譯者 | 朱先忠
審校 | 重樓
引言

“將你的企業數據轉化為可用于實際生產環境的LLM應用程序,”LlamaIndex主頁用60號字體這樣高亮顯示。其副標題是“LlamaIndex是構建LLM應用程序的領先數據框架。”我不太確定它是否是業內領先的數據框架,但我認為它是一個與LangChain和Semantic Kernel一起構建大型語言模型應用的領先數據框架。
LlamaIndex目前提供兩種開源語言框架和一個云端支持。一種開源語言是Python;另一種開源語言是TypeScript。LlamaCloud(目前處于個人預覽版本)通過LlamaHub提供存儲、檢索、數據源鏈接,以及針對復雜文檔的付費方式的專有解析服務LlamaParse,該服務也可作為獨立服務提供。
LlamaIndex在加載數據、存儲和索引數據、通過編排LLM工作流進行查詢以及評估LLM應用程序的性能方面都具有優勢。當前,LlamaIndex集成了40多個向量存儲、40多個LLM和160多個數據源。其中,LlamaIndex Python代碼存儲庫已獲得超過30K的星級好評。
典型的LlamaIndex應用程序會執行問答、結構化提取、聊天或語義搜索,和/或充當代理。它們可以使用檢索增強生成(RAG)技術將LLM與特定的數據源聯系起來,這些源通常不包括在模型的原始訓練集中。
顯然,LlamaIndex框架將會與LangChain、Semantic Kernel和Haystack等框架展開市場競爭。不過,并非所有這些框架都有完全相同的應用范圍和功能支持,但就流行程度而言,LangChain的Python代碼倉庫有超過80K的星級好評,幾乎是LlamaIndex(超過30K的星級好評)的三倍,而相對最晚出現的Semantic Kernel已經獲得超過18K的星級好評,略高于LlamaIndex的一半,Haystack的代碼倉庫有超過13K的星級好評。
上述好評結果是與代碼倉庫的年齡密切相關的,因為星級好評會隨著時間的推移而積累;這也是為什么我用“超過”來修飾星級好評數的原因。GitHub上的星級好評數與歷史進程中的流行度存在松散的相關性。
LlamaIndex、LangChain和Haystack都擁有許多大公司作為用戶,其中一些公司使用了不止一個這樣的框架。Semantic Kernel來自微軟,除了案例研究之外,微軟通常不會公布用戶數據。
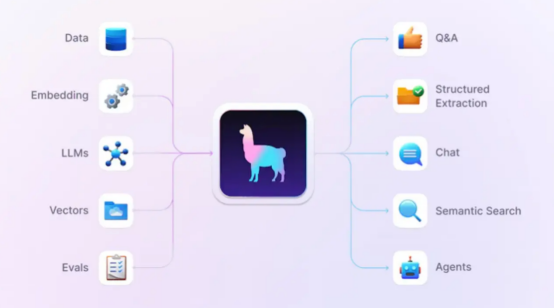
LlamaIndex框架可幫助你將數據、嵌入、LLM、向量數據庫和求值連接到應用程序中。這些支持可以用于問答、結構化提取、聊天、語義搜索和代理等環境。
LlamaIndex框架的功能
從高層面來看,LlamaIndex框架的開發主旨在幫助你構建上下文增強的LLM應用程序,意味著你可以將自己的私有數據與大型語言模型相結合。上下文增強LLM應用程序的示例包括問答聊天機器人、文檔理解和提取以及自動化代理等領域。
LlamaIndex提供的工具可執行數據加載、數據索引和存儲、使用LLM查詢數據以及評估LLM應用程序的性能:
- 數據連接器從其本機源和格式中獲取現有數據。
- 數據索引,也稱為嵌入,以中間表示形式構建數據。
- 引擎提供對數據的自然語言訪問。其中包括用于回答問題的查詢引擎,以及用于與你的數據進行多消息對話的聊天引擎。
- 代理是LLM驅動的知識工具,結合其他軟件工具增強性能。
- 可觀察性/評估集成使你能夠對應用程序進行實驗、評估和監控。
上下文增強
LLM受過大量文本的訓練,但不一定是關于你的領域的文本信息。當前,存在三種主要方法可以執行上下文增強并添加有關域的信息,即提供文檔、執行RAG和微調模型。
首先,最簡單的上下文擴充方法是將文檔與查詢一起提供給模型,為此你可能不需要LlamaIndex。除非文檔的總大小大于你正在使用的模型的上下文窗口;否則,提供文檔是可以正常工作的,這在最近還是一個常見的問題。現在,有了具有百萬個標記上下文窗口的LLM,這可以使你在執行許多任務時避免繼續下一步操作。如果你計劃對一百萬個標記語料庫執行許多查詢,那么需要對文檔進行緩存處理;但是,這是另外一個待討論的話題了。
檢索增強生成在推理時將上下文與LLM相結合,通常與向量數據庫相結合。RAG過程通常使用嵌入來限制長度并提高檢索到的上下文的相關性,這既繞過了上下文窗口的限制,又增加了模型看到回答問題所需信息的概率。
從本質上講,嵌入函數獲取一個單詞或短語,并將其映射到浮點數的向量;這些向量通常存儲在支持向量搜索索引的數據庫中。然后,檢索步驟使用語義相似性搜索,通常使用查詢嵌入和存儲向量之間的角度的余弦,來找到“附近”的信息,以便在增強提示中使用。
微調LLM是一個有監督的學習過程,涉及到根據特定任務調整模型的參數。這是通過在一個較小的、特定于任務或特定于領域的數據集上訓練模型來完成的,該數據集標有與目標任務相關的樣本。使用許多服務器級GPU進行微調通常需要數小時或數天時間,并且需要數百或數千個標記的樣本。
安裝LlamaIndex
你可以通過三種方式安裝Python版本的LlamaIndex:從GitHub存儲庫中的源代碼,使用llama index starter安裝,或者使用llama-index-core結合選定的集成組件。starter方式的安裝如下所示:
pip install llama-index除了LlamaIndex核心之外,這種安裝方式還將安裝OpenAI LLM和嵌入。注意,你需要提供OpenAI API密鑰(請參閱鏈接https://platform.openai.com/docs/quickstart),然后才能運行使用這種安裝方式的示例。LlamaIndex starter程序示例非常簡單,基本上僅包含經過幾個簡單的設置步驟后的五行代碼。在官方的代碼倉庫中還提供了更多的例子和有關參考文檔。
進行自定義安裝可能看起來像下面這樣:
pip install llama-index-core llama-index-readers-file llama-index-llms-ollama llama-index-embeddings-huggingface這將安裝一個Ollama和Hugging Face嵌入的接口。此安裝還提供一個本地starter級的示例。無論從哪種方式開始,你都可以使用pip添加更多的接口模塊。
如果你更喜歡用JavaScript或TypeScript編寫代碼,那么你可以使用LlamaIndex.TS。TypeScript版本的一個優點是,你可以在StackBlitz上在線運行示例,而無需任何本地設置。不過,你仍然需要提供一個OpenAI API密鑰。
LlamaCloud和LlamaParse
LlamaCloud是一個云服務,允許你上傳、解析和索引文檔,并使用LlamaIndex進行搜索。當前,該項服務仍處于個人alpha測試階段,我無法訪問它。
LlamaParse作為LlamaCloud的一個組件,允許你將PDF解析為結構化數據;它可以通過REST API、Python包和Web UI獲得。這個組件目前處于公測階段。在每周前7K頁的免費試用之后,你可以注冊使用LlamaParse,只需支付少量的使用費。官網上提供的有關針對蘋果10K大小文件基礎上的對于LlamaParse和PyPDF比較的例子令人印象深刻,但我自己沒有測試過。
LlamaHub
LlamaHub讓你可以訪問LlamaIndex的大量集成,其中包括代理、回調、數據加載程序、嵌入以及大約17個其他類別。通常,這些集成內容位于LlamaIndex存儲庫、PyPI和NPM中,你可以使用pip-install或NPM-install加載使用。
create-llama CLI
create-lama是一個命令行工具,用于生成LlamaIndex應用程序。這是開始使用LlamaIndex的快速方法。生成的應用程序中包含一個Next.js驅動的前端和三種后端方案可供選擇。
RAG-CLI
RAG CLI也是一個命令行工具,用于與LLM交流你在計算機上本地保存的文件。這只是LlamaIndex的眾多使用場景案例之一,不過這種情況非常普遍。
LlamaIndex組件
LlamaIndex組件指南會為你提供有關LlamaIndex各個部分的具體幫助。下面的第一個屏幕截圖顯示了組件指南菜單。第二個顯示了提示的組件指南,滾動到關于自定義提示的部分。
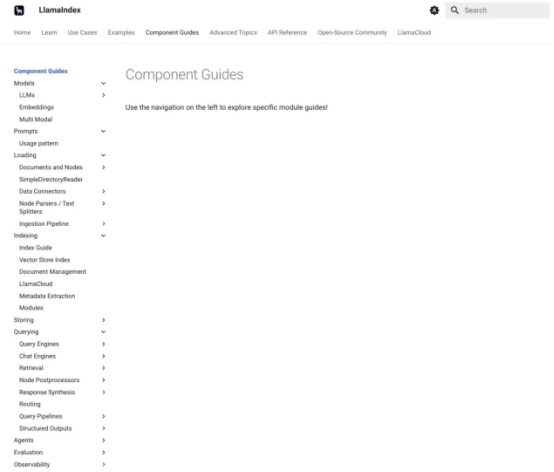
LlamaIndex組件指南記錄了構成框架的不同部分,其中介紹了相當多的組件。
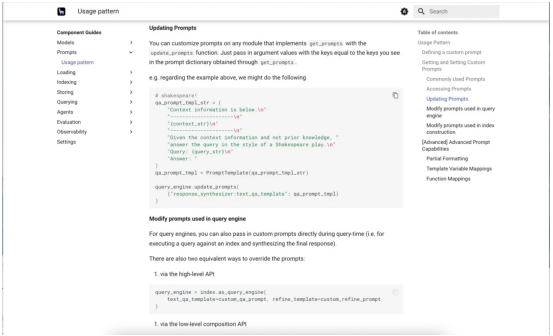
我們正在研究這種提示詞的使用模式。這個特殊的例子展示了如何自定義問答提示,以莎士比亞戲劇的風格回答問題。值得注意的是,這是一個零樣本提示,因為它沒有提供任何示例。
學習LlamaIndex
一旦你閱讀、理解并用你喜歡的編程語言(Python或TypeScript)運行了入門示例,我建議你盡可能多地閱讀、理解和嘗試其他看起來更有趣的一些示例。下面的屏幕截圖顯示了通過運行essay.ts并使用chatEngine.ts詢問相關問題來生成一個名為essay的文件的結果。這是一個使用RAG進行問答的示例。
其中,chatEngine.ts程序使用LlamaIndex的ContextChatEngine、Document、Settings和VectorStoreIndex等組件。當我分析其源代碼時,我看到它依賴于OpenAI gpt-3.5-turb-16k模型;這種情況可能會隨著時間的推移而改變。如果我對文檔的分析是正確的話,那么VectorStoreIndex模塊使用了開源的、基于Rust的Qdrant向量數據庫。
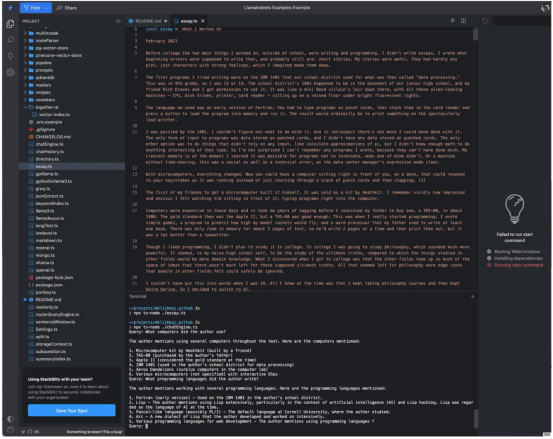
在用我的OpenAI密鑰設置了終端環境后,我運行essay.ts來生成一個散文題材的文件,并運行chatEngine.ts來實現有關此文章的查詢。
為LLM提供上下文
正如你所看到的,LlamaIndex非常容易用于創建LLM應用程序。我能夠針對OpenAI LLM和RAG Q&A應用程序的文件數據源進行測試。值得注意的是,LlamaIndex集成了40多個向量存儲、40多個LLM和160多個數據源;它適用于幾種使用場景,包括Q&A問答、結構化提取、聊天、語義搜索和代理應用等。
最后,我建議你認真評估LlamaIndex與LangChain、Semantic Kernel和Haystack等框架。這其中的一個或多個很可能會滿足你的需求。當然,我不能籠統地推薦其中某一個,因為不同的應用程序會有不同的要求。
LlamaIndex優點
- 幫助創建問答、結構化提取、聊天、語義搜索和代理等類型的LLM應用程序
- 支持Python和TypeScript
- 框架是免費和開源的
- 提供大量示例和集成組件
LlamaIndex不足
- 云環境僅限于私人預覽
- 營銷有點言過其實
LlamaIndex費用
開源:免費。
LlamaParse導入服務:每周免費支持7K頁的文檔,然后每1000頁需要支付3美元。
平臺支持
支持Python和TypeScript,以及云端SaaS(目前處于私人預覽狀態)。
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:LlamaIndex review: Easy context-augmented LLM applications,作者:Martin Heller