結合Spring Boot 3.x與機器學習算法優化推薦系統
本專題深入探討了12306火車購票系統在高峰期遇到的一系列疑難技術問題,特別聚焦于如何借助Spring Boot 3.x的強大功能來優化系統性能、安全性和用戶體驗。從智能驗證碼校驗,負載均衡與微服務架構,到支付安全加固和個性化推薦系統的構建,專題逐一提供了實戰案例和示例代碼,旨在幫助開發人員在實際工作中快速診斷并解決類似問題。此外,專題還關注了賬戶安全管理、數據一致性保障等關鍵領域,為讀者提供一套全面而深入的解決方案框架,旨在推動12306購票系統及類似在線服務平臺向更高水平的穩定性和用戶滿意度邁進。
結合Spring Boot 3.x與機器學習算法優化推薦系統
在現代交通系統中,個性化推薦可以極大地提升用戶體驗。通過分析乘客的歷史數據,我們可以為每個用戶提供定制化的車票和路線推薦。我們的目標是結合 Spring Boot 3.x 和機器學習算法,優化推薦系統,為用戶提供最優出行方案。
Spring Boot 3.x與機器學習算法結合優化推薦系統
我們會使用 Spring Boot 3.x 作為后端框架,搭建推薦服務。同時,采用機器學習算法對乘客的歷史數據進行分析,生成個性化推薦。主要使用以下技術棧:
- Spring Boot 3.x
- Scikit-learn 或 TensorFlow 作為機器學習框架
- MySQL 或 MongoDB 存儲用戶歷史數據
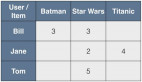
分析乘客歷史數據,提供個性化路線和車票推薦
我們將通過以下幾步來優化推薦系統:
- 數據收集和預處理:收集用戶的歷史出行數據,并進行預處理,去除異常值和噪聲。
- 機器學習模型訓練:使用收集到的歷史數據訓練推薦算法模型,例如使用協同過濾或基于內容的推薦算法。
- 系統集成:將訓練好的模型集成到 Spring Boot 應用中,為用戶提供實時的推薦服務。
數據收集和預處理
用戶的歷史數據存儲在 MySQL 數據庫中,包括用戶 ID、出行時間、出行路線等信息。我們要先從數據庫中提取這些數據,并進行預處理。
示例代碼:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
public class DataPreprocessing {
private static final String DB_URL = "jdbc:mysql://localhost:3306/ticketdb";
private static final String USER = "username";
private static final String PASS = "password";
public static List<UserData> fetchData() {
List<UserData> dataList = new ArrayList<>();
try (Connection connection = DriverManager.getConnection(DB_URL, USER, PASS)) {
String query = "SELECT user_id, travel_time, travel_route FROM user_history";
PreparedStatement preparedStatement = connection.prepareStatement(query);
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
dataList.add(new UserData(resultSet.getInt("user_id"), resultSet.getTimestamp("travel_time"), resultSet.getString("travel_route")));
}
} catch (Exception e) {
e.printStackTrace();
}
return dataList;
}
}機器學習模型訓練
這里我們使用 Python 的 Scikit-learn 框架訓練一個簡單的推薦模型。我們先將數據導出到 CSV 文件中,再通過 Python 代碼進行訓練。
示例代碼(Python):
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics.pairwise import cosine_similarity
# 加載數據
data = pd.read_csv('user_data.csv')
# 數據預處理
# 將出行路線轉為數值向量
routes = pd.get_dummies(data['travel_route'])
# 計算用戶之間的相似度
user_similarity = cosine_similarity(routes)
# 根據相似度推薦
def recommend(user_id, user_similarity):
similar_users = user_similarity[user_id].argsort()[-5:][::-1]
recommendations = data[data['user_id'].isin(similar_users)]
return recommendations
# 示例測試
user_id = 1
recommendations = recommend(user_id, user_similarity)
print(recommendations)系統集成
將訓練好的模型導出為文件,并在 Spring Boot 中加載和使用模型進行實時預測。
示例代碼(Spring Boot):
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.tensorflow.SavedModelBundle;
import org.tensorflow.Session;
import org.tensorflow.Tensor;
@RestController
public class RecommendationController {
private SavedModelBundle model;
public RecommendationController() {
// 加載模型
this.model = SavedModelBundle.load("/path/to/saved/model");
}
@GetMapping("/recommend")
public List<String> recommend(@RequestParam int userId) {
// 獲取用戶歷史數據
List<UserData> userDataList = DataPreprocessing.fetchDataByUserId(userId);
// 構建輸入張量
Tensor<String> inputTensor = Tensor.create(userDataList);
// 進行預測
Session session = model.session();
List<Tensor<?>> outputs = session.runner().feed("input", inputTensor).fetch("output").run();
Tensor<String> outputTensor = outputs.get(0).expect(String.class);
// 解析結果
List<String> recommendations = new ArrayList<>();
try (outputTensor) {
recommendations = outputTensor.copyTo(new String[1])[0];
}
return recommendations;
}
}注意事項
保障推薦系統的準確性
- 數據質量: 確保歷史數據的準確性和完整性,不要包含過多的異常值和噪聲。
- 模型選擇: 選擇合適的機器學習模型,不斷優化模型參數,提升推薦的準確性。
注意用戶隱私保護
- 數據加密: 對用戶數據進行加密傳輸和存儲,防止數據泄露。
- 數據匿名化: 在數據分析過程中,盡量使用匿名化處理的數據,保護用戶隱私。
總結
本文介紹了結合 Spring Boot 3.x 和機器學習算法來優化推薦系統。通過數據收集和預處理、機器學習模型訓練、系統集成等步驟,實現了對車票和路線的個性化推薦。同時強調了推薦系統的準確性和用戶隱私保護。希望幫助大家理解并實現更高效、更智能的推薦系統。