














譯者 | 陳峻
審校 | 重樓
現如今,檢索增強生成(Retrieval-augmented generation,RAG)管道已經能夠使得大語言模型(Large Language Models,LLM)在其響應環節中,充分利用外部的信息源了。不過,由于RAG應用會針對發送給LLM的每個請求,都去檢索外部信息,而LLM實際上已經包含了大量無需檢索即可使用的知識,因此整個過程反而顯得效率低下。
那么,我們是否可以通過配置LLM,使其只在內部知識不足的情況下,才去使用RAG呢?目前,博爾扎諾大學(University of Bozen-Bolzano)和布魯諾-凱斯勒基金會(Fondazione Bruno Kessler)的研發人員開發的一項“自適應LLM(Adapt-LLM,https://arxiv.org/abs/2404.19705)”技術,可以訓練LLM動態地確定它們是否需要在問題解答任務中,檢索額外的上下文信息,并避免不必要的外部檢索,來提高LLM應用的效率。
記憶與檢索
通常,LLM回答問題的方法主要有兩種。這兩種方法好比閉卷答題與開卷答題:
第一種是依靠在訓練過程中獲得的參數記憶。而這些參數記憶的局限性在于它需要完全基本語料的訓練。你可以通過微調或少量提示技術,來提高參數記憶的性能,從而將模型的注意力集中在相關參數上。不過,在模型必須動態使用新的信息(例如:近期的新聞或是未包含在訓練語料庫中的私人信息)的情況下,這種方法并不實用。
第二種是使用信息檢索器為模型提供上下文信息。而檢索增強生成就屬于這種方法。不過,信息檢索的問題在于,有時模型并不需要額外的上下文信息,其內部知識足以回答問題。
而作為人類的我們,使用的卻是混合方法。例如,當我們對某個問題的答案了如指掌時,我們便可立即作答。但當我們對自己的知識沒有信心時,就會去查找外部來源。目前,一些LLM技術通過“常見度評分”機制,來使用此類混合方法。其假設前提是:當問題十分常見時,模型就會利用內部記憶知識進行回答;而對于不太常見的問題,模型則需要RAG系統的幫助來獲取必要的信息。不過,這種方法往往要求問題附有常見程度的評分,而這并非總能夠獲取到的。
Adapt-LLM
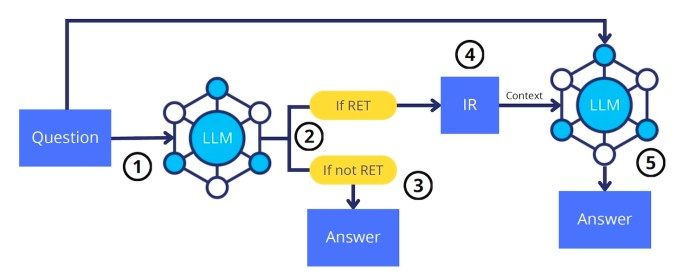
Adapt-LLM框架
顧名思義,Adapt-LLM為了實現“自適應檢索”而訓練語言模型,使其能夠自主地決定何時該使用信息檢索系統,來獲取更多的上下文信息。其研發人員指出:“在這種方法中,如果任務的解決方案已被編碼在模型的參數中,它將直接使用由模型生成的解決方案。反之,如果答案沒有被編碼在模型的知識域里,那么就需要借助外部知識來生成答案。”
就工作流程而言,Adapt-LLM可分為四個步驟:
- 首個包含了問題的提示被發送給Adapt-LLM模型處。
- 該模型會對提示進行評估,以確定是否需要額外的語境,來有效地回答問題。
- 如果模型認為不需要額外的上下文,它就會直接根據參數存儲做出響應。
- 如果Adapt-LLM模型需要額外的上下文,它會返回一個類似的特殊token。然后,應用程序可以使用信息檢索器,根據問題獲取上下文,并將其與原始提示結合起來。
可見,這種靈活的方法使得模型能夠在利用外部環境和提供直接答案之間取得平衡。
訓練Adapt-LLM
為了訓練 Adapt-LLM模型,我們首先需要一個包含了問題、上下文和答案的元組(tuples)數據集。然后,針對每個元組,為模型提供并不包含上下文的問題,并指示它在對自己的知識“有信心”時直接回答,而在需要額外上下文時返回 。
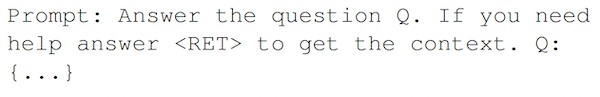
如果模型返回了正確的答案,則表明它已掌握了參數知識,并創建了一個包含問題和答案(但不包含上下文)的新的訓練實例。如果模型返回錯誤的答案,則需要創建兩個訓練實例:一個是包含了問題和 答案的“參數提示”,另一個是包含了問題、上下文、說明和答案的“上下文提示”。
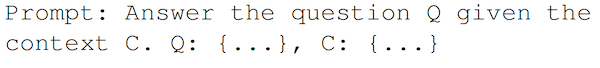
然后,在包含了這兩種類型示例的數據集上,研發人員對基礎模型進行訓練,從而形成Adapt-LLM的行為。
Adapt-LLM的測試結果
研發人員在PopQA(https://huggingface.co/datasets/akariasai/PopQA)上對Adapt-LLM進行了多次測試。此處的PopQA是一個從各種在線平臺上收集問題的數據集。他們使用 Llama-2 7B 作為基礎的LLM,并在由 NQ 和 SQuAD 問答數據集所創建的Adapt-LLM數據集上,對其進行了訓練。測試完畢后,他們將Adapt-LLM模型與完全不檢索模型、以及始終檢索模型進行了比較。
研究結果表明,Adapt-LLM的表現比只依賴參數記憶的永不檢索模型要好得多。同時,與始終檢索模型相比,它也能夠減少檢索的使用量,同時當其參數記憶優于RAG系統返回的信息時,還能夠提高整體性能。
據此,研發人員認為“當Adapt-LLM決定去檢索額外的信息時,其有上下文的結果明顯優于沒有上下文的結果。同樣,當Adapt-LLM依靠其參數記憶直接回答問題時,也能提供較高的準確率。”研發人員補充道:“這些測試結果足以表明,該模型能夠有效地分辨出何時檢索信息,以及何時可以在沒有進一步語境的情況下回答問題。”
利與弊
遺憾的是,研發人員并沒有公布 Adapt-LLM的代碼和模型,因此我們很難去驗證他們的實驗結果。然而,由于這是一項非常實用的技術,他們應該公布關于token的使用、及其推理時間等研究結果。幸運的是,該算法實現起來比較容易,任何人都可以創建自己的 Adapt-LLM版本,進而去驗證它在各個領域數據集上的表現。
作者介紹
陳峻(Julian Chen),51CTO社區編輯,具有十多年的IT項目實施經驗,善于對內外部資源與風險實施管控,專注傳播網絡與信息安全知識與經驗。
原文標題:Train your LLMs to choose between RAG and internal memory automatically,作者:Ben Dickson
鏈接:https://bdtechtalks.com/2024/05/06/adapt-llm/。





























