延遲交互模型,為什么是下一代RAG的標配?
張穎峰:英飛流聯合創始人,多年搜索、AI、Infra基礎設施開發經歷,目前正致力于下一代 RAG 核心產品建設。
在 RAG 系統開發中,良好的 Reranker 模型處于必不可少的環節,也總是被拿來放到各類評測當中,這是因為以向量搜索為代表的查詢,會面臨命中率低的問題,因此需要高級的 Reranker 模型來補救,這樣就構成了以向量搜索為粗篩,以 Reranker 模型作精排的兩階段排序架構。
目前排序模型的架構主要有兩類:
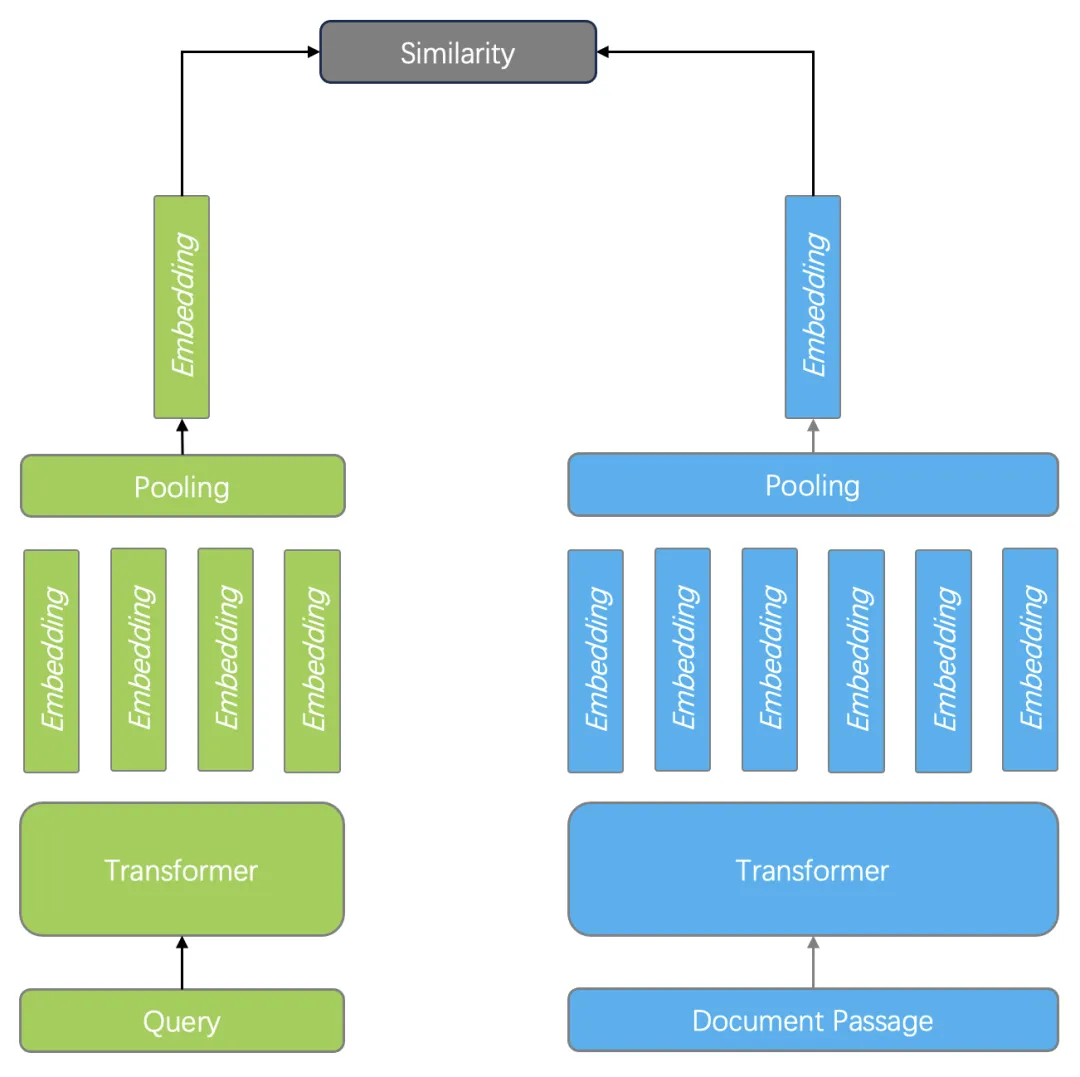
1. 雙編碼器。以 BERT 模型為例,它針對查詢和文檔分別編碼,最后再經過一個 Pooling 層,使得輸出僅包含一個向量。在查詢時的 Ranking 階段,只需要計算兩個向量相似度即可,如下圖所示。雙編碼器既可以用于 Ranking 也可以用于 Reranking 階段,向量搜索實際上就是這種排序模型。由于雙編碼器針對查詢和文檔分別編碼,因此無法捕獲查詢和文檔的 Token 之間的復雜交互關系,在語義上會有很多損耗,但由于只需要向量搜索即可完成排序打分計算,因此執行效率非常高。
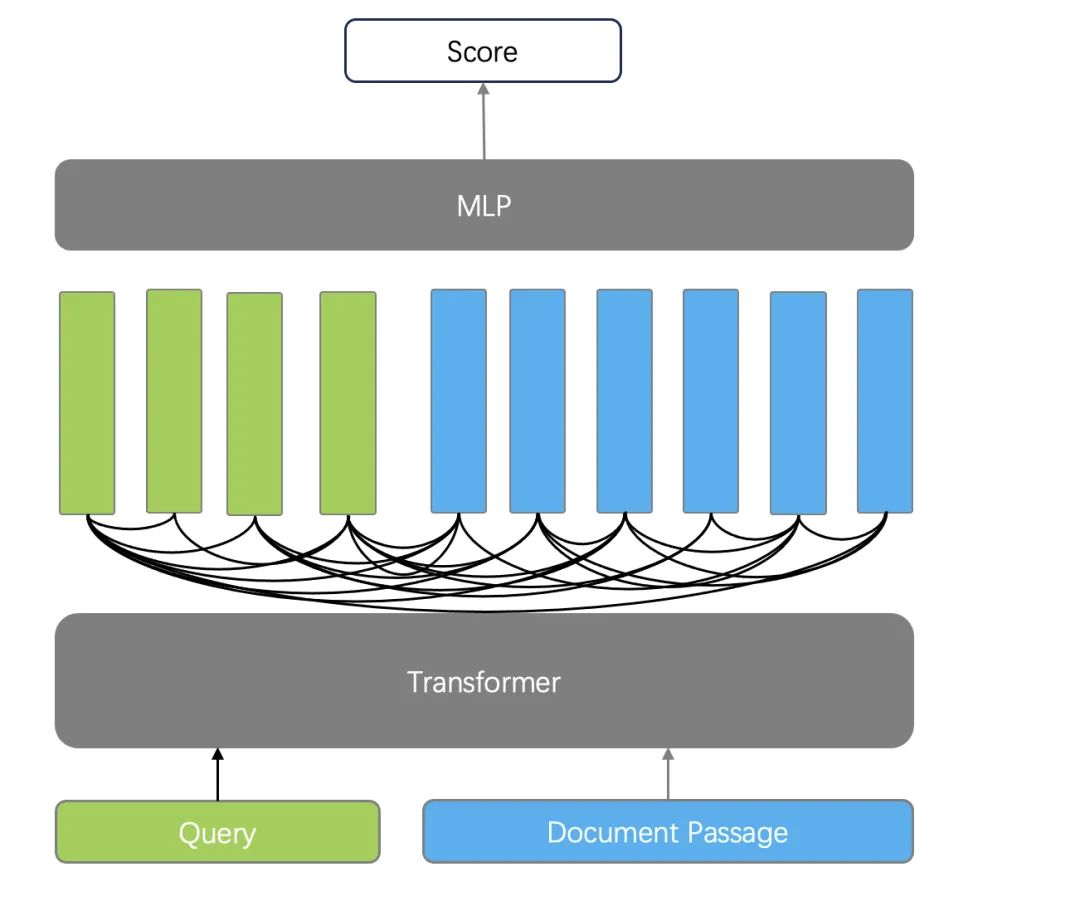
2. 交叉編碼器(Cross Encoder)。Cross-Encoder 使用單編碼器模型來同時編碼查詢和文檔,它能夠捕捉查詢和文檔之間的復雜交互關系,因此能夠提供更精準的搜索排序結果。Cross-Encoder 并不輸出查詢和文檔的 Token 所對應的向量,而是再添加一個分類器直接輸出查詢和文檔的相似度得分。它的缺點在于,由于需要在查詢時對每個文檔和查詢共同編碼,這使得排序的速度非常慢,因此 Cross-Encoder 只能用于最終結果的重排序。例如針對初篩結果的 Top 10 做重排序,仍然需要耗時秒級才可以完成。
今年以來,另一類以 ColBERT【參考文獻1】 為代表的工作,在 RAG 開發社區引起了廣泛關注,如下圖所示,它具備一些顯著區分于以上兩類排序模型的特點:
其一是相比于 Cross Encoder,ColBERT 仍采用雙編碼器策略,將查詢和文檔分別采用獨立的編碼器編碼,因此查詢的 Token 和文檔的 Token 在編碼時互不影響,這種分離使得文檔編碼可以離線處理,查詢時僅針對 Query 編碼,因此處理的速度大大高于 Cross Encoder;
其二是相比于雙編碼器,ColBERT 輸出的是多向量而非單向量,這是從 Transformer 的最后輸出層直接獲得的,而雙編碼器則通過一個 Pooling 層把多個向量轉成一個向量輸出,因此丟失了部分語義。
在排序計算時,ColBERT 引入了延遲交互計算相似度函數,并將其命名為最大相似性(MaxSim),計算方法如下:對于每個查詢 Token 的向量都要與所有文檔 Token 對應的向量進行相似度計算,并跟蹤每個查詢 Token 的最大得分。查詢和文檔的總分就是這些最大余弦分數的總和。例如對于一個有 32 個 Token 向量的查詢(最大查詢長度為 32)和一個有 128 個 Token 的文檔,需要執行 32*128 次相似性操作,如下圖所示。
因此相比之下, Cross Encoder 可以稱作早期交互模型 (Early Interaction Model),而以 ColBERT 為代表的工作可稱為延遲交互模型(Late Interaction Model)。

下圖從性能和排序質量上,分別對以上排序模型進行對比。由于延遲交互模型滿足了對排序過程中查詢和文檔之間復雜交互的捕獲,同時也避免了對文檔 Token 編碼的開銷,因此既能保證良好的排序效果,也能實現較快的排序性能 —— 相同數據規模下, ColBERT 的效率可達 Cross Encoder 的 100 倍以上。因此延遲交互模型是一種非常有前景的排序模型,一個天然的想法是:能否在 RAG 中直接采用延遲交互模型替代向量搜索 + 精排這樣的兩階段排序架構?

為此,我們需要考慮 ColBERT 工程化的一些問題:
1. ColBERT 的 MaxSim 延遲交互相似度函數,計算效率大大高于 Cross Encoder,但相比普通向量搜索,計算開銷仍然很大:因為查詢和文檔之間的相似度,是多向量計算,因此 MaxSim 的開銷是普通向量相似度計算的 M * N 倍 (M 為查詢的 Token 數, N 為 文檔的 Token 數)。針對這些,ColBERT 作者在 2021 年推出了 ColBERT v2 【參考文獻 2】,通過 Cross Encoder 和模型蒸餾,改進了生成的 Embedding 質量,并且采用壓縮技術,對生成的文檔向量進行量化,從而改善 MaxSim 的計算性能。基于 ColBERT v2 包裝的項目 RAGatouille 【參考文獻 3】成為高質量 RAG 排序的解決方案。然而,ColBERT v2 只是一個算法庫,端到端的讓它在企業級 RAG 系統使用,仍然是一件困難的事情。
2. 由于 ColBERT 是預訓練模型,而訓練數據來自于搜索引擎的查詢和返回結果,這些文本數據并不大,例如查詢 Token 數 32 , 文檔 Token 數 128 是典型的長度限制。因此將 ColBERT 用于真實數據時, 超過限制的長度會被截斷,這對于長文檔檢索并不友好。
基于以上問題, 開源 AI 原生數據庫 Infinity 在最新版本中提供了 Tensor 數據類型,并原生地提供端到端的 ColBERT 方案。當 Tensor 作為一種數據類型,ColBERT 編碼輸出的多個向量,就可以直接用一個 Tensor 來存放,因此 Tensor 之間的相似度就可以直接得出 MaxSim 打分。針對 MaxSim 計算量大的問題,Infinity 給出了 2 個方案來優化:其一種是 binary 量化,它可以讓原始 Tensor 的空間只需原始尺寸的 1/32 , 但并不改變 MaxSim 計算的相對排序結果。這種方案主要用于 Reranker,因為需要根據前一階段粗篩的結果取出對應的 Tensor 。另一種是 Tensor Index,ColBERTv2 實際上就是 ColBERT 作者推出的 Tensor Index 實現,Infinity 采用的則是 EMVB【參考文獻 4】,它可以看作是 ColBERT v2 的改進,主要通過量化和預過濾技術,并在關鍵操作上引入 SIMD 指令來加速實現。Tensor Index 只能用來服務 Ranker 而非 Reranker。此外,針對超過 Token 限制的長文本,Infinity 引入了 Tensor Array 類型:

一篇超過 ColBERT 限制的文檔,會被切分成多個段落,分別編碼生成 Tensor 后,都跟原始文檔保存在一行。計算 MaxSim 的時候,查詢跟這些段落分別計算,然后取最大值作為整個文檔的打分。如下圖所示:

因此,采用 Infinity,可以端到端地引入延遲交互模型高質量地服務 RAG。那么,應該是采用 ColBERT 作為 Ranker ,還是 Reranker 呢?下邊我們采用 Infinity 來在真實數據集上進行評測。由于 Infinity 的最新版本實現了有史以來最全的混合搜索方案,召回手段包含向量搜索、全文搜索、稀疏向量搜索,上文所述的 Tensor ,以及這些手段的任意組合,并且提供了多種 Reranker 手段,如 RRF,以及 ColBERT Reranker 等,因此我們在評測中包含了各種混合搜索和 Reranker 的組合。
我們采用 MLDR 數據集進行評測。MLDR 是 MTEB 【參考文獻 5】用來評測 Embedding 模型質量的 benchmark 集,其中 MLDR 是其中一個數據集,全稱為 Multi Long Document Retrieval,一共包含 20 萬長文本數據。評測采用 BGE-M3【參考文獻 6】作為 Embedding 模型,采用 Jina-ColBERT 【參考文獻 7】來生成 Tensor,評測腳本也放到了 Infinity 倉庫【參考文獻 8】。
評測一:ColBERT 作為 Reranker 是否有效。將 20 萬 MLDR 數據分別用 BGE-M3 生成稠密向量和稀疏向量,并插入到 Infinity 數據庫中,數據庫包含 4 列,分別保存原始文本,向量,稀疏向量,以及 Tensor,并分別構建相應全文索引、向量索引、稀疏向量索引。評測包含所有的召回組合,包含單路召回、雙路召回,以及三路召回,如下所示:
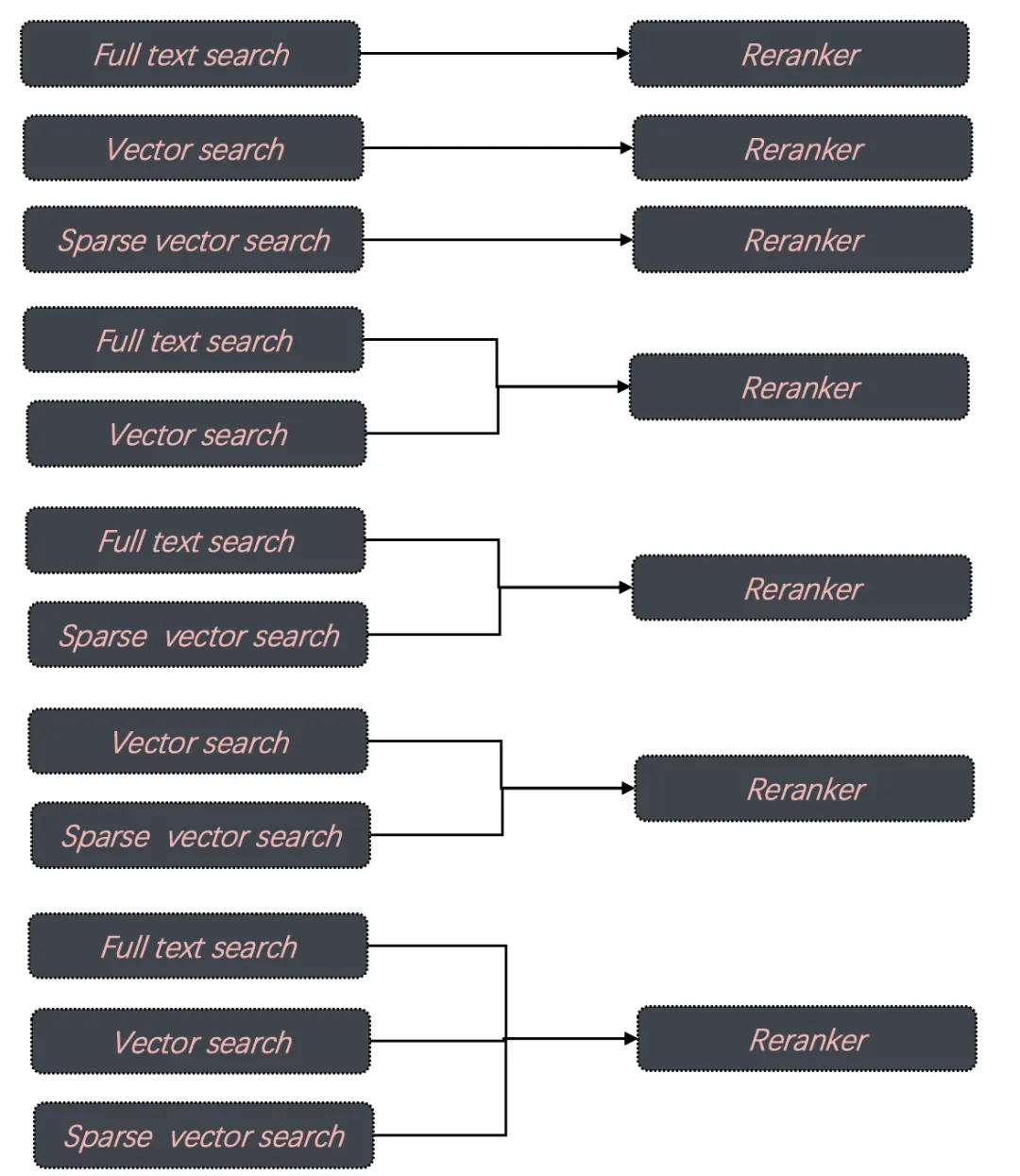
評測指標采用 nDCG@10。其他參數:采用 RRF Reranker 時粗篩返回的 Top N = 1000 ,查詢累計共有 800 條,平均每條查詢長度在 10 個 token 左右。

從圖中看到,所有的召回方案,在采用了 ColBERT Reranker 之后,都有明顯的效果提升。ColBERT 作為一種延遲交互模型,它可以提供跟在 MTEB 的 Reranker 排行榜上位居前列相提并論的排序質量,但是性能卻是它們的 100 倍,所以可以在更大的范圍內進行重排序。圖中給出的結果是針對 Top 100 進行 Reranker,而采用 Top 1000 進行 ColBERT 重排序,數值沒有明顯變化,性能還有明顯下降,因此不推薦采用。傳統上采用基于 Cross Encoder 的外部 Reranker ,Top 10 就會有秒級的延遲,而 Infinity 內部實現了高性能的 ColBERT Reranker,即使針對 Top 100 甚至 Top 1000 做重排序,也不會影響用戶體驗,而召回的范圍卻大大增加,因此可以顯著改進最終的排序效果。此外,這種 ColBERT Reranker 計算只需在純 CPU 架構上即可運行,這也大大降低了部署的成本。
評測二:對比基于 ColBERT 作為 Ranker 而不是 Reranker。因此,這時需要針對 Tensor 這列數據構建 Tensor Index。同時,為了評估 Tensor Index 引入的精度損耗,還進行了暴力搜索。

可以看到,相比 Reranker ,即使是采用沒有精度損失的暴力搜索,也沒有顯著的提升,而采用基于 Tensor Index 的排序質量甚至低于采用 Reranker。然而,作為 Ranker 的查詢時間卻要慢得多:MLDR 數據集包含 20 萬文檔數據,大約 2GB 左右,采用 Jina-ColBERT 轉成 Tensor 數據后,高達 320 G,這是因為 Tensor 數據類型是把一篇文檔的每個 Token 對應的向量都要保存下來, ColBERT 模型的維度是 128 維,因此默認數據量會膨脹 2 個數量級,即使構建了 Tensor Index,在查詢這么多數據的時候,也需要平均 7s 才能返回一個查詢,但得到的結果卻并沒有更好。
因此,很顯然,ColBERT 作為 Reranker 的收益比作為 Ranker 要高得多。當前最佳的 RAG 檢索方案,是在 3 路混合搜索(全文搜索 + 向量 + 稀疏向量)的基礎上加 ColBERT Reranker。有伙伴可能會問了,為了采用 ColBERT Reranker,就需要增加單獨的 Tensor 列,并且該列會相比原始數據集膨脹 2 個數量級,這樣做是否值得?首先:Infinity 針對 Tensor 提供了 Binary 量化手段,作為 Reranker,它并不影響排序結果很多,但卻可以讓最終的數據僅有原始 Tensor 大小的 1/32。其次,即便如此,也會有人認為這樣的開銷過高。然而站在使用者的視角,用更多的存儲,來換取更高的排序質量和更廉價的成本(排序過程無需 GPU),這樣做依然是非常值得的。最后,相信很快就可以推出效果上略有下降,但存儲開銷大大降低的 Late Interaction 模型,作為一款 Data Infra 基礎設施, 對這些變化保持透明,把這些 Trade Off 交給用戶是明智的選擇。
以上是基于 Infinity 在 MLDR 數據集上的多路召回評測,在其他數據集的評測結果,可能會有所不同,但整體上結論不會變 —— 3 路混合搜索 + 基于 Tensor 的重排序,是當前搜索結果質量最高的召回手段。
由此可以看到,ColBERT 及其延遲交互模型,在 RAG 場景具有很大的應用價值,以上是在文本對話內容生成的相關工作,近期,延遲交互模型在多模態場景,也得到了 SOTA 的結果。這就是 ColPali【參考文獻 9】,它改變了 RAG 的工作流程,如下圖所示:
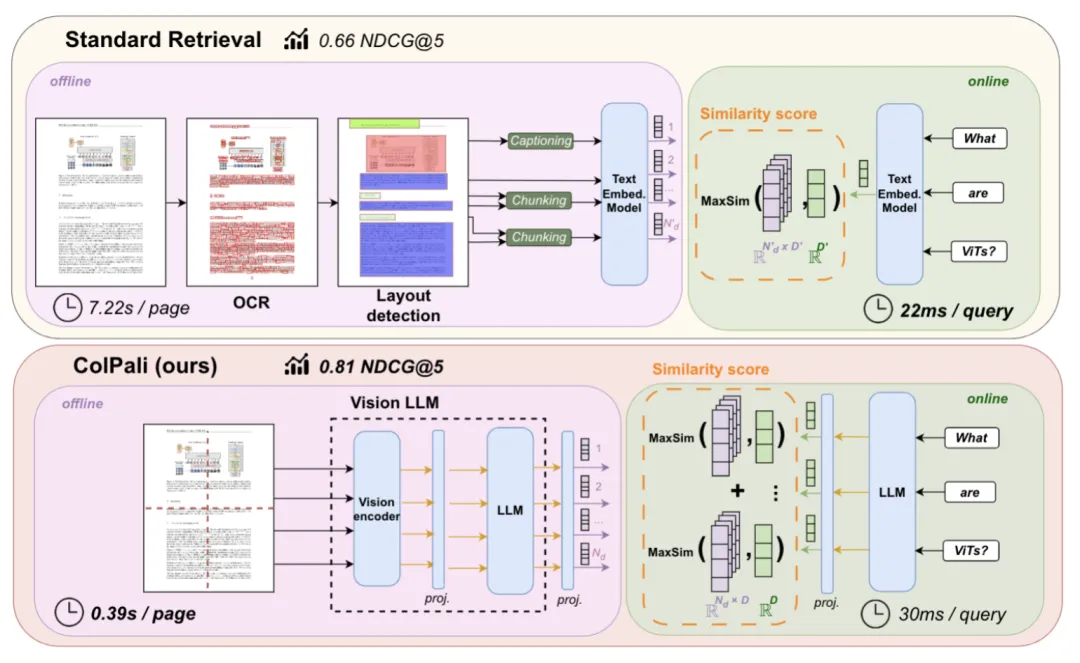
RAG 在面臨復雜格式文檔時,當下的 SOTA ,是采用文檔識別模型,對文檔的布局做識別,并針對識別出的部分結構,例如圖表,圖片等,再分別調用相應的模型,將它們轉化為對應的文字,再用各種格式保存到 RAG 配套的數據庫中。而 ColPali 則省掉了這些步驟,它直接采用多模態模型生成 Embedding 內容。提問的時候,可以直接針對文檔中的圖表進行回答:
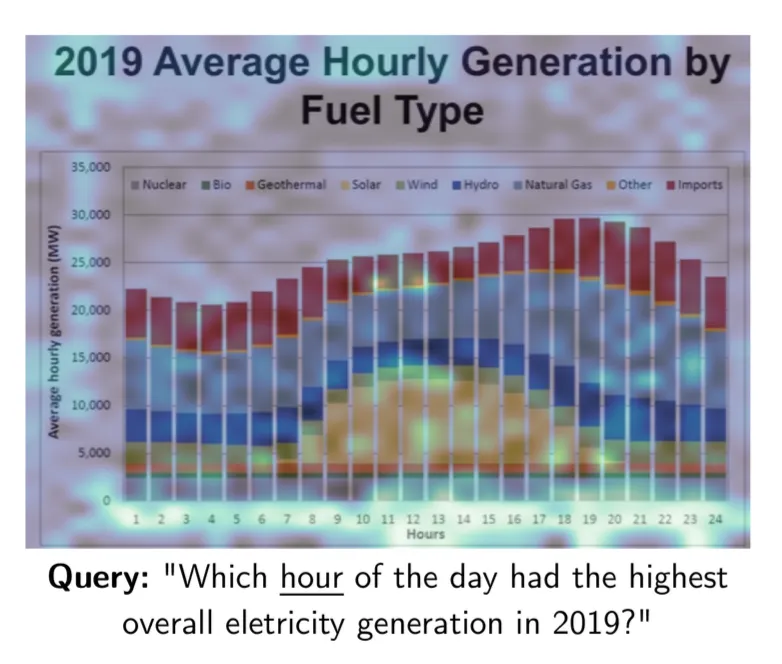
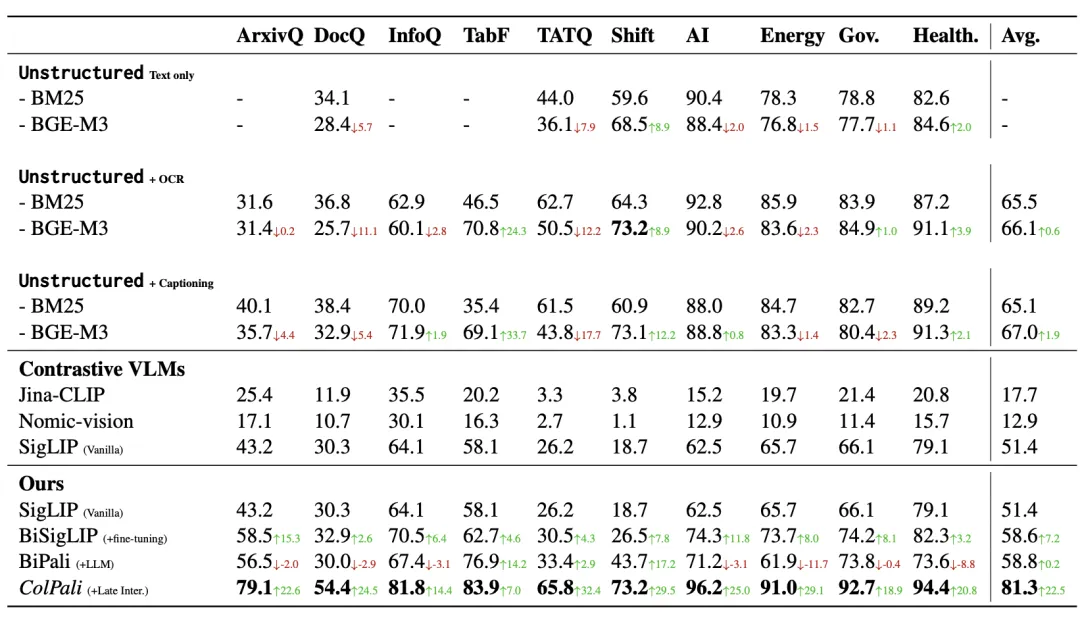
ColPali 模型的訓練跟 ColBERT 類似,也是采用查詢 - 文檔頁面對的形式,從而捕獲查詢和文檔多模態數據之間的語義關聯,只是采用 PaliGemma 【參考文獻 10】用來生成多模態 Embedding 。相比沒有采用 Late Interaction 機制但同樣采用 PaliGemma 生成 Embedding 的方案 BiPali,在 nDCG@5 的評測指標對比是 81.3 vs 58.8,這種差距是就是 “極好” 和 “壓根不能工作” 的區別。
因此,盡管 ColBERT 出現至今已有 4 年時間,可是 Late Interaction 模型在 RAG 的應用才剛剛開始,它必將擴大 RAG 的使用場景,在包含多模態在內的復雜 RAG 場景提供高質量的語義召回。而 Infinity 已經為它的端到端應用做好了準備,歡迎關注和 Star Infinity,https://github.com/infiniflow/infinity, 致力于成為最好的 AI 原生數據庫!