語音克隆達(dá)到人類水平,微軟全新VALL-E 2模型讓DeepFake堪比配音員
最近,微軟發(fā)布了零樣本的文本到語音(TTS)模型VALLE-2,首次實(shí)現(xiàn)了與人類同等的水平,可以說是TTS領(lǐng)域里程碑式的進(jìn)展。

論文地址:https://arxiv.org/pdf/2406.05370
隨著近年來深度學(xué)習(xí)的快速進(jìn)步,用錄音室環(huán)境下的干凈單人語音訓(xùn)練模型,已經(jīng)可以達(dá)到人類同等水平的質(zhì)量,但零樣本TTS依舊是一個(gè)有挑戰(zhàn)性的問題。
「零樣本」意味著推理過程中,模型只能參照一段簡(jiǎn)短的陌生語音樣本,用相同的聲音說出文本內(nèi)容,就像一個(gè)能即時(shí)模仿的口技大師。
聽到這里,不知道你會(huì)不會(huì)突然警覺——有這種能力的模型就是Deepfake的最佳工具!
令人欣慰的是,MSRA考慮到了這一點(diǎn),他們目前只將VALL-E系列作為研究項(xiàng)目,并沒有納入產(chǎn)品或擴(kuò)大使用范圍的計(jì)劃。
雖然VALL-E 2有很強(qiáng)的零樣本學(xué)習(xí)能力可以像配音員一樣模仿聲音,但相似度和自然度取決于語音prompt的長(zhǎng)度和質(zhì)量、背景噪音等因素。
在項(xiàng)目頁面和論文中,作者都進(jìn)行了道德聲明:如果要將VALL-E推廣到真實(shí)世界的應(yīng)用中,至少需要一個(gè)強(qiáng)大的合成語音檢測(cè)模型,并設(shè)計(jì)一套授權(quán)機(jī)制,確保模型在合成語音前已經(jīng)得到了聲音所有者的批準(zhǔn)。
對(duì)于微軟這種只發(fā)論文不發(fā)產(chǎn)品的做法,有些網(wǎng)友表示非常失望。

畢竟最近各種翻車的產(chǎn)品讓我們深深明白,只看demo完全不可靠,沒法自己試用=沒有。

但Reddit上有人揣測(cè):微軟只是不想當(dāng)「第一個(gè)吃螃蟹的人」,不發(fā)模型是擔(dān)心可能的帶來的批評(píng)和負(fù)面輿論。
一旦有了能將VALL-E轉(zhuǎn)化為產(chǎn)品的方法,或者市場(chǎng)上殺出其他競(jìng)品,難道還擔(dān)心微軟有錢不賺嗎?


的確如網(wǎng)友所說,從項(xiàng)目頁面目前放出的demo來看,很難判斷VALL-E的真實(shí)水平。

項(xiàng)目頁面:https://www.microsoft.com/en-us/research/project/vall-e-x/vall-e-2/
共5條文本都是不超過10個(gè)單詞的英文短句,語音prompt的人聲音色都非常相近,英語口音也不夠多樣化。
雖然demo不多,但能隱隱感受到,模型對(duì)英美口音的模仿非常爐火純青,但如果prompt略帶印度或者蘇格蘭口音,就很難達(dá)到以假亂真的程度。
方法
模型前身VALL-E發(fā)布于2023年初,已經(jīng)是TTS在零樣本方面的重大突破。VALL-E能夠用3秒的錄音合成個(gè)性化語音,同時(shí)保留說話者的聲音、情緒和聲學(xué)環(huán)境。
然而VALL-E存在兩方面的關(guān)鍵限制:
1)穩(wěn)定性:推理過程中使用的隨機(jī)采樣(random sampling)可能會(huì)導(dǎo)致輸出不穩(wěn)定,而top-p值較小的核采樣可能會(huì)導(dǎo)致無限循環(huán)問題。雖然可以通過多次采樣和后續(xù)排序來緩解,但會(huì)增加計(jì)算成本。
2)效率:VALL-E的自回歸架構(gòu)綁定了與現(xiàn)成的音頻編解碼器模型相同的高幀率,且無法調(diào)整,導(dǎo)致推理速度較慢。
雖然已經(jīng)有多項(xiàng)研究用于改進(jìn)VALL-E的這些問題,但往往會(huì)使模型的整體架構(gòu)復(fù)雜化,而且增加了擴(kuò)展數(shù)據(jù)規(guī)模的負(fù)擔(dān)。
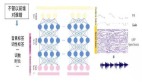
基于這些之前的工作,VALL-E 2包含兩方面的關(guān)鍵創(chuàng)新:重復(fù)感知采樣(repetition aware sampling)和分組代碼建模(grouped code modeling)。
重復(fù)感知采樣是對(duì)VALL-E中隨機(jī)采樣的改進(jìn),能夠自適應(yīng)地采用隨機(jī)采樣或者核采樣(nucleus sampling),選擇的依據(jù)是曾經(jīng)的token重復(fù),因此有效緩解了VALL-E的無限循環(huán)問題,大大增強(qiáng)解碼穩(wěn)定性。

重復(fù)感知采樣的算法描述
分組代碼建模則是將編解碼器代碼劃分為多個(gè)組,自回歸時(shí)每組在單個(gè)幀上建模。不僅減少了序列長(zhǎng)度、加速推理,還通過緩解長(zhǎng)上下文建模問題來提高性能。
值得注意的是,VALL-E 2僅需要簡(jiǎn)單的語音-轉(zhuǎn)錄文本數(shù)據(jù)進(jìn)行訓(xùn)練,不需要額外的復(fù)雜數(shù)據(jù),大大簡(jiǎn)化了數(shù)據(jù)的收集、處理流程,并提高了潛在的可擴(kuò)展性。
具體來說,對(duì)于數(shù)據(jù)集中每條語音-文本數(shù)據(jù),分別用音頻編解碼器編碼器(audio codec encoder)和文本分詞器將其表示為編解碼器代碼??=[??0,??1,…,??(???1)]和文本序列??=[??0,??1,…,??(???1)],用于自回歸(AR)和非自回歸(NAR)模型的訓(xùn)練。

AR和NAR模型都采用Transformer架構(gòu),后續(xù)的評(píng)估實(shí)驗(yàn)設(shè)計(jì)了4種變體進(jìn)行對(duì)比。它們共享相同的NAR模型,但AR模型的組大小分別為1、2、4、8。
推理過程也同樣是AR和NAR模型的結(jié)合。以文本序列??和代碼提示??<??′,0為條件生成目標(biāo)代碼??≥??′,0的第一代碼序列,再用自回歸的方式生成每組的目標(biāo)代碼。

給定??≥??′,0序列后,就可以使用文本條件??和聲學(xué)條件??<??′推斷NAR模型,以生成剩余的目標(biāo)代碼序列??≥??′,≥1。
模型訓(xùn)練使用了Libriheavy語料庫中的數(shù)據(jù),包含7000個(gè)人朗讀英語有聲書的5萬小時(shí)語音。文本和語音的分詞分別使用BPE和開源的預(yù)訓(xùn)練模型EnCodec。
此外,也利用了開源的預(yù)訓(xùn)練模型Vocos作為語音生成的音頻解碼器。
評(píng)估
為了驗(yàn)證模型的語音合成效果是否能達(dá)到人類同等水平,評(píng)估采用了SMOS和CMOS兩個(gè)主觀指標(biāo),并使用真實(shí)的人類語音作為ground truth。
SMOS(Similarity Mean Opinion Score)用于評(píng)估語音與原始提示的相似度,評(píng)分范圍為1~5,增量為0.5分。
CMOS(Comparative Mean Opinion Score)用于評(píng)估合成語音與給定參考語音的比較自然程度,標(biāo)度范圍為-3~3,增量為1。

根據(jù)表2結(jié)果,VALL-E 2的主觀評(píng)分不僅超過了第一代的VALL-E,甚至比人類真實(shí)語音有更完美的表現(xiàn)。
此外,論文也使用了SIM、WER和DNSMOS等客觀指標(biāo)來評(píng)估合成語音的相似度、魯棒性和整體感知質(zhì)量。

在這3個(gè)客觀指標(biāo)上,無論VALL-E 2的組大小如何設(shè)置,相比VALL-E都有全方位的提升,WER和DNSMOS分?jǐn)?shù)也優(yōu)于真實(shí)人類語音,但SIM分?jǐn)?shù)還存在一定差距。
此外,從表3結(jié)果也能發(fā)現(xiàn),VALL-E 2的AR模型組大小為2時(shí),可以取得最優(yōu)效果。
在VCTK數(shù)據(jù)集上的測(cè)評(píng)也可以得到相似的結(jié)論。當(dāng)prompt長(zhǎng)度增加時(shí),分組代碼建模方法可以減少序列長(zhǎng)度,緩解Transformer架構(gòu)中不正確注意力機(jī)制導(dǎo)致的生成錯(cuò)誤,從而在WER分?jǐn)?shù)上得到提升。

作者簡(jiǎn)介
本文第一作者陳三元是哈爾濱工業(yè)大學(xué)和微軟亞洲研究院的聯(lián)合培養(yǎng)博士,他從2020年開始擔(dān)任MSRA自然語言計(jì)算組的實(shí)習(xí)研究員,研究興趣主要是用于語音和音頻處理的預(yù)訓(xùn)練語言模型。