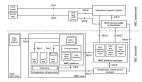
MLOps模型部署的三種策略:批處理、實時、邊緣計算
機器學習運維(MLOps)是一組用于自動化和簡化機器學習(ML)工作流程和部署的實踐。所選擇的部署策略可以顯著影響系統的性能和效用。所以需要根據用例和需求,采用不同的部署策略。在這篇文章中,我們將探討三種常見的模型部署策略:批處理、實時和邊緣計算。
批處理
批處理部署適合于不需要實時決策的場景,主要需要在指定的時間間隔處理大量數據。模型不是不斷更新或對新數據作出反應,而是在一段時間內收集的一批數據上運行。該方法涉及在預定時間處理大塊數據。常見的用例包括夜間風險評估、客戶細分或預測性維護等。這種方法非常適合于實時洞察不重要的應用程序。
優點:
批處理可以安排在非高峰時間,優化計算資源和降低成本。與實時系統相比,更容易實現和管理,因為它不需要持續的數據攝取和即時響應能力。
能夠處理大型數據集,使其成為數據倉庫、報告和離線分析等應用程序的理想選擇。
缺點:
數據收集和結果之間存在顯著延遲,可能不適用于時間敏感的應用程序。
用例:
欺詐檢測:通過分析歷史數據來識別欺詐交易。
預測性維護:根據收集數據中觀察到的模式來安排維護任務。
市場分析:分析歷史銷售數據,從中獲得見解和趨勢。
示例:
例如我們想要分析電子商務平臺的客戶評論的情緒。使用預訓練的情感分析模型,并定期將其應用于一批評論。
import pandas as pd
from transformers import pipeline
# Load pre-trained sentiment analysis model
sentiment_pipeline = pipeline("text-classification", model="distilbert-base-uncased-finetuned-sst-2-english")
# Load customer reviews data
reviews_data = pd.read_csv("customer_reviews.csv")
# Perform sentiment analysis in batches
batch_size = 1000
for i in range(0, len(reviews_data), batch_size):
batch_reviews = reviews_data["review_text"][i:i+batch_size].tolist()
batch_sentiments = sentiment_pipeline(batch_reviews)
# Process and store batch results
for review, sentiment in zip(batch_reviews, batch_sentiments):
print(f"Review: {review}\nSentiment: {sentiment['label']}\n")我們從CSV文件中讀取客戶評論數據,并以1000條為一批處理這些評論。對于每個批次,我們使用情感分析流程來預測每個評論的情感(積極或消極),然后根據需要處理和存儲結果。
實際的輸出將取決于customer_reviews.csv文件的內容和預訓練的情感分析模型的性能。
實時處理
實時部署在數據到達時立即對其進行處理,從而實現即時操作。這種方法對于需要實時數據處理和決策的應用程序是必不可少的。實時部署在處理數據并幾乎即時提供輸出時,適用于需要立即響應的應用程序,如欺詐檢測、動態定價和實時個性化等。
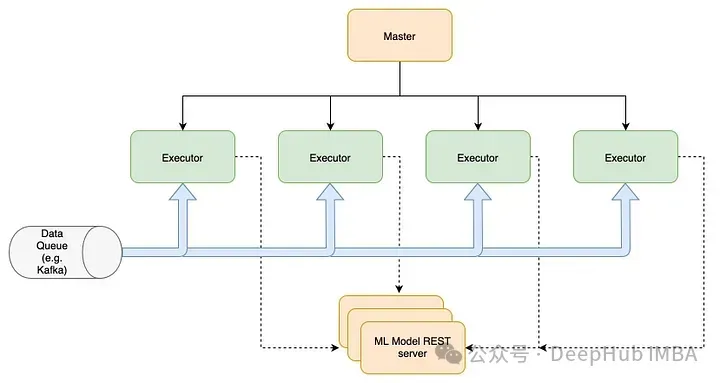
優點:
提供即時反饋,對時間敏感的應用程序至關重要,支持在毫秒到秒之間做出決策。提供動態和響應的交互,支持與最終用戶直接交互的應用程序,提供無可感知延遲的響應,可以提高用戶粘性。能夠快速響應新出現的趨勢或問題,提高運營效率和風險管理。
缺點:
需要強大且可擴展的基礎設施來處理可能的高吞吐量和低延遲需求。并且確保運行時間和性能可能既具挑戰性又成本高昂。
用例:
客戶支持:聊天機器人和虛擬助手為用戶查詢提供即時響應。
金融交易:基于實時市場數據做出瞬間決策的算法交易系統。
智慧城市:利用實時數據進行實時交通管理和公共安全監控。
示例:
我們希望對金融交易執行實時欺詐檢測,需要部署一個預先訓練的欺詐檢測模型,并將其公開為web服務。
import tensorflow as tf
from tensorflow.keras.models import load_model
import numpy as np
from flask import Flask, request, jsonify
# Load pre-trained fraud detection model
model = load_model("fraud_detection_model.h5")
# Create Flask app
app = Flask(__name__)
@app.route('/detect_fraud', methods=['POST'])
def detect_fraud():
data = request.get_json()
transaction_data = np.array(data['transaction_data'])
prediction = model.predict(transaction_data.reshape(1, -1))
is_fraud = bool(prediction[0][0])
return jsonify({'is_fraud': is_fraud})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)比如使用TensorFlow加載一個預訓練的欺詐檢測模型。然后我們創建一個Flask web應用程序,并定義一個endpoint /detect_fraud,它接受包含交易細節的JSON數據。對于每個傳入請求,數據經過預處理等流程,輸入模型并返回一個JSON響應,判斷這條數據是否具有欺詐性。
為了增加服務的響應速度,一般情況下都是使用,使用Docker這樣的容器化工具,并將容器部署到云平臺或專用服務器上,并且可以進行自動化的資源調度和擴展。
邊緣計算
邊緣部署涉及在網絡邊緣的設備上運行機器學習模型,更接近數據生成的位置。這種方法在本地處理數據而不是將數據發送到集中式服務器來減少延遲和帶寬使用。這種方法用于在將數據發送到中心服務器太慢或過于敏感的情況下,如自動駕駛汽車、智能攝像頭等。
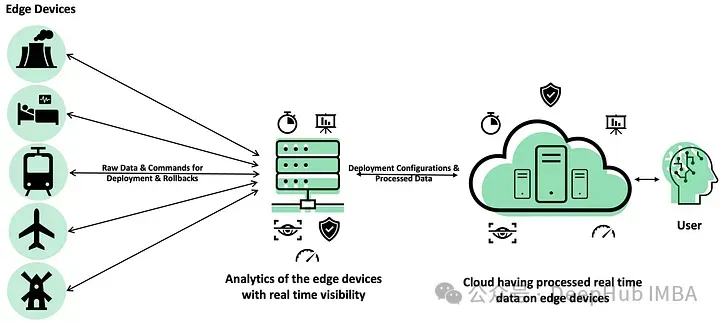
優點:
在本地處理數據,減少了向中心服務器回傳數據的需要,節省了帶寬,降低了成本。。通過在源附近處理數據來最大限度地減少延遲,非常適合需要快速響應時間的應用程序。
獨立于網絡連接運行,即使在遠程或不穩定的環境中也能確保持續的功能。并且敏感數據在設備上存儲,最小化暴露和合規風險。
缺點:
邊緣設備的處理能力通常低于服務器環境,這可能限制了部署模型的復雜性。并且在眾多邊緣設備上部署和更新模型可能在技術上具有挑戰性的,尤其是版本的管理。
用例:
工業物聯網:對制造工廠的機械進行實時監控。
醫療保健:可穿戴設備分析健康指標并向用戶提供即時反饋。
自動駕駛汽車:車載傳感器數據處理,用于實時導航和決策。
我們以最簡單的在移動設備上執行實時對象檢測作為示例。使用TensorFlow Lite框架在Android設備上優化和部署預訓練的對象檢測模型。
import tflite_runtime.interpreter as tflite
import cv2
import numpy as np
# Load TensorFlow Lite model
interpreter = tflite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# Get input and output tensors
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# Function to perform object detection on an image
def detect_objects(image):
# Preprocess input image
input_data = preprocess_image(image)
# Set input tensor
interpreter.set_tensor(input_details[0]['index'], input_data)
# Run inference
interpreter.invoke()
# Get output tensor
output_data = interpreter.get_tensor(output_details[0]['index'])
# Postprocess output and return detected objects
return postprocess_output(output_data)
# Main loop for capturing and processing camera frames
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if ret:
objects = detect_objects(frame)
# Draw bounding boxes and labels on the frame
for obj in objects:
cv2.rectangle(frame, (obj['bbox'][0], obj['bbox'][1]), (obj['bbox'][2], obj['bbox'][3]), (0, 255, 0), 2)
cv2.putText(frame, obj['class'], (obj['bbox'][0], obj['bbox'][1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (36, 255, 12), 2)
cv2.imshow('Object Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()以TensorFlow Lite格式加載一個預訓練的對象檢測模型,模型針對移動和嵌入式設備進行了優化。
在主循環中,不斷地從設備的相機中捕獲幀,將它們傳遞給detect_objects函數,并為檢測到的對象在幀上繪制邊界框和標簽。處理后的幀然后顯示在設備的屏幕上。邊框將以綠色繪制,對象標簽將顯示在每個邊框的左上角。
這些代碼可以使用各自的TensorFlow Lite api和庫集成到Android或iOS應用程序中。
選擇正確的部署策略
選擇正確的機器學習模型部署策略是確保高效性和成本效益的關鍵。以下是一些決定部署策略時需要考慮的主要因素:
1. 響應時間需求
- 實時部署:如果應用程序需要即時反饋,如在線推薦系統、欺詐檢測或自動交易系統。
- 批處理部署:如果處理的任務可以容忍延遲,例如數據倉庫的夜間批量處理、大規模報告生成。
2. 數據隱私和安全性
- 邊緣部署:當數據隱私是一個重要因素,或者法規要求數據不得離開本地設備時,邊緣部署是理想選擇。
- 中心化部署:如果數據的隱私性較低或可以通過安全措施在云端處理,則可以選擇中心化部署。
3. 可用資源和基礎設施
- 資源有限的環境:邊緣設備通常計算能力有限,適合運行簡化或輕量級的模型。
- 資源豐富的環境:具有強大計算資源的云環境適合實時或大規模批處理部署。
4. 成本考慮
- 成本敏感:批處理可以減少對實時計算資源的需求,從而降低成本。
- 投資回報:實時系統雖然成本高,但可能因響應速度快而帶來更高的投資回報。
5. 維護和可擴展性
- 簡單維護:批處理系統相對容易維護,因為它們的工作負載是預測的。
- 需要高可擴展性:實時系統需要能夠應對突發的高流量,需要更復雜的管理和自動擴展能力。
6. 用戶體驗
- 直接與用戶交互:需要即時響應來提升用戶體驗的應用,如移動應用中的個性化功能,更適合實時部羅。
- 后臺處理:用戶不直接感受到處理延遲的場景,如數據分析和報告,批處理更為合適。
結合上述因素,你可以根據具體的應用場景和業務需求來選擇最適合的部署策略。這有助于優化性能,控制成本,并提高整體效率。
總結
了解批處理、實時和邊緣部署策略的區別和應用程序是優化MLOps的基礎。每種方法都提供了針對特定用例量身定制的獨特優勢,通過評估應用程序的需求和約束,可以選擇最符合目標的部署策略,為成功的AI集成和利用鋪平道路。