ACL 2024 Oral|我們離真正的多模態思維鏈推理還有多遠?
該文章的第一作者陳麒光,目前就讀于哈工大賽爾實驗室。他的主要研究方向包括大模型思維鏈、跨語言大模型等。
在過去的幾年中,大型語言模型(Large Language Models, LLMs)在自然語言處理(NLP)領域取得了突破性的進展。這些模型不僅能夠理解復雜的語境,還能夠生成連貫且邏輯嚴謹的文本。
然而,隨著科技的發展和應用場景的多樣化,單一文本模態的能力顯然已經不能滿足現代需求。人們日益期待能夠處理和理解多種模態信息(如圖像、視頻、音頻等)的智能系統,以應對更復雜的任務和場景。研究者們開始嘗試將文本 CoT 的能力擴展到多模態思維鏈推理領域,以應對更加復雜和多樣化的任務需求。
最早的多模態思維鏈研究之一是由 Lu 等人 [1] 引入的 ScienceQA 基準,該基準結合了視覺和語言信息,推動了多模態思維鏈(Multi-modal Chain of Thought, MCoT)的研究。ScienceQA 數據集的出現,使得研究者們能夠在一個統一的框架下評估多模態模型的思維鏈推理能力。
進一步地,Zhang 等人 [2] 的研究更是將 MCoT 的性能推向了一個新高,使得模型在 ScienceQA 數據集上的表現超過了人類的水平 (93%>88%)。然而,當前的多模態思維鏈研究是否真正解決了所有挑戰?隨著 ScienceQA 等基準測試的成績不斷刷新,我們是否可以認為多模態推理問題已經迎刃而解?
研究者們通過深入分析發現,當前的多模態思維鏈基準仍然存在嚴重的問題,導致對模型實際能力的高估。當前的多模態思維鏈基準仍面臨以下三個嚴重的問題:視覺模態推理缺失、僅有單步視覺模態推理以及領域覆蓋不足。
這些問題嚴重制約了多模態思維鏈領域的發展。因此,研究者提出了一個新的基準
 (Multi-Domain Multi-step Multi-modal Chain-of-Thought),旨在解決上述問題,并推動多領域、多步和多模態思維鏈的進步。研究者們還進行了全面的評估,涉及豐富的多模態推理設置與方法。
(Multi-Domain Multi-step Multi-modal Chain-of-Thought),旨在解決上述問題,并推動多領域、多步和多模態思維鏈的進步。研究者們還進行了全面的評估,涉及豐富的多模態推理設置與方法。
研究者們還發現當前的多模態大模型在  上的表現存在巨大的性能缺陷,盡管它們在以前的傳統多模態思維鏈基準上表現優異。最后,研究團隊希望
上的表現存在巨大的性能缺陷,盡管它們在以前的傳統多模態思維鏈基準上表現優異。最后,研究團隊希望  能夠成為一個有價值的資源,為多領域、多步和多模態思維鏈的研究提供開創性的基礎。
能夠成為一個有價值的資源,為多領域、多步和多模態思維鏈的研究提供開創性的基礎。

- 榜單地址:https://lightchen233.github.io/M3CoT.github.io/leaderboard.html
- 論文地址:https://arxiv.org/abs/2405.16473
- 代碼地址:https://github.com/LightChen233/M3CoT
動機
盡管在 MCoT 研究領域取得了顯著進展,但現有基準仍然存在諸多不足:
1. 視覺模態推理缺失:模型往往可以僅基于文本模態生成推理和答案,這并不能真實反映多模態 CoT 模型的能力。
2. 單步視覺模態推理:比如說,只需要看到單次圖片中的 “羽毛” 便可直接獲得答案。而在實際應用中,多步推理更為常見和必要,要求模型在推理的過程中動態的多次結合多模態信息進行綜合推理。
3. 領域缺失:對于思維鏈來說,常識推理和數學推理是該領域的重要組成部分,而現有基準缺乏對常識和數學等重要領域的覆蓋,限制了多模態 CoT 能力的綜合評估。

針對以上問題,研究者們開發了一個新基準 ,并希望推動多領域、多步和多模態思維鏈的研究與發展。
,并希望推動多領域、多步和多模態思維鏈的研究與發展。

數據構建過程

 的構建涉及如下四個關鍵階段:
的構建涉及如下四個關鍵階段:
- 視覺模態推理缺失樣本移除:首先,為解決視覺模態推理缺失的問題,
 利用自動和手動相結合的方式移除了那些無需圖像即可得出答案的樣本。
利用自動和手動相結合的方式移除了那些無需圖像即可得出答案的樣本。 - 多步多模態樣本構建:這一階段中,為了保證基準滿足多步多模態的要求,
 首先自動的去除了推理路徑過短的樣本,隨后通過手動去除和優化樣本,確保每一個樣本確實需要跨模態的多步推理。
首先自動的去除了推理路徑過短的樣本,隨后通過手動去除和優化樣本,確保每一個樣本確實需要跨模態的多步推理。 - 多模態 CoT 領域增強:此外,
 通過引入數學和常識領域的數據,將 LaTeX 代碼轉為圖片,并利用大模型生成更多的問題、推理路徑和答案,增強了基準的多樣性和挑戰性。
通過引入數學和常識領域的數據,將 LaTeX 代碼轉為圖片,并利用大模型生成更多的問題、推理路徑和答案,增強了基準的多樣性和挑戰性。 - 質量檢查:為了保證數據集的質量,
 實施了多輪人工審核和自動檢測,確保數據的一致性和準確性。
實施了多輪人工審核和自動檢測,確保數據的一致性和準確性。
主流多模態大語言模型評測結果
研究者們在多個大型視覺語言模型(VLLMs)上進行了廣泛的實驗,包括 Kosmos-2、InstructBLIP、LLaVA-V1.5、CogVLM、Gemini 和 GPT4V 等。研究者們還探索了一些提示策略,如直接提交樣本、思維鏈提示(CoT)[3] 以及描述性提示(Desp-CoT)[4] 和場景圖思維鏈提示策略(CCoT)[5]。
實驗結果與結論如下所示:
- 開源模型與 GPT4V 仍有差距:盡管這些模型在現有基準測試中表現優異,但在
 上的表現仍有顯著差距。尤其是當前的開源 VLLMs 在多步多模態推理方面表現不佳,與 GPT4V 相比存在顯著差距。
上的表現仍有顯著差距。尤其是當前的開源 VLLMs 在多步多模態推理方面表現不佳,與 GPT4V 相比存在顯著差距。 - GPT4V 與人類仍有差距:此外,盡管 GPT4V 在
 上的表現優于其他 VLLMs,但與人類表現相比仍存在顯著差距。這表明,當前的 VLLMs 在處理復雜的多模態推理任務時仍需進一步改進。
上的表現優于其他 VLLMs,但與人類表現相比仍存在顯著差距。這表明,當前的 VLLMs 在處理復雜的多模態推理任務時仍需進一步改進。 - 多模態思維鏈涌現現象:視覺大模型在參數級別超過 100 億(≥13B)時表現出思維鏈涌現現象。

分析
此外,為了回答如何能夠在  上獲得更好的表現。研究者們提供了更全面的分析,從而揭示了當前 VLLMs 在多步多模態推理方面的顯著不足,為未來的優化提供了方向。
上獲得更好的表現。研究者們提供了更全面的分析,從而揭示了當前 VLLMs 在多步多模態推理方面的顯著不足,為未來的優化提供了方向。
- 單步推理任務的表現遠優于多步推理任務。模型在解決多步多模態推理時性能與單步多模態推理有接近 30% 的差距,且隨步驟數增加,性能遞減。這表明模型在處理復雜多步驟推理時仍存在困難。

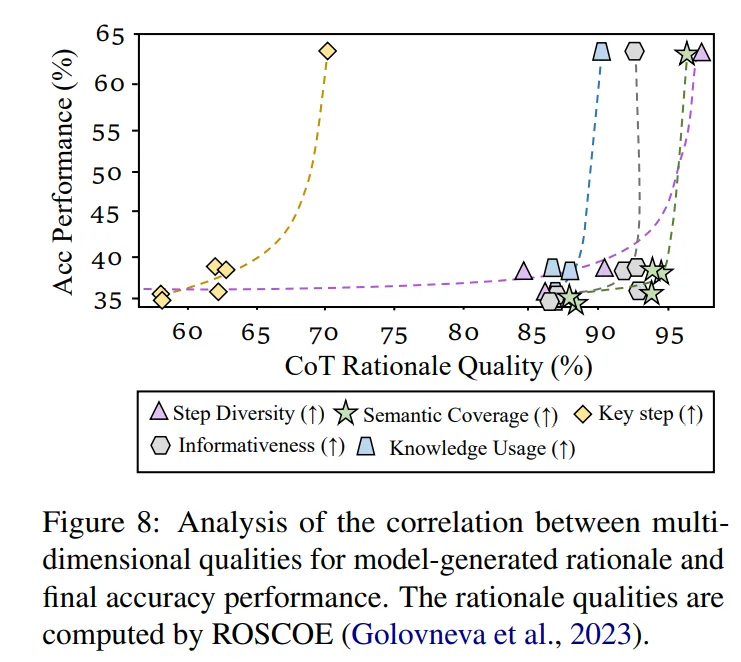
- 提高模型生成的推理過程質量對于提升
 的表現至關重要。通過評估多維度的推理質量,研究者們觀察到推理質量的提升與
的表現至關重要。通過評估多維度的推理質量,研究者們觀察到推理質量的提升與  的性能呈現指數級相關關系。提升多模態推理的邏輯質量是解決
的性能呈現指數級相關關系。提升多模態推理的邏輯質量是解決  的關鍵瓶頸之一。
的關鍵瓶頸之一。
- 多模態信息交互的增加能夠顯著提升模型的推理性能。由于
 要求推理時動態的包含多個跨模態推理步驟,則至少有 2 步跨模態推理,而現有模型推理過程中,平均的跨模態推理步驟數小于 1。這說明未來的研究應注重提高推理過程的質量和多模態信息的交互,以解決當前模型在
要求推理時動態的包含多個跨模態推理步驟,則至少有 2 步跨模態推理,而現有模型推理過程中,平均的跨模態推理步驟數小于 1。這說明未來的研究應注重提高推理過程的質量和多模態信息的交互,以解決當前模型在  上的表現不足。
上的表現不足。

探索
在此基礎上,研究者們進一步探究了當前各種常用的多模態方法與設置,探究是否能夠有效的解決  中的問題。
中的問題。
工具使用探索
在多模態推理中,工具使用被認為是提高模型性能的一種有效策略。研究者們在實驗中評估了多種工具使用方法,包括 HuggingGPT、VisualChatGPT、IdealGPT 和 Chameleon 等模型。
文本大模型使用多模態工具在  上表現不佳:實驗結果表明,盡管這些工具在單模態任務中表現良好,但在
上表現不佳:實驗結果表明,盡管這些工具在單模態任務中表現良好,但在  基準上的表現仍存在顯著差距。例如,HuggingGPT 在處理復雜的多步推理任務時,由于缺乏對視覺信息的有效利用,表現較為遜色。此外,VisualChatGPT 和 IdealGPT 在處理需要多模態交互的任務時,表現也未能達到預期。這些結果表明,當前的工具使用框架需要進一步改進,以更好地整合和利用多模態信息。
基準上的表現仍存在顯著差距。例如,HuggingGPT 在處理復雜的多步推理任務時,由于缺乏對視覺信息的有效利用,表現較為遜色。此外,VisualChatGPT 和 IdealGPT 在處理需要多模態交互的任務時,表現也未能達到預期。這些結果表明,當前的工具使用框架需要進一步改進,以更好地整合和利用多模態信息。

上下文學習探索
在上下文學習方面,研究者們探索了不同的示例策略對模型性能的影響。具體而言,研究者們評估了純文本示例以檢測模型在多模態推理時是否會進行文本形式的學習,同時還評估了多模態示例以檢測模型在多模態推理時是否會利用多模態示例進行上下文學習。
純文本示例無法提高  上的性能:實驗結果顯示,對于純文本示例來說,這些樣本數量對模型性能影響幾乎可以忽略不計,這說明,純粹的文本形式的模仿并不足以解決
上的性能:實驗結果顯示,對于純文本示例來說,這些樣本數量對模型性能影響幾乎可以忽略不計,這說明,純粹的文本形式的模仿并不足以解決  問題。
問題。
圖像和文本交錯的多模態示例甚至可能會損害  上的性能:對于多模態示例來說,上下文學習僅僅能夠提高較大模型的能力。然而,對于一些訓練過多模態交互數據的模型來說,甚至會隨著樣本數量增加而出現性能下降。因此,研究者們認為,未來需要將包含邏輯的更高質量的圖像和文本交錯示例用于上下文學習的訓練,并增強多模態大模型的多模態交互能力,才能夠在一定程度上改善模型的表現。
上的性能:對于多模態示例來說,上下文學習僅僅能夠提高較大模型的能力。然而,對于一些訓練過多模態交互數據的模型來說,甚至會隨著樣本數量增加而出現性能下降。因此,研究者們認為,未來需要將包含邏輯的更高質量的圖像和文本交錯示例用于上下文學習的訓練,并增強多模態大模型的多模態交互能力,才能夠在一定程度上改善模型的表現。

指令微調探索
為了進一步提高模型在  上的表現,研究者們進行了微調實驗。
上的表現,研究者們進行了微調實驗。
指令微調能夠顯著增強傳統視覺語言模型(VLMs)的性能:指令微調使傳統視覺語言模型超越零樣本視覺大模型,這就是我們的數據集在提高 VLM 有效性方面的價值。經過微調的 VLM(最低為 44.85%)優于大多數具有零樣本提示的開源 VLLM(最高為 38.86%)。
指令微調能夠進一步地增強大型視覺語言模型的性能:通過在  數據集上進行微調,LLaVA-V1.5-13B 模型的整體準確率提高了近 20%,并接近了 GPT4V 的水平。
數據集上進行微調,LLaVA-V1.5-13B 模型的整體準確率提高了近 20%,并接近了 GPT4V 的水平。
因此,研究者們建議未來的研究可以更多地關注指令微調技術,以進一步提升多模態推理模型的表現。

結論及展望
研究者們引入了一個新的基準  ,旨在推動多領域、多步和多模態思維鏈的研究。研究者們的實驗和分析表明,盡管現有的 VLLMs 在某些任務上表現優異,但在更復雜的多模態推理任務上仍有很大改進空間。通過提出
,旨在推動多領域、多步和多模態思維鏈的研究。研究者們的實驗和分析表明,盡管現有的 VLLMs 在某些任務上表現優異,但在更復雜的多模態推理任務上仍有很大改進空間。通過提出  ,研究者們希望能夠重新評估現有的進展,并通過指出新的挑戰和機會,激發未來的研究。研究者們期待
,研究者們希望能夠重新評估現有的進展,并通過指出新的挑戰和機會,激發未來的研究。研究者們期待  能夠成為一個有價值的資源,為多領域、多步和多模態思維鏈的研究提供開創性的基礎。
能夠成為一個有價值的資源,為多領域、多步和多模態思維鏈的研究提供開創性的基礎。