復提供所有相關信息。相反,他們會根據上下文,利用代詞、省略或簡化的表述來替代之前已經提及過的內容。為了讓對話系統能夠正確理解這種上下文依賴的表達方式,我們需要在訓練數據中模擬這種用戶行為模式。
具體來說,我們將對話分為多個階段,每個階段對應不同的任務意圖。在后續階段生成語料時,我們會考慮之前階段已經提供的槽位信息。如果用戶的新問題與之前的問題存在槽位重疊,且該槽位已在先前回合中提供過,那么在生成新問題時,我們將有意識地省略這部分信息,只保留用戶需要補充的新信息。
例如,假設用戶之前已經詢問過「成都市內哪家火鍋好吃」,這句話中包含了用戶想要了解的位置和餐廳類型兩個槽位信息。在后續對話中,如果用戶想詢問這些餐館的價格區間,可能會使用「它們的價格大概是多少?」這樣的省略式表述,而非重復提供完整的問句。通過模擬這種情況,我們可以增強模型對于上下文依賴的理解能力。
5.基于 LLM 的對話內容生成
LLM 在這一過程中扮演了至關重要的角色。我們利用 LLM 的強大生成能力來模擬用戶的提問和系統的追問,生成接近真實對話的數據。例如,以推薦餐廳這個意圖為例, 用于生成首問的 Prompt 可以這樣寫:
你是一個用戶,你現在想要「根據自己的位置、興趣和預算,讓智能客服推薦當地的餐廳」,請向智能客服尋求幫助。
你的問題需要滿足以下幾個條件:
- 1在問題中需要提到具體的用戶當前的區域或希望探索的區域。
- 在問題中一定不要提到具體的用戶感興趣的餐廳類型,中餐,日料,西餐等。
- 在問題中一定不要提到具體的用戶的最大預算。
請生成一句滿足當前的場景和設定的問題。
LLM 廣闊的知識面為我們提供了豐富的語言資源,支持我們模擬各種場景的對話。此外,LLM 還能夠根據上下文生成連貫且邏輯性強的回復,進一步提高了數據集的質量。
為了增強任務型對話 Agent 對領域信息的理解以及提高對話的多樣性, RAG 技術將被用于為對話內容注入領域相關的知識。特別是在處理涉及特定領域業務的時候,領域知識在這一過程中至關重要。為了在實現領域信息的注入,以辦理業務這個意圖為例,可以采取以下實施步驟:
- 首先,提前準備好所有可以辦理的業務列表以及每個業務對應的描述信息作為我們的候選信息源。
- 接著,在每次需要再對話中提及具體的業務功能的時候從這個槽位列表中隨機選擇一個或多個功能。例如,我們可以構建這樣的 Prompt 「請生成一個用戶想要辦理 A 業務的話術,A 業務是一個 xxx 的功能」來生成不同的用戶問題,一方面注入了我們想要 Agent 學習的領域知識,另一方面保證了對話語料的多樣性。
通過這種方法,任務型對話代理可以更好地理解和響應用戶需求,提供更精準和個性化的服務。
6.易擴展的意圖配置
對于任務型 Agent 來說,對話的目標是一致,即收集足夠的信息幫助用戶執行任務。我們可以通過一個 YAML 文件來對任務的詳細內容和槽位信息進行描述,用戶意圖增加和減少都可以通過編輯一系列 YAML 配置文件來實現,而無需對有狀態轉移圖或生成流程進行復雜的更改。這種設計提高了本文方案的可擴展性。例如想生成一個根據地點,餐廳類型,最大預算推薦餐廳任務相關的數據集,只需要編寫如下配置文件即可:
name: recommend_restaurant
description: 根據自己的位置、興趣和預算,讓智能客服推薦當地的餐廳
parameters:
- name: destination
description: 用戶當前的區域或希望探索的區域。
type: text
required: True
- name: cuisine_type
description: 用戶感興趣的餐廳類型,中餐,日料,西餐等
type: text
required: True
- name: budget
description: 用戶的最大預算
type: float
required: False目標為任務型對話 Agent 的 LLM 微調
我們選擇 LLaMA Factory 作為我們的微調工具,這是一個開源的高效微調框架,專為 LLMs 設計,能夠適應各種下游任務,并且兼容大部分主流模型,同時提供一個圖形界面 LLaMA Board 幫助用戶更友好的執行和管理微調任務。
對于本文的任務,對 LLM 按照任務型 Agent 方向進行微調,因為需要學習的知識較少,并且不會對模型整體的回答能力進行大的變化,這里我們采用 LoRA 微調技術對模型進行 SFT。在基礎模型的選擇上,沒有經過指令微調的 Base 模型和有過指令微調后的 Chat 模型(e.g., Qwen 1.5 和 ChatGLM3)都會被納入選擇范圍。
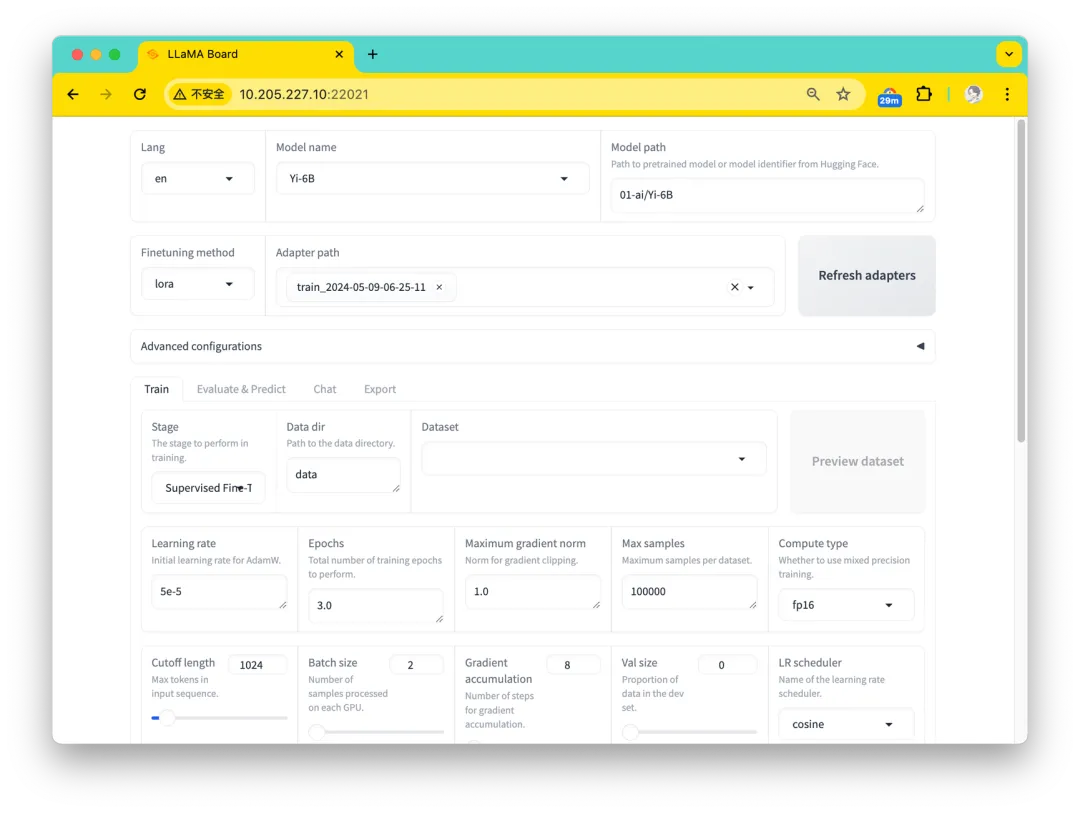
圖 2. 面向 LLM 微調的 LLaMA Board 系統
LLaMA Factory 支持 Alpaca 和 ShareGPT 兩種數據集的格式,這里我們將上面使用蒙卡 + LLM 生成的數據集處理為 ShareGPT 格式。下面就是個 ShareGPT 格式包含功能調用內容的數據例子,其中 conversations 中是對話歷史,tools 是當前對話中所有可用的工具。

為了保證不同的意圖和槽位能被相對準確的識別到,根據實踐經驗我們認為訓練數據量需要滿足意圖數 x 槽位數 x 500 的規模。這里我們構造了 5 個任務,分別是根據實時匯率轉換貨幣金額,了解某個地區的習俗和文化特點,根據用戶的位置或興趣,推薦附近的博物館,根據自己的位置、興趣和預算,推薦當地的餐廳以及查詢去某個目的地的交通方式。每個意圖包含 2 至 3 個槽位,共生成了 6000 條左右的數據,覆蓋了 5 個任務大部分用戶狀態變化路徑,接下來將對微調訓練的部分進行詳細的介紹。
實驗配置及結果
本文選擇在 A6000 顯卡上進行微調,微調精度選擇 fp16,LoRA Rank 設置為 4,訓練 3 個 Epoch。在不使用 flash attention 加速時整個訓練過程耗時 1.5h 左右,對于 6B - 7B 的模型,顯存占用在 20 - 22G 左右。實驗對象包括目前市面上主流的開源模型,ChatGLM3 6B,Qwen 1.5 7B,Yi 6B 系列的 Chat 模型和 Base 模型。在額外構造了 100 個驗證對話集對模型進行評估之后,這里將微調前的 Qwen 1.5 Chat 模型作為基線對比了不同模型微調后的表現,
表 1. 不同基模型的微調結果對比
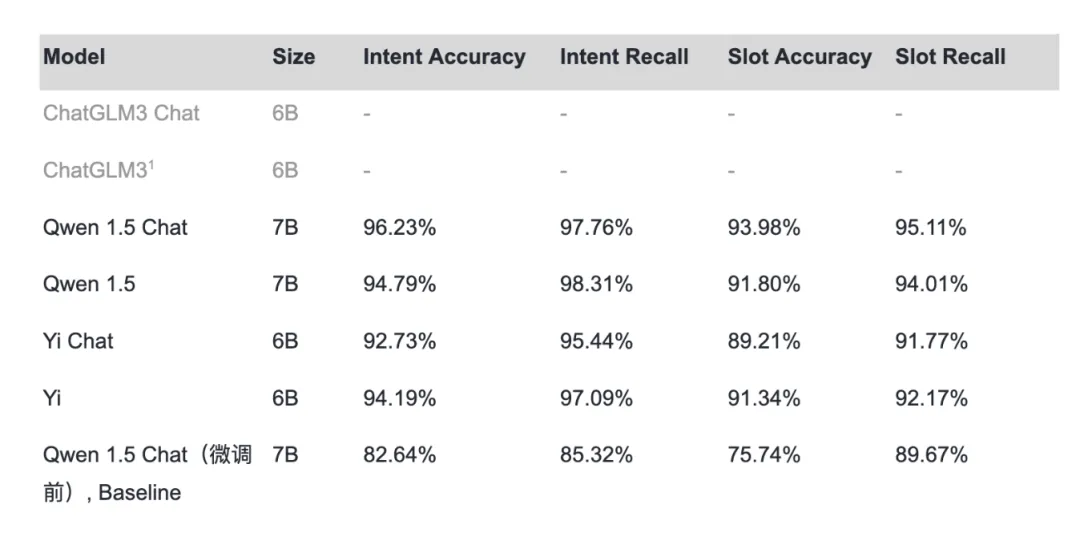
從對比結果可以發現,經過我們微調后的 Qwen 1.5 Chat 模型在整體性能上表現最佳,相對于 Baseline(微調前的 Qwen 1.5 Chat 模型),除了微調不成功的 ChatGLM3 之外,性能上都有比較顯著的提升。Qwen 1.5 的意圖召回率略高于 Qwen 1.5 Chat 的原因是 Qwen 1.5 出現幻覺的概率較高,在給出 Tools 之后,沒有明顯調用工具的提問也較容易觸發工具調用。
對比一下 Qwen 1.5 Chat 微調前和微調后的表現,下圖 3 為 Qwen 1.5 Chat 微調前的對話表現,圖 4 為 Qwen 1.5 Chat 經過微調后的對話表現。可以明顯發現微調后的模型對于槽位的識別方面提升很大,并且還附加了槽位追問的能力。
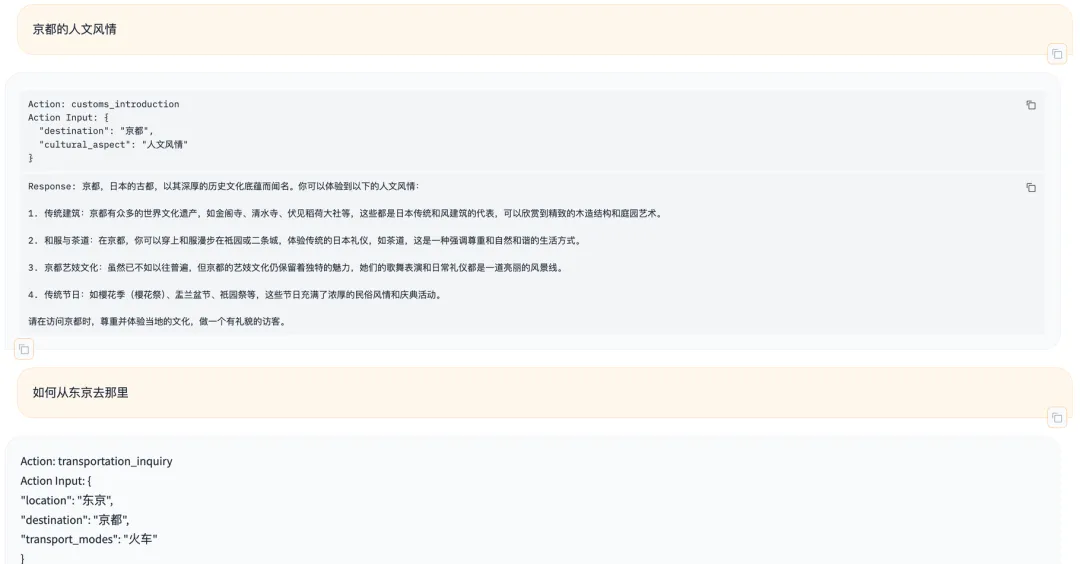
圖 3. Qwen 1.5 Chat 微調前的對話表現

圖 4. Qwen 1.5 Chat 微調后的對話表現
此外,Agent 對于用戶在對話中省略主語時也能正確的識別槽位信息,如下圖所示,用戶在說「5000 人民幣可以在當地還多少錢呢」的時候,模型能夠智能的將「當地」和上文中提到的「京都」聯系起來,在上下文結合和理解上的表現上比傳統的 Rasa-like 對話 Agent 表現的更加智能和靈活,達到了我們的預期水平。
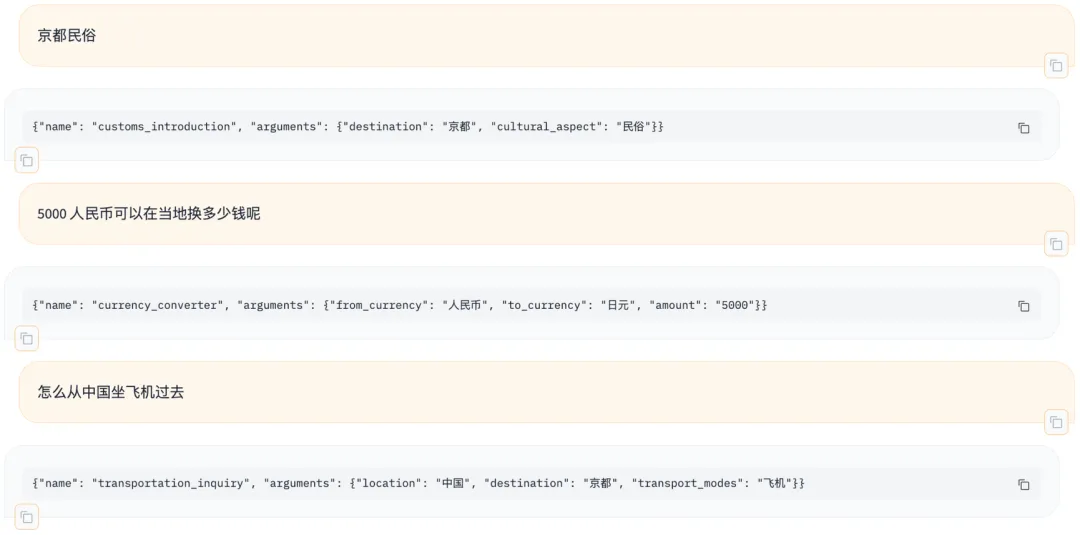
圖 5. 本文微調的 Agent 模型超越普通 Rasa-like 對話 Agent 的能力
對比經過指令微調的 Chat 模型和沒有指令微調過的 Base 模型我們還發現,經過指令微調的 Chat 模型得到的微調反饋最佳,特別是經過 Agent 相關指令微調的 Chat 模型,這主要是這類模型已經使用了大量包括 Function Calling 的語料進行了訓練,我們在此基礎上進行微調實際上屬于同方向的增量學習,需要 Agent 額外的學習成本更小。
結論
本文提出了一種利用蒙卡方法和 LLM 生成訓練數據集,并將其與 LLaMA Factory 框架相結合,高效微調多種語言模型,構建任務型對話 Agent 的新穎方案。該方案不僅保留了大語言模型強大的理解和生成能力,而且顯著提高了微調后模型在意圖識別、槽位填充等關鍵任務上的性能表現。
與傳統的模塊化對話系統相比,本文方法構建的端到端 Agent 架構更加簡潔高效,易于部署和維護。實驗結果表明,經過微調的語言模型不僅能夠準確識別用戶意圖和關鍵信息,還能根據上下文理解用戶的省略表達,并在必要時主動追問槽位信息,相較于微調前的模型,展現出更強的理解和交互能力,相較于傳統的模型,展現出了更多的智能性。
盡管如此,該方案仍然存在一定的不足,首先在數據集的構建方面,靠人腦整理的行為狀態圖很難考慮到所有可能的用戶路徑,建模的過程十分耗時。在 Agent 微調方面,準確率還有待進一步提高,因為是 E2E 的系統,整體的可控性和可解釋性相對較差。
未來我們的工作重點將包括:
- 優化數據集生成方法,例如結合蒙特卡羅樹搜索(MCTS)和評分模型的方案對對話狀態空間進行探索和篩選。
- 進一步優化微調方法、探索提高模型可解釋性的技術路線等,以期在保持語言模型強大能力的同時,進一步增強任務型對話 Agent 的性能和可靠性。