Panoptic-FlashOcc:目前速度和精度最優的全景占用預測網絡
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
宣傳一下小伙伴最新的工作Panoptic-FlashOcc,這是一種高效且易于部署的全景占用預測框架(基于之前工作FlashOcc),在Occ3DnuScenes上不僅取得了最快的推理速度,也取得了最好的精度。
- 論文地址:https://arxiv.org/pdf/2406.10527v1
- 論文單位:后摩智能、清華、中科大、大連理工
全景占用(Panoptic occupancy)提出了一個新的挑戰,它旨在將實例占用(instance occupancy)和語義占用(semantic occupancy)整合到統一的框架中。然而,全景占用仍然缺乏高效的解決方案。在本文中,我們提出了Panoptic-FlashOcc,這是一個簡單、穩健、實時的2D圖像特征框架。基于FlashOcc的輕量級設計,我們的方法在單個網絡中同時學習語義占用和類別感知的實例聚類,聯合實現了全景占用。這種方法有效地解決了三維voxel-level中高內存和計算量大的缺陷。Panoptic-FlashOcc以其簡單高效的設計,便于部署,展示了在全景占用預測方面的顯著成就。在Occ3D-nuScenes基準測試中,它取得了38.5的RayIoU和29.1的mIoU,用于語義占用,運行速度高達43.9 FPS。此外,它在全景占用方面獲得了16.0的RayPQ,伴隨著30.2 FPS的快速推理速度。這些結果在速度和準確性方面都超過了現有方法的性能。源代碼和訓練模型可以在以下github倉庫找到:https://github.com/ Yzichen/FlashOCC。
1. Introduction
全景占用在多視圖感知中對自主機器人導航[10]、環境映射[27]和自動駕駛系統[2, 29, 30, 34]起著至關重要的作用。由于全景質量指標[19]的引入,它最近受到了極大的關注。全景占用將3D場景從視覺圖像中劃分為結構化的體素,每個體素都被分配了一個實例ID,其中“thing”類別中的每個體素都通過類別標簽和實例ID來識別,而“stuff”類別中的體素僅用類別標簽進行標記。
多視圖3D全景占用仍然是一個新興領域,并且仍然是一個開放的研究問題。由于其計算量大,到目前為止,只有一篇論文SparseOcc[19]以稀疏的方式解決了這個問題。3D全景占用在網絡設計上提出了挑戰,因為它將3D體素的分割分類為語義分割區域,同時也區分了個別實例。此外,全景占用在文章開頭提到的領域中找到了其主要應用,所有這些領域都要求實時推理和高準確性,同時能夠在各種邊緣芯片上部署。這些挑戰激勵我們尋找一個更合適的架構,能夠解決這些問題,并在不犧牲準確性的情況下實現快速推理速度。
受到2D圖像全景分割中bottom-up范式成功的啟發,在這種范式中,通常首先獲得語義分割預測,然后對"thing"像素進行分組以形成聚類來識別實例[3, 7, 13, 26, 32],我們的目標是開發一個簡單、有效且可部署的網絡來處理全景占用。我們將語義占用與類別感知的實例聚類結合起來處理全景占用。為了確保在不犧牲準確性的情況下的推理速度,我們采用了FlashOcc[34]的架構來估計語義占用。FlashOcc利用通道到高度的轉換有效地將扁平化的鳥瞰圖(BEV)特征轉換為3D占用預測,無需使用計算成本高昂的3D體素級表示。然后,我們結合了一個輕量級的中心度頭,靈感來自Panoptic-DeepLab[3],以生成類別感知的實例中心。來自語義占用估計和中心度頭的預測通過全景占用處理融合,以生成最終的全景占用。這導致了一種高效的自下而上的全景占用網絡設計,我們稱之為Panoptic-FlashOcc。
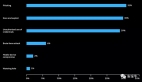
我們在具有挑戰性的Occ3DnuScenes數據集上使用三個指標評估了我們的方法:RayIoU、mIoU和RayPQ。得益于其高效的設計,Panoptic-FlashOcc在沒有花哨功能的情況下實現了最先進的性能,如圖1所示。它以38.5的RayIoU、31.6的mIoU和16.0的RayPQ達到了最高性能,同時保持了35.6、35.6和30.2 FPS的推理速度。此外,在RayIoU方面,它在保持最快推理速度43.9 FPS的同時,達到了與最佳競爭者相當的性能。
2. Related Work
Panoptic segmentation. 自從Kirillov等人[13]引入全景分割以來,這一領域出現了眾多努力。最初,對現有網絡的調整包括添加語義[13]或實例分支[3]到最先進的模型,隨后是手工制作的后處理技術[18, 31, 32]。隨著Transformer集成到計算機視覺中,研究人員開始探索能夠以更統一的方式處理全景分割任務的架構。MaskFormer[4]利用queries預測object masks和stuff masks。Mask2Former[5]引入了masked-attention,通過掩蔽圖像中無關的部分,顯著提高了對小物體的性能。雖然基于Transformer的方法與以前的模型相比顯示出了優越的性能,但它們在各種邊緣芯片上的部署方面提出了挑戰。最近,高效的MaskConver[23]通過僅使用全卷積層學習"thing"和"stuff"類的實例中心,超越了上述基于Transformer的模型。這激勵我們尋找一個高效且易于部署的模型,該模型僅以buttom-up的全卷積方式運行。
高效的全景占用。全景占用代表了一個新的方向,與全景分割的蓬勃發展相比,它仍然沒有得到充分的探索。Sparseocc[19]是第一個也是唯一一個專注于提高全景質量和推理速度的研究。它使用A100 GPU提供了質量和延遲的報告。由于語義占用是全景占用的一個子任務,全景理解可以從語義占用中經驗性地擴展,我們還探索了語義占用以識別具有高效架構的研究。許多工作[1, 16, 21, 29, 30]采用了密集的3D體素級表示來進行占用計算,盡管這需要計算3D卷積或Transformer模塊。因此,一些研究旨在簡化模型以減少計算時間。TPVFormer[12]提出使用三視角視圖表示來補充垂直結構信息,其中體素級表示被簡化。VoxFormer[15]利用稀疏到密集的MAE模塊通過從透視圖投射的稀疏查詢完成占用。SparseOcc進一步以完全稀疏的方式優化占用預測[19]。
然而,上述所有方法都采用了3D體素級表示的范式來進行占用預測,不可避免地依賴于3D特征或Transformer模塊。這種設計為在邊緣芯片上部署它們提出了挑戰,除了Nvidia的解決方案。FlashOcc[34]引入了一個channel-to-height模塊,僅使用2D卷積將扁平化的BEV特征轉換為3D語義占用預測,有著極高的運行效率和可部署性。
3. Architecture
在本節中,我們概述了如何利用所提出的實例中心將全景屬性集成到語義占用任務中。我們首先在第3.1節提供架構的概述。然后,我們在第3.2節深入到占用頭,它預測每個體素的分割標簽。隨后,在第3.3節中,我們詳細闡述了中心度頭,它被用來生成類別感知的實例中心。最后,在第3.4節中,我們描述了全景占用處理,它作為一個高效的后處理模塊,用于生成全景占用。

3.1. Overview Architecture



3.2. Semantic Occupancy Prediction

3.3. Centerness Head
我們框架中提出的centerness head,有兩個目的:
- 加強不同物體之間的區別。通過生成更清晰的語義邊界,centerness head作為輔助子模塊,提高了語義占用分支的性能。在僅執行語義占用預測時,這種增強在推理過程中不需要任何額外的計算資源。隨后的章節將討論這一實證驗證。
- 提供全景占用處理的實例中心的類別標簽和3D位置。在城市場景中,“thing”對象通常在扁平化的鳥瞰圖(BEV)感知中彼此分離,因此從BEV特征生成的“thing”中心與從3D體素特征中識別出的中心一致。
如圖2底部中心塊所示,中心度頭包括中心回歸頭和中心熱圖頭。兩個模塊都包含三個卷積層,搭配3×3的核心。

3.4. Panoptic Occupancy Processing
全景占用處理模塊充當實例標簽的分配模塊,設計得既簡單又有效。它完全依賴于矩陣運算和邏輯運算,不包含任何可訓練參數。這種設計使得全景占用處理的實現直接而高效。









4. Experiment


總結:本文介紹了Panoptic-FlashOcc,這是一種高效且易于部署的全景占用預測框架。它基于已建立的FlashOcc,通過整合centerness head和全景占用處理,將語義占用增強為全景占用。Panoptic-FlashOcc在具有挑戰性的Occ3DnuScenes測試中不僅取得了最快的推理速度,也取得了最好的精度。