













SparseOcc:全稀疏3D全景占用預測(語義+實例雙任務)
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
論文:Fully Sparse 3D Panoptic Occupancy Prediction
鏈接:https://arxiv.org/pdf/2312.17118.pdf
這篇論文的出發點是什么?
占用預測在自動駕駛領域發揮著關鍵作用。先前的方法通常構建密集的3D Volume,忽略了場景的固有稀疏性,這導致了高計算成本。此外,這些方法僅限于語義占用,無法區分不同的實例。為了利用稀疏性并確保實例感知,作者引入了一種新的完全稀疏全景占用網絡,稱為SparseOcc。SparseOcc最初從視覺輸入重建稀疏的3D表示。隨后,它使用稀疏實例查詢來從稀疏3D表示預測每個目標實例。
此外,作者還建立了第一個以視覺為中心的全景占用基準。SparseOcc在Occ3D nus數據集,通過實現26.0的mIoU,同時保持25.4 FPS的實時推理速度。通過結合前8幀的時間建模,SparseOcc進一步提高了其性能,實現了30.9的mIoU,代碼后面將開源。
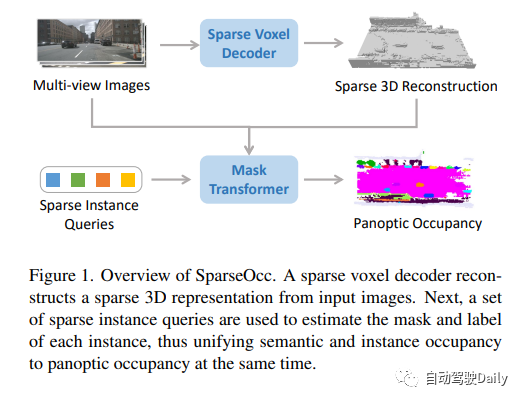
SparseOcc的結構和流程
SparseOcc由兩個步驟組成。首先,作者提出了一種稀疏體素解碼器來重建場景的稀疏幾何結構,它只對場景的非自由區域進行建模,從而顯著節省了計算資源。其次,設計了一個mask transformer,它使用稀疏實例查詢來預測稀疏空間中每個目標的mask和標簽。
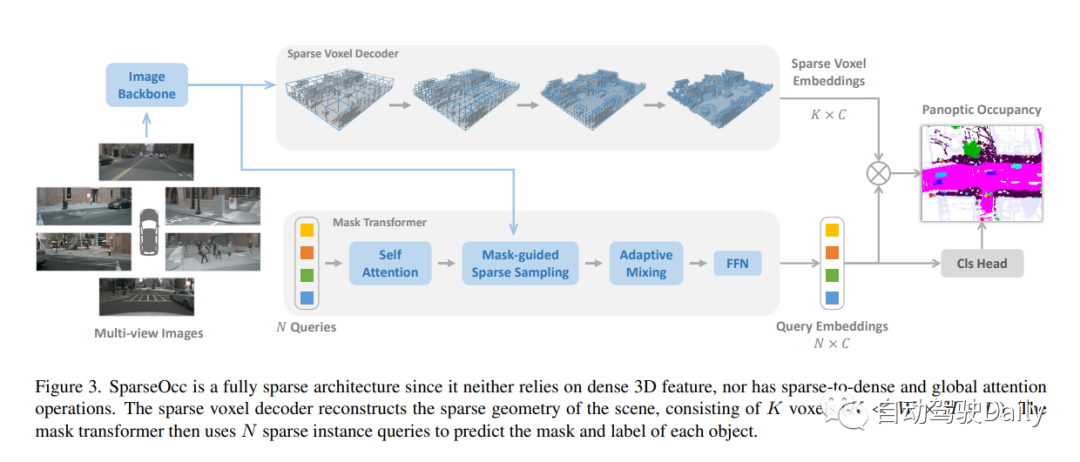
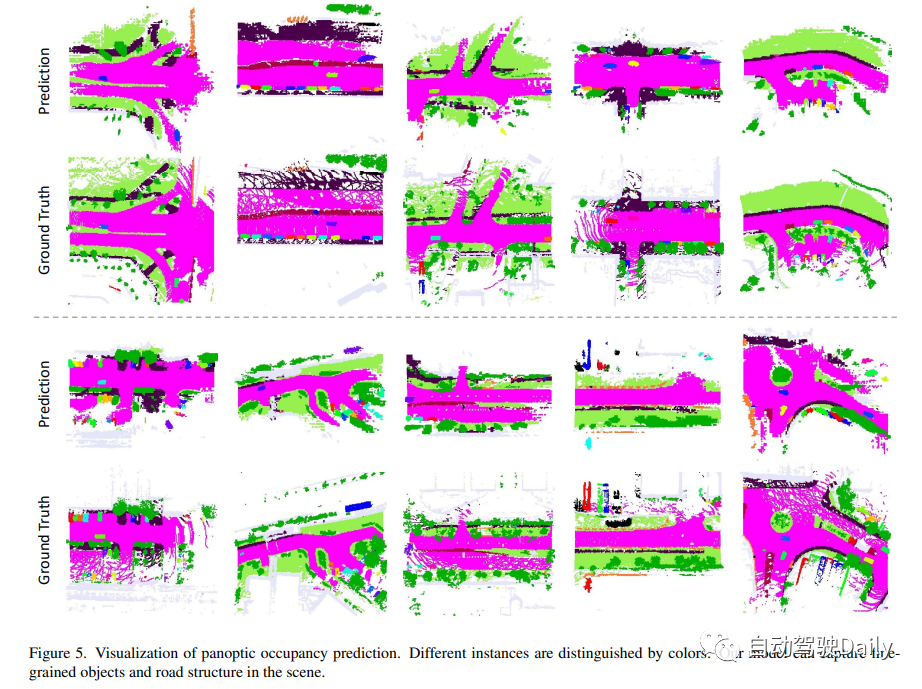
此外,作者還進一步提出了mask-guide的稀疏采樣,以避免mask變換中的密集交叉注意。因此SparseOcc可以同時利用上述兩種稀疏特性,形成完全稀疏的架構,因為它既不依賴于密集的3D特征,也不具有稀疏到密集的全局注意力操作。同時,SparseOcc可以區分場景中的不同實例,將語義占用和實例占用統一為全景占用!
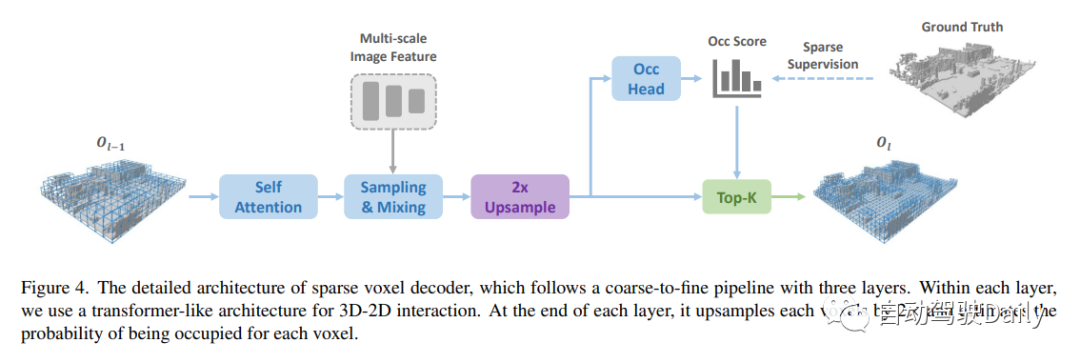
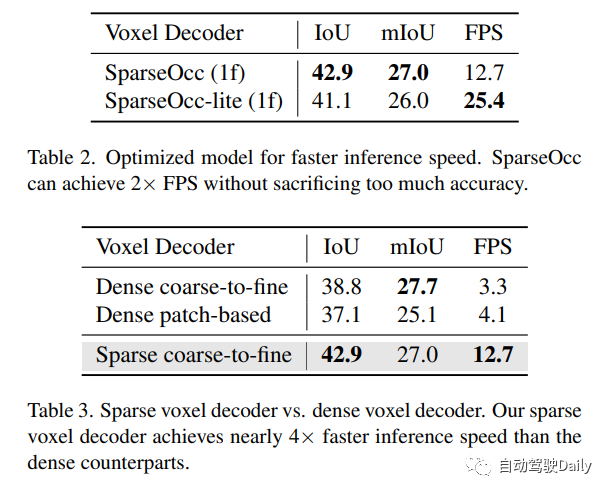
設計的稀疏體素解碼器如圖4所示。通常,它遵循從粗到細的結構,但采用一組稀疏的體素標記作為輸入。在每個層的末尾,我們估計每個體素的占用分數,并基于預測的分數進行稀疏化。在這里,有兩種稀疏化方法,一種是基于閾值(例如,僅保持分數>0.5),另一種是根據top-k。在這項工作中,作者選擇top-k,因為閾值處理會導致樣本長度不相等,影響訓練效率。k是與數據集相關的參數,通過以不同分辨率對每個樣本中非自由體素的最大數量進行計數而獲得,稀疏化后的體素標記將用作下一層的輸入!
時序建模。先前的密集占用方法通常將歷史BEV/3D特征warp到當前時間戳,并使用可變形注意力或3D卷積來融合時間信息。然而,這種方法不適用于我們的情況,因為3D特征是稀疏的。為了處理這一問題,作者利用采樣點的靈活性,將它們wrap到以前的時間戳來對圖像特征進行采樣。來自多個時間戳的采樣特征通過自適應混合進行疊加和聚合。
loss設計:對每一層都進行監督。由于在這一步中重建了一個類不可知的占用,使用二進制交叉熵(BCE)損失來監督占用頭。只監督一組稀疏的位置(根據預測的占用率),這意味著在早期階段丟棄的區域將不會受到監督。
此外,由于嚴重的類別不平衡,模型很容易被比例較大的類別所支配,如地面,從而忽略場景中的其他重要元素,如汽車、人等。因此,屬于不同類別的體素被分配不同的損失權重。例如,屬于類c的體素分配有的損失權重為:
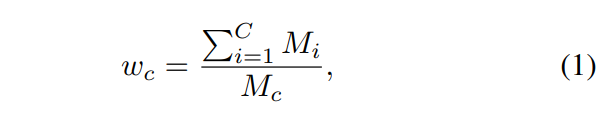
其中Mi是GT中屬于第i類的體素的數量!
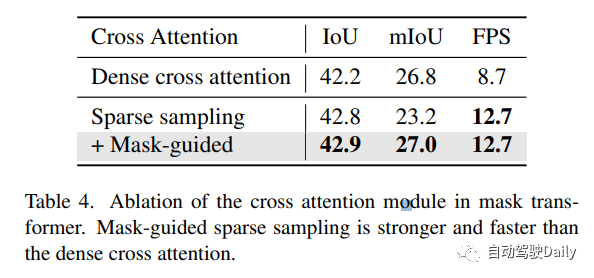
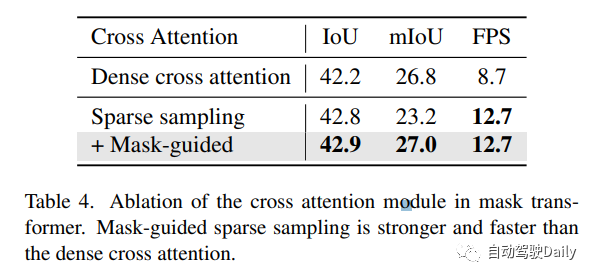
mask引導的稀疏采樣。mask transformer的一個簡單基線是使用Mask2Former中的mask交叉注意模塊。然而,它涉及關鍵點的所有位置,這可能是非常繁重的計算。在這里,作者設計了一個簡單的替代方案。給定前一個(l?1)Transformer解碼器層的mask預測,通過隨機選擇掩碼內的體素來生成一組3D采樣點。這些采樣點被投影到圖像以對圖像特征進行采樣。此外,我們的稀疏采樣機制通過簡單地warp采樣點(如在稀疏體素解碼器中所做的那樣)使時間建模更容易。

實驗結果
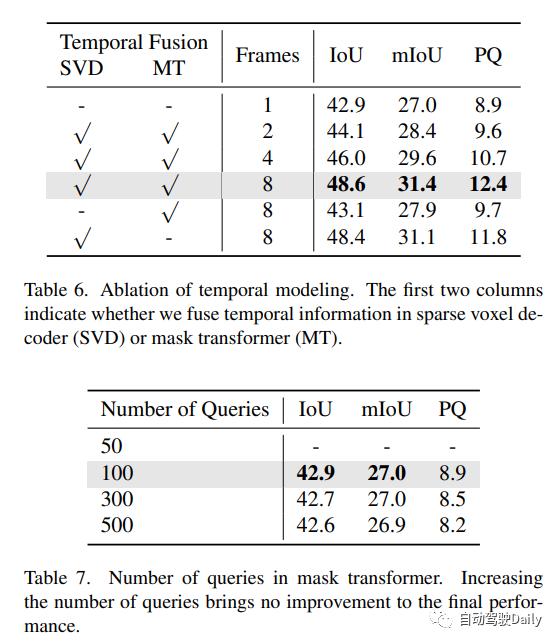
Occ3D nuScenes數據集上的3D占用預測性能。“8f”意味著融合來自7+1幀的時間信息。本文的方法在較弱的設置下實現了與以前的方法相同甚至更高的性能!

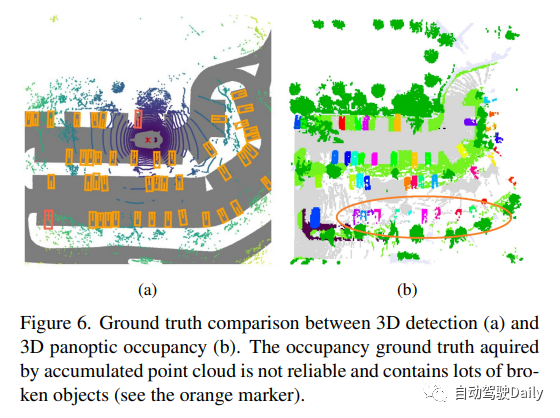

原文鏈接:https://mp.weixin.qq.com/s/CX18meq6DZcIhi0_DElfMw



















