














譯者 | 李睿
審校 | 重樓
Vaswani等研究人員在2017年發表的開創性論文《注意力是你所需要的一切》中介紹了Transformer架構,該架構不僅徹底改變了語音識別技術,也改變了許多其他領域。本文探討了Transformer的演變,追溯其從最初設計到最先進模型的發展軌跡,并重點介紹這一過程中取得的重大進展。
原始Transformer
原始Transformer模型引入了幾個突破性的概念:
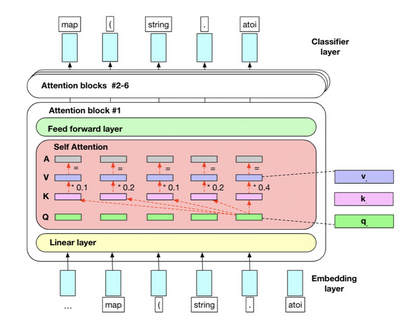
- 自關注機制:這讓模型確定每個組件在輸入序列中的重要性。
- 位置編碼:在序列中添加有關令牌位置的信息,使模型能夠捕獲序列的順序。
- 多頭注意力:這一功能允許模型同時關注輸入序列的不同部分,增強其理解復雜關系的能力。
- 編碼器-解碼器架構:分離輸入和輸出序列的處理,實現更高效的序列到序列學習。
這些元素結合在一起,創建了一個強大而靈活的架構,其性能優于之前的序列到序列(S2S)模型,特別是在機器翻譯任務中。
編碼器-解碼器 Transformer 及其超越發展
最初的編碼器-解碼器架構已經被改編和修改,并取得了一些顯著的進步:
- BART (雙向和自回歸Transformer):結合了雙向編碼和自回歸解碼,在文本生成方面取得了顯著的成功。
- T5 (文本到文本遷移轉換器):將所有NLP任務重新轉換為文本到文本的問題,促進多任務處理和遷移學習。
- mT5(多語言T5):將T5的功能擴展到101種語言,展示了其對多語言環境的適應性。
- MASS (掩碼序列到序列預訓練):為序列到序列學習引入新的預訓練目標,提高了模型性能。
- UniLM(統一語言模型):集成雙向、單向和序列到序列語言建模,為各種NLP任務提供統一的方法。
BERT和預訓練的興起
谷歌公司于2018年推出的BERT(基于Transformer的雙向編碼器表示)是自然語言處理領域的一個重要里程碑。BERT推廣并完善了在大型文本語料庫上進行預訓練的概念,導致了NLP任務方法的范式轉變。以下了解BERT的創新及其影響。
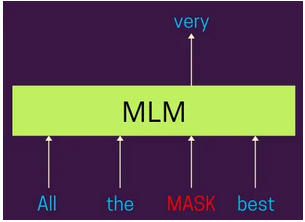
掩碼語言建模(MLM)
- 過程:隨機屏蔽每個序列中15%的令牌。然后,該模型嘗試根據周圍的場景來預測這些被屏蔽的令牌。
- 雙向場景:與之前從左到右或從右到左處理文本的模型不同,掩碼語言建模(MLM)。
- 允許BERT同時從兩個方向考慮場景。
- 深入理解:這種方法迫使模型對語言有更深入的了解,包括語法、語義和場景關系。
- 變體掩碼:為了防止模型在微調過程中過度依賴[MASK]令牌(因為[MASK]在推理過程中不會出現),80%的掩碼令牌被[MASK]替換,10%被隨機單詞替換,10%保持不變。
下句預測(NSP)
- 過程:模型接收成對的句子,并且預測原文中的第二個句子是否緊跟著第一個句子。
- 執行:50%的時間,第二個句子是實際的下一個句子,50%是從語料庫中隨機抽取的句子。
- 目的:這項任務幫助BERT理解句子之間的關系,這對于問答和自然語言推理等任務至關重要。

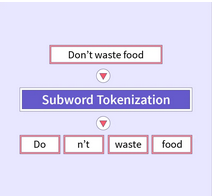
子單詞令牌化
- 過程:將單詞劃分為子單詞單元,平衡詞匯量的大小和處理詞匯外單詞的能力。
- 優點:這種方法使BERT能夠處理各種語言,并有效地處理形態豐富的語言。
GPT:生成式預訓練Transformer
OpenAI公司的生成式預訓練Transformer (GPT)系列代表了語言建模方面的重大進步,重點關注用于生成任務的Transformer解碼器架構。GPT的每次迭代都在規模、功能和對自然語言處理的影響方面帶來了實質性的改進。
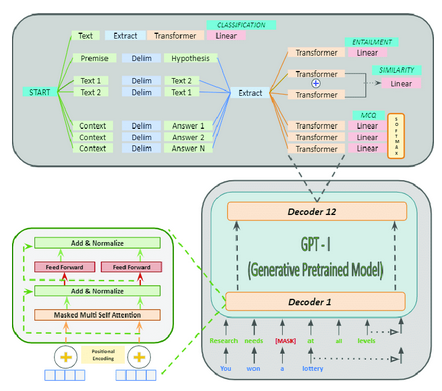
GPT-1 (2018年發布)
第一個GPT模型引入了大規模無監督語言理解的預訓練概念:
- 架構:基于12層和1.17億個參數的Transformer解碼器。
- 預訓練:利用各種在線文本。
- 任務:根據前面的單詞預測下一個單詞。
- 創新:證明了一個單一的無監督模型可以針對不同的下游任務進行微調,在沒有特定任務架構的情況下實現高性能。
- 影響:GPT-1展示了NLP中遷移學習的潛力,其中在大型語料庫上預訓練的模型可以通過相對較少的標記數據對特定任務進行微調。
GPT-2 (2019年發布)
GPT-2顯著增加了模型大小,并表現出令人印象深刻的零樣本學習能力:
- 架構:最大的版本有15億個參數,是GPT-1的10倍多。
- 訓練數據:使用更大、更多樣化的網頁數據集。
- 特點:能夠在各種主題和風格上生成連貫和場景相關的文本。
- 零樣本學習: 通過簡單地在輸入提示中提供指令,展示了執行未經專門訓練的任務的能力。
- 影響:GPT-2強調了語言模型的可擴展性,并引發了關于強大文本生成系統的倫理影響的討論。
GPT-3 (2020年發布)
GPT-3代表了規模和能力的巨大飛躍:
- 架構:由1750億個參數組成,比GPT-2大100多倍。
- 訓練數據:利用來自互聯網、書籍和維基百科的大量文本。
- 少樣本學習:在不需要微調的情況下,只用少量例子或提示就能完成新任務。
- 多功能性:展示了在各種任務中的熟練程度,包括翻譯、問答、文本摘要,甚至基本的編碼。
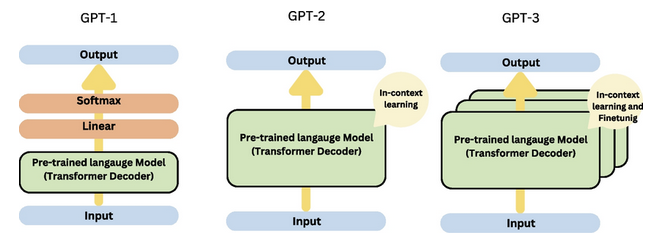
GPT-4 (2023年發布)
GPT-4在之前版本模型奠定的基礎上,進一步拓展了語言模型的可能性。
- 架構:雖然具體的架構細節和參數數量尚未公開披露,但GPT-4被認為比GPT-3更大、更復雜,其底層架構得到了增強,以提高效率和性能。
- 訓練數據:GPT-4在更廣泛和多樣化的數據集上進行了訓練,包括廣泛的互聯網文本、學術論文、書籍和其他來源,確保了對各種學科的全面理解。
- 先進的少樣本和零樣本學習:GPT-4表現出更強的能力,以最少的例子執行新任務,進一步減少了對特定任務微調的需要。
- 增強的場景理解:場景感知的改進使GPT-4能夠生成更準確、更符合場景的響應,使其在對話系統、內容生成和復雜問題解決等應用程序中更加有效。
- 多模態功能:GPT-4將文本與其他模態(例如圖像和可能的音頻)集成在一起,實現了更復雜、更通用的人工智能應用程序,可以處理和生成不同媒體類型的內容。
- 倫理考慮和安全:OpenAI公司非常重視GPT-4的倫理部署,實施先進的安全機制來減少潛在的濫用,并確保負責任地使用該技術。
注意力機制的創新
研究人員對注意力機制提出了各種修改,并取得了重大進展:
- 稀疏注意力:通過關注相關元素的子集,可以更有效地處理長序列。
- 自適應注意力:根據輸入動態調整注意力持續時間,增強模型處理不同任務的能力。
- 交叉注意力變體:改進解碼器處理編碼器輸出的方式,從而產生更準確和場景相關的生成。
結論
Transformer架構的演變是顯著的。從最初的介紹到現在最先進的模型,Transformer一直在突破人工智能的極限。編碼器-解碼器結構的多功能性,加上注意力機制和模型架構的不斷創新,將繼續推動NLP及其他領域的進步。隨著研究的繼續,人們可以期待進一步的創新,將這些強大的模型的功能和應用擴展到各個領域。
原文標題:Exploring the Evolution of Transformers: From Basic To Advanced Architectures,作者:Suri Nuthalapati























