可信度超越GPT-4V,清華&面壁揭秘「小鋼炮」模型背后的高效對齊技術
近期,由清華大學自然語言處理實驗室聯合面壁智能推出的全新開源多模態大模型 MiniCPM-Llama3-V 2.5 引起了廣泛關注,在發布后火速登頂 Hugging Face、GitHub、Papers With Code 的 Trending 榜首,與 Meta、微軟、谷歌等科技巨頭共同從全球 66 萬模型中脫穎而出。與此同時,該模型使用的多模態對齊數據集也登上了 Hugging Face Trending 第二位。

僅有 8B 體量的 MiniCPM-Llama3-V 2.5 不僅在多模態綜合性能上超越了商用閉源的 GPT-4V、Gemini Pro、Claude3,同時在模型可信度方面也達到了開源模型中的最高水平。其出色的性能離不開背后的一項關鍵性技術 ——RLAIF-V。這項技術基于完全開源的范式進行多模態大模型的對齊,實現了超越 GPT-4V 的可信度。

- 論文:RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness
- 論文地址: https://arxiv.org/abs/2405.17220
- 項目地址:https://github.com/RLHF-V/RLAIF-V
- DEMO:https://huggingface.co/spaces/openbmb/RLAIF-V-12B
RLAIF-V 核心特點
從亦步亦趨邁向切磋琢磨,通過開源反饋實現超越 GPT-4V 的可信度。
已有的多模態大模型對齊方案主要采用蒸餾 GPT-4V 等昂貴的閉源模型的方式,實際上提供了一種模仿的方法(“亦步亦趨”)。隨著開源社區的不斷發展,我們急需一種能夠讓開源模型利用能力相仿或者相同的模型提供反饋,進行自動對齊的方案(“切磋琢磨”)。RLAIF-V 通過無偏候選構造和分而治之的反饋收集策略,可以從 OmniLMM 12B 等常規開源模型收集大規模的高質量反饋數據。通過充分利用這些數據,RLAIF-V 12B 模型在生成任務和判別任務中都實現了超越 GPT-4V 的可信度。

RLAIF-V 學習范式與模型可信度對比
具備優秀泛用性的大規模高質量反饋數據。
研究團隊將訓練 RLAIF-V 7B 和 RLAIF-V 12B 過程中所構造的高質量對齊數據整理為規模超過 83k 的多任務多模態對齊數據集 RLAIF-V Dataset,包括圖片詳細描述、圖片知識問答、文字識別等多類指令,圖片種類覆蓋照片、藝術作品、名人、地標、場景文字等。實驗表明,該數據集可有效減少 LLaVA 1.5, MiniCPM-V 等不同多模態大模型在多種任務中的幻覺,展現出了優秀的泛用性。

RLAIF-V 數據泛用性
迭代對齊的高效反饋學習。
在現有的模型訓練中,采用的偏好數據是靜態的,但隨著訓練的進行,模型的輸出分布卻在不斷變化,這導致訓練數據分布與模型真實分布產生偏移,從而無法充分利用偏好數據,影響模型的對齊效率。RLAIF-V 采用了迭代的方式進行對齊訓練,相較于非迭代方法表現出了更高的學習效率和更好的性能,具有更優秀的規模效應。
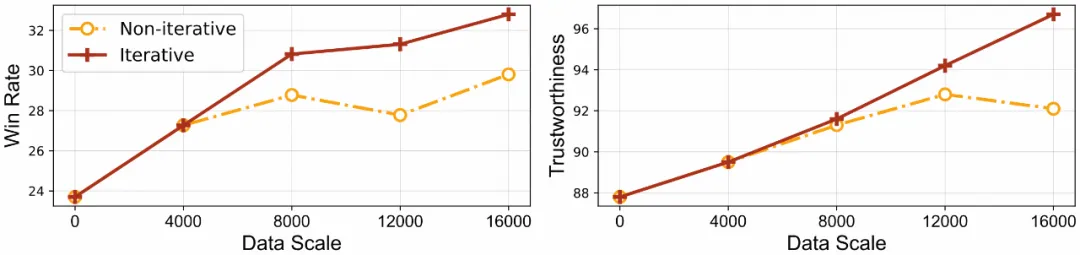
迭代與非迭代式訓練的效果對比
更可靠全面的多模態評測集 RefoMB。
隨著模型能力的發展,已有的評測集或存在評測飽和的情況,或評測準確性不足,從而難以正確區分不同可信度的模型。為此,RLAIF-V 提出了新的 RefoMB 評測集,其指令覆蓋了多模態模型感知和推理任務中的 8 個子能力,并包含了卡通圖片、富文字圖片、照片等多樣化的圖片類型,用于評估現有多模態模型在開放生成時的回復可信度和通用性能。通過人工標注圖片詳細描述作為評判參考,RefoMB 有效提高了評測準確性,人工一致性可以達到 96%。

RefoMB 指令類型分布
RLAIF-V 框架
RLAIF-V 包含兩項創新方法:數據層面,提出完全基于開源模型的高質量反饋數據構造方法;算法層面,采用迭代對齊算法進行模型優化。

RLAIF-V 框架
大規模高質量開源模型反饋數據的構造
為了減小反饋對齊數據的獲取成本,實現規模化的反饋對齊數據獲取,并提高開源多模態大模型提供反饋的質量,研究團隊結合分而治之的思想,提出了如下數據構造流程以實現高質量開源模型反饋的獲取:
- 無偏候選回復生成(deconfounded candidate response generation):使用隨機解碼方法生成多個候選響應。在這種生成方式下,不同回復來自一個相同的分布,有效消除了樣本對之間的文本風格差異等混淆因素,使訓練過程專注于內容的可信度,從而提高數據效率。
- 分而治之(divide-and-conquer):將復雜的響應分解為更簡單、可以單獨評估的子問題。這種簡化使開源多模態大模型可以提供更可靠的反饋。
應用這種數據構造方法,我們不僅可以利用具有更高模型性能的開源多模態大模型為性能較弱的模型提供反饋,還能夠通過模型自身反饋的方式,使 OmniLMM 12B 模型實現超越 GPT-4V 的可信度。
迭代對齊算法
為了緩解現有對齊算法存在的分布偏移問題,一個直接的思路是在每步優化時更新反饋數據。但是,這種在線反饋的方式開銷大、訓練不穩定。因此,研究團隊采用了一種迭代對齊算法,在每輪迭代中更新反饋數據,提升數據與模型分布的一致性。具體而言,在每一輪迭代時,利用上一輪訓練得到的模型權重生成新的反饋數據,并使用新數據進行訓練。

迭代對齊算法
RefoMB 評測集
在開放問答下的多模態幻覺評測中,有兩類常見評測方式。一類是利用圖片標注的常見物體類型,對模型回復中的存在性幻覺進行評測的方式,例如基于 MSCOCO 標注信息的 CHAIR 評測。另一類則利用 GPT-4 模型作為裁判,根據參考信息對模型回復的可信度進行打分,如 MMHal Bench 評測。
然而,隨著模型能力的增強,僅考慮物體存在性幻覺的評測指標接近飽和,難以區分更加先進的模型之間的可信度差異;而采用 GPT-4 打分的形式構造的評測集則因為提供的圖片參考信息缺乏全面性,影響了可信度判斷的準確性。
針對這兩個問題,我們需要一個更加準確、且能夠評估更加全面的幻覺類型的評測集,以真實反映目前多模態模型的可信度情況。為此,研究團隊采用了如下方法:
- 人工標注詳盡圖片描述:通過提供人工標注的詳盡圖片描述,GPT-4 模型能夠更好地掌握圖片的完整信息,從而提供更準確的判斷。

人工標注詳盡圖片描述樣例
- 基于比較的評估:受語言大模型評測集 AlpacaEval 的啟發,研究團隊采用 GPT-4 模型對兩個多模態模型的回復優劣進行比較,并選擇其中更優的回復。相比于直接對模型回復進行打分,這種比較的形式可以產生更高的判斷準確率。

評測結果樣例
通過以上改進,RefoMB 能夠在人工一致性上顯著優于已有的開放問答幻覺評測集 MMHal Bench,達到 96% 的準確率。

RefoMB 與 MMHal Bench 的評測人工一致性比較
實驗驗證和結果
1.RLAIF-V 在 LLaVA 1.5 和 OmniLMM 兩種多模態大模型上均產生了顯著的可信度提升。
為了評估模型的幻覺水平,研究團隊測試了模型在開放生成任務和幻覺識別任務中的可信度表現。團隊還通過 LLaVA Bench 評測集評估了模型在開放對話和推理方面的性能。此外,為了全面了解模型的通用能力,研究團隊還在結合了 6 個常用多模態評測數據集的綜合評測集 MMStar 上進行了測試。
實驗結果表明:相比于人類反饋和 GPT-4V 反饋,RLAIF-V 提出的開源模型反饋方法甚至實現了更好的效果。RLAIF-V 12B 模型更是在幻覺評測指標上遠超已有的開源多模態大模型甚至 GPT-4V,在通用能力方面也能維持優秀的性能。
 圖片
圖片
RLAIF-V 與其他開源模型及 GPT-4V 在可信度和通用能力上的對比
2. 采用 RLAIF-V 提出的分治反饋方法能夠有效提高開源多模態大模型的反饋質量。
為了驗證 RLAIF-V 所提分治算法的有效性,研究團隊分別對三種不同的反饋模型采用直接反饋與分治反饋的方式構造了訓練數據,并評測訓練后模型在開放生成任務和幻覺識別任務中的可信度表現。
實驗結果表明,在不同性能的反饋模型中,采用分治反饋方式訓練得到的模型效果均顯著優于直接反饋。

分治反饋算法與直接反饋相比的模型可信度對比
3.RLAIF-V 數據能夠與其他多模態反饋數據互補,進一步提升模型可信度。
目前已經有一些工作構造了基于人工標注或啟發式規則的多模態反饋數據,為了探究不同方法構造數據之間的互補性,研究團隊將不同類型的反饋數據進行了合并訓練,并觀察模型性能的變化。從實驗結果來看,應用 RLAIF-V 數據能夠顯著提高模型可信度,而進一步融合其他反饋數據時,模型可信度能夠進一步提升。
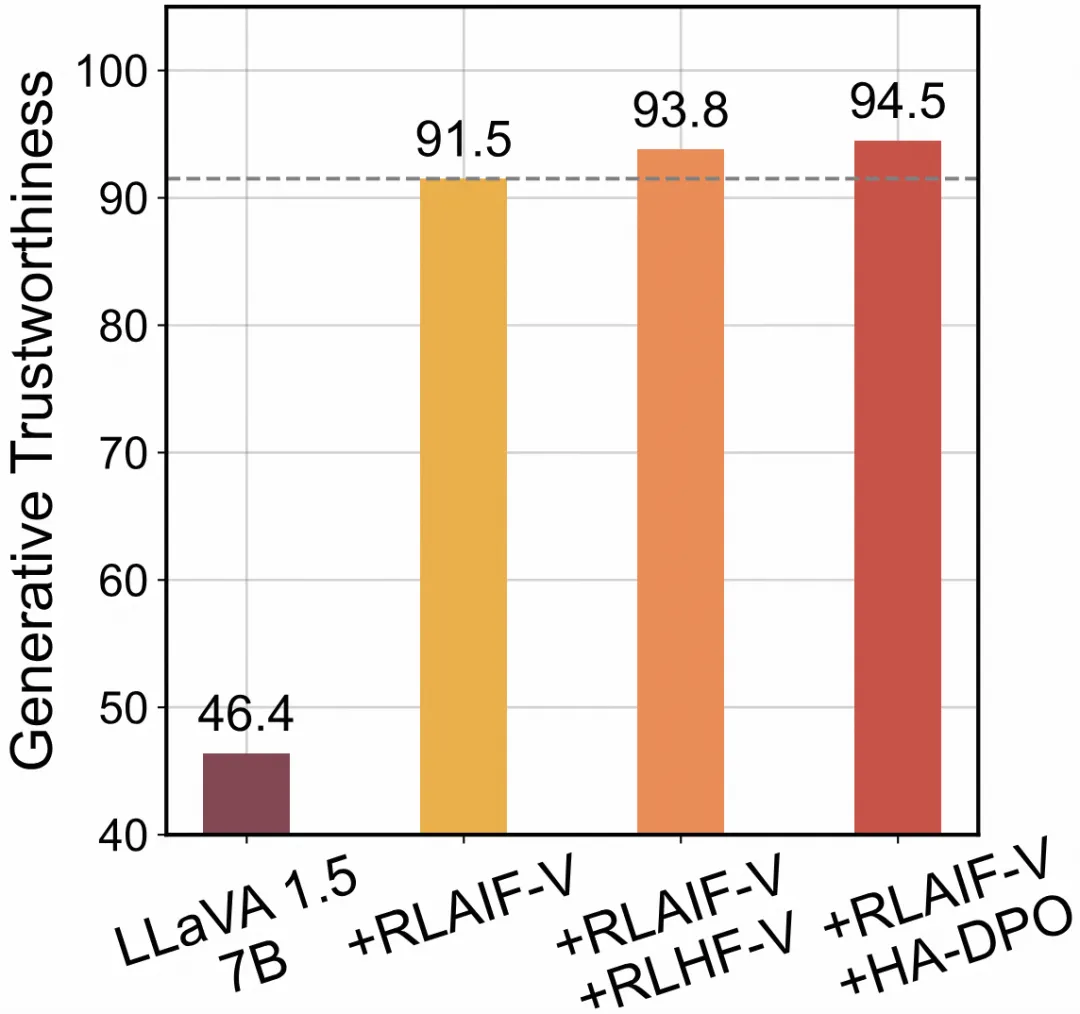
同時使用 RLAIF-V 數據與其他多模態反饋數據的效果
效果展示
使用 RLAIF-V 方法訓練 LLaVA 1.5 7B 模型以及 OmniLMM 12B 模型后,在開放生成問題下,RLAIF-V 模型與 GPT-4V 模型的表現如下:
測試效果 1:RLAIF-V 7B 模型能夠進行正確的推理,并具有更優的可信度。

RLAIF-V 7B 與 GPT-4V 效果對比,其中紅色部分為幻覺,綠色部分為正確的回答。注:原始問題和回答均為英文,翻譯為中文方便閱讀
當用戶提問 “分析圖中任務之間的關系” 時,RLAIF-V 7B 與 GPT-4V 均能夠根據圖中的信息判斷出同事關系,但 GPT-4V 錯誤地認為講話者是站立的狀態,產生了人物動作上的幻覺。
測試效果 2:RLAIF-V 12B 模型能夠在回復可信度上顯著優于 GPT-4V。

RLAIF-V 12B 與 GPT-4V 效果對比,其中紅色部分為幻覺,綠色部分為正確的回答。注:原始問題和回答均為英文,翻譯為中文方便閱讀
可以看到,當用戶提問:“圖中可以看到的主要顏色是哪些” 時,RLAIF-V 12B 以及 GPT-4V 均能夠正確回答出問題。但 GPT-4V 的回答中對文字顏色和背景顏色的識別均產生了錯誤。
測試效果 3:在更多類型的圖片和指令上,例如代碼問答任務上,RLAIF-V 方法同樣能減少模型幻覺,產生更可信的回復。

RLAIF-V 12B 與 GPT-4V 效果對比,其中紅色部分為幻覺,綠色部分為正確的回答。注:原始問題和回答均為英文,翻譯為中文方便閱讀
當要求模型解釋代碼輸出時,RLAIF-V 12B 與 GPT-4V 均能夠正確推理出代碼的運行結果,但 GPT-4V 錯誤地認為圖片中缺少一個分號,因此代碼無法編譯成功。這表明 RLAIF-V 方法所構造的偏好對齊數據能夠讓模型在諸如 OCR 等更廣泛的能力上的可信度同步提高。
總結
將模型輸出對齊人類偏好是構建實用化人工智能的關鍵環節。RLAIF-V 方法通過分而治之與迭代式訓練的方式實現了僅利用開源模型進行可信度提升的對齊目標。未來,研究團隊也將進一步探索邏輯推理、復雜任務等更廣泛能力上的對齊方法。