九大服務架構性能優化方式
作者 | jialiangsun
最近做了一些服務性能優化,文章池服務平均耗時跟p99耗時都下降80%左右,事件底層頁服務平均耗時下降50%多左右,主要優化項目中一些不合理設計,例如服務間使用json傳輸數據,監控上報處理邏輯在主流程中,重復數據每次都請求下游服務,多個耗時操作串行請求等,這些問題都對服務有著嚴重的性能影響。

在服務架構設計時通常可以使用一些中間件去提升服務性能,例如使用mysql,redis,kafka等,因為這些中間件有著很好的讀寫性能。除了使用中間件提升服務性能外,也可以通過探索它們通過什么樣的底層設計實現的高性能,將這些設計應用到我們的服務架構中。
常用的性能優化方法可以分為以下幾種:
性能優化九大方式
1.緩存
性能優化,緩存為王,所以開始先介紹一下緩存。緩存在我們的架構設計中無處不在的,常規請求是瀏覽器發起請求,請求服務端服務,服務端服務再查詢數據庫中的數據,每次讀取數據都會至少需要兩次網絡I/O,性能會差一些,我們可以在整個流程中增加緩存來提升性能。首先是瀏覽器測,可以通過Expires、Cache-Control、Last-Modified、Etag等相關字段來控制瀏覽器是否使用本地緩存。
其次我們可以在服務端服務使用本地緩存或者一些中間件來緩存數據,例如redis。redis之所以這么快,主要因為數據存儲在內存中,不需要讀取磁盤,因為內存讀取速度通常是磁盤的數百倍甚至更多;
然后在數據庫測,通常使用的是mysql,mysql的數據存儲到磁盤上,但是mysql為了提升讀寫性能,會利用bufferpool緩存數據頁。mysql讀取時會按照頁的粒度將數據頁讀取到bufferpool中,bufferpool中的數據頁使用LRU算法淘汰長期沒有用到的頁面,緩存最近訪問的數據頁。
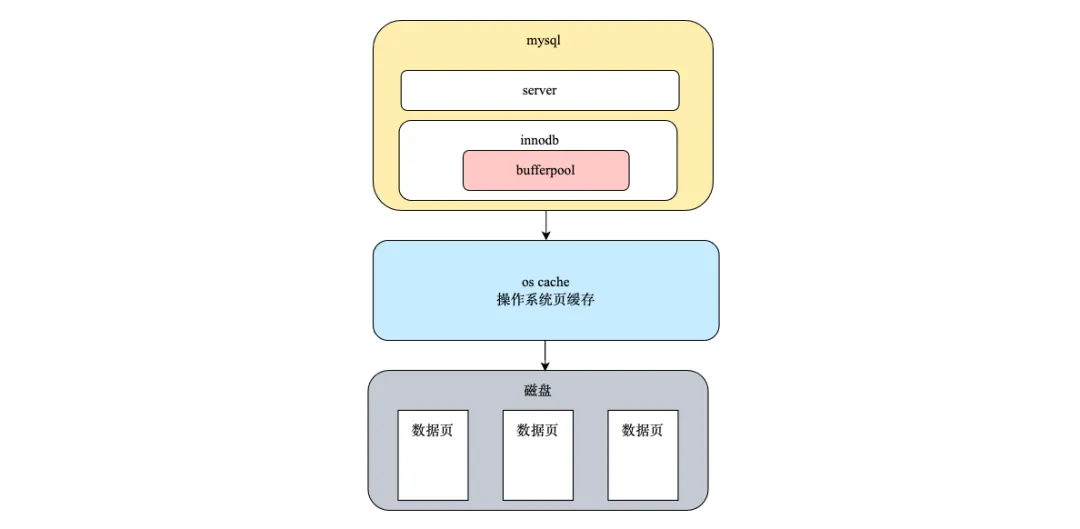
此外小到cpu的l1、l2、l3級cache,大到瀏覽器緩存都是為了提高性能,緩存也是進行服務性能優化的重要手段,使用緩存時需要考慮以下幾點:
(1) 使用什么樣的緩存
使用緩存時可以使用redis或者機器內存來緩存數據,使用redis的好處可以保證不同機器讀取數據的一致性,但是讀取redis會增加一次I/O,使用內存緩存數據時可能會出現讀取數據不一致,但是讀取性能好。例如文章的閱讀數數據,如果使用機器內存作為緩存,容易出現不同機器上緩存數據的不一致,用戶不同刷次會請求到不同服務端機器,讀取的閱讀數不一致,可能會出現閱讀數變小的情況,用戶體驗不好。對于閱讀數這種經常變更的數據比較適合使用redis來統一緩存。
也可以將兩者結合提升服務的性能,例如在內容池服務,利用redis跟機器內存緩存熱點文章詳情,優先讀取機器內存中的數據,數據不存在的時候會讀取redis中的緩存數據,當redis中的數據也不存在的時候,會讀取下游持久化存儲中的全量數據。其中內存級緩存過期時間為15s,在數據變更的時候不保證數據一致性,通過數據自然過期來保證最終一致性。redis中緩存數據需要保證與持久化存儲中數據一致性,如何保證一致性在后續講解。可以根據自己的業務場景可以選擇合適的緩存方案。
使用緩存時可以使用redis或者機器內存來緩存數據,使用redis的好處可以保證不同機器讀取數據的一致性,但是讀取redis會增加一次I/O,使用內存緩存數據時可能會出現讀取數據不一致,但是讀取性能好。例如文章的閱讀數數據,如果使用機器內存作為緩存,容易出現不同機器上緩存數據的不一致,用戶不同刷次會請求到不同服務端機器,讀取的閱讀數不一致,可能會出現閱讀數變小的情況,用戶體驗不好。對于閱讀數這種經常變更的數據比較適合使用redis來統一緩存。
也可以將兩者結合提升服務的性能,例如在內容池服務,利用redis跟機器內存緩存熱點文章詳情,優先讀取機器內存中的數據,數據不存在的時候會讀取redis中的緩存數據,當redis中的數據也不存在的時候,會讀取下游持久化存儲中的全量數據。其中內存級緩存過期時間為15s,在數據變更的時候不保證數據一致性,通過數據自然過期來保證最終一致性。redis中緩存數據需要保證與持久化存儲中數據一致性,如何保證一致性在后續講解。可以根據自己的業務場景可以選擇合適的緩存方案。
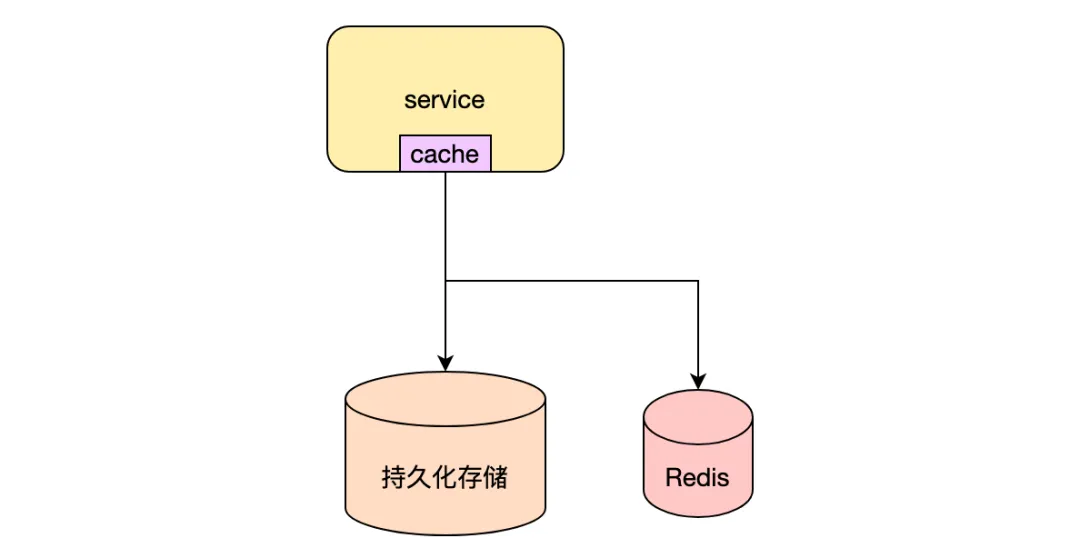
(2) 緩存常見問題
- 緩存雪崩:緩存雪崩是指緩存中的大量數據同時失效或者過期,導致大量的請求直接讀取到下游數據庫,導致數據庫瞬時壓力過大,通常的解決方案是將緩存數據設置的過期時間隨機化。在事件服務中就是利用固定過期時間+隨機值的方式進行文章的淘汰,避免緩存雪崩。
- 緩存穿透:緩存穿透是指讀取下游不存在的數據,導致緩存命中不了,每次都請求下游數據庫。這種情況通常會出現在線上異常流量攻擊或者下游數據被刪除的狀況,針對緩存穿透可以使用布隆過濾器對不存在的數據進行過濾,或者在讀取下游數據不存在的情況,可以在緩存中設置空值,防止不斷的穿透。事件服務可能會出現查詢文章被刪除的情況,就是利用設置空值的方法防止被刪除數據的請求不斷穿透到下游。
- 緩存擊穿: 緩存擊穿是指某個熱點數據在緩存中被刪除或者過期,導致大量的熱點請求同時請求數據庫。解決方案可以對于熱點數據設置較長的過期時間或者利用分布式鎖避免多個相同請求同時訪問下游服務。在新聞業務中,對于熱點新聞經常會出現這種情況,事件服務利用golang的singlefilght保證同一篇文章請求在同一時刻只有一個會請求到下游,防止緩存擊穿。
- 熱點key: 熱點key是指緩存中被頻繁訪問的key,導致緩存該key的分片或者redis訪問量過高。可以將可熱點key分散存儲到多個key上,例如將熱點key+序列號的方式存儲,不同key存儲的值都是相同的,在訪問時隨機訪問一個key,分散原來單key分片的壓力;此外還可以將key緩存到機器內存中,避免redis單節點壓力過大,在新聞業務中,對于熱點文章就是采用這種方式,將熱點文章存儲到機器內存中,避免存儲熱點文章redis單分片請求量過大。
key val => key1 val 、 key2 val、 key3 val 、 key4 val(3) 緩存淘汰
緩存的大小是有限的,因為需要對緩存中數據進行淘汰,通常可以采用隨機、LRU或者LFU算法等淘汰數據。LRU是一種最常用的置換算法,淘汰最近最久未使用的數據,底層可以利用map+雙端隊列的數據結構實現。
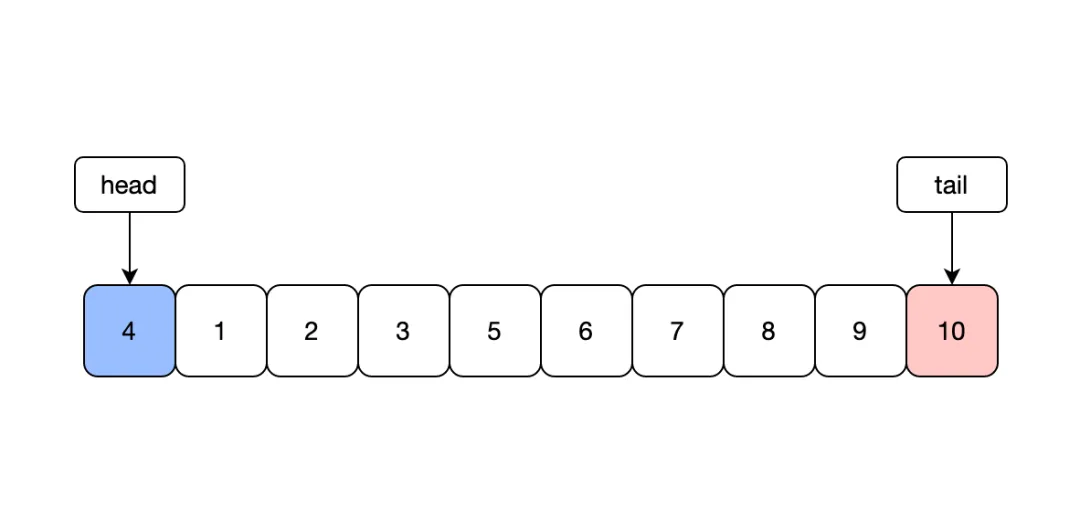
最原生的LRU算法是存在一些問題的,不知道大家在使用過有沒有遇到過問題。首先需要注意的是在數據結構中有互斥鎖,因為golang對于map的讀寫會產生panic,導致服務異常。使用互斥鎖之后會導致整個緩存性能變差,可以采用分片的思想,將整個LRUCache分為多個,每次讀取時讀取其中一個cache片,降低鎖的粒度來提升性能,常見的本地緩存包通常就利用這種方式實現的。
type LRUCache struct {
sync.Mutex
size int
capacity int
cache map[int]*DLinkNode
head, tail *DLinkNode
}
type DLinkNode struct {
key,value int
pre, next *DLinkNode
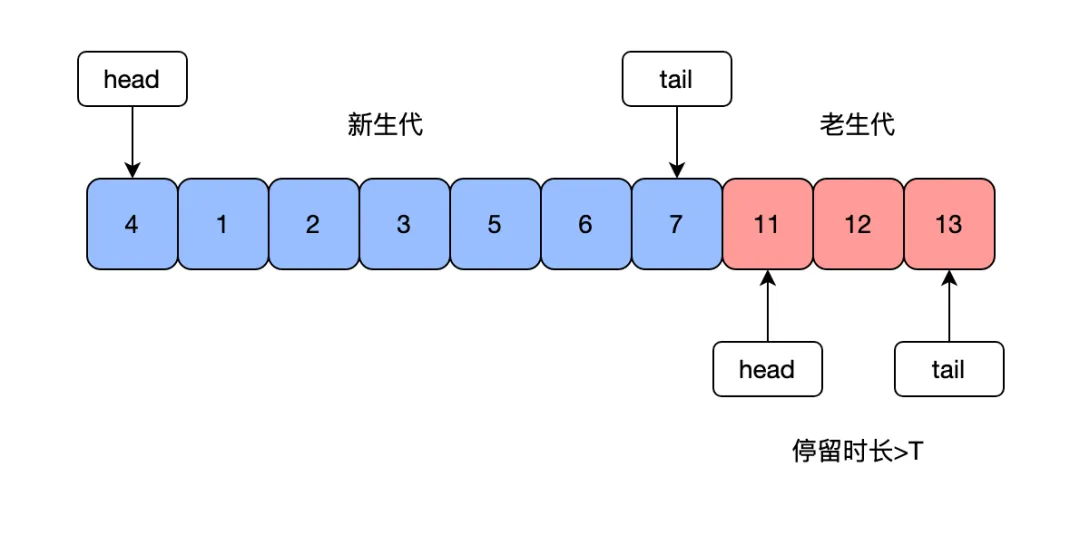
}mysql也會利用LRU算法對buffer pool中的數據頁進行淘汰。由于mysql存在預讀,在讀取磁盤時并不是按需讀取,而是按照整個數據頁的粒度進行讀取,一個數據頁會存儲多條數據,除了讀取當前數據頁,可能也會將接下來可能用到的相鄰數據頁提前緩存到bufferpool中,如果下次讀取的數據在緩存中,直接讀取內存即可,不需要讀取磁盤,但是如果預讀的數據頁一直沒有被訪問,那就會存在預讀失效的情況,淘汰原來使用到的數據頁。mysql將buffer pool中的鏈表分為兩部分,一段是新生代,一段是老生代,新老生代的默認比是7:3,數據頁被預讀的時候會先加到老生代中,當數據頁被訪問時才會加載到新生代中,這樣就可以防止預讀的數據頁沒有被使用反而淘汰熱點數據頁。此外mysql通常會存在掃描表的請求,會順序請求大量的數據加載到緩存中,然后將原本緩存中所有熱點數據頁淘汰,這個問題通常被稱為緩沖池污染,mysql中的數據頁需要在老生代停留時間超過配置時間才會老生代移動到新生代時來解決緩存池污染。
redis中也會利用LRU進行淘汰過期的數據,如果redis將緩存數據都通過一個大的鏈表進行管理,在每次讀寫時將最新訪問的數據移動到鏈表隊頭,那樣會嚴重影響redis的讀寫性能,此外會增加額外的存儲空間,降低整體存儲數量。redis是對緩存中的對象增加一個最后訪問時間的字段,在對對象進行淘汰的時候,會采用隨機采樣的方案,隨機取5個值,淘汰最近訪問時間最久的一個,這樣就可以避免每次都移動節點。但是LRU也會存在緩存污染的情況,一次讀取大量數據會淘汰熱點數據,因此redis可以選擇利用LFU進行淘汰數據,是將原來的訪問時間字段變更為最近訪問時間+訪問次數的一個字段,這里需要注意的是訪問次數并不是單純的次數累加,而是根據最近訪問時間跟當前時間的差值進行時間衰減的,簡單說也就是訪問越久以及訪問次數越少計算得到的值也越小,越容易被淘汰。
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} obj ;可以看出不同中間件對于傳統的LRU淘汰策略都進行了一定優化來保證服務性能,我們也可以參考不同的優化策略在自己的服務中進行緩存key的淘汰。
(4) 緩存數據一致性
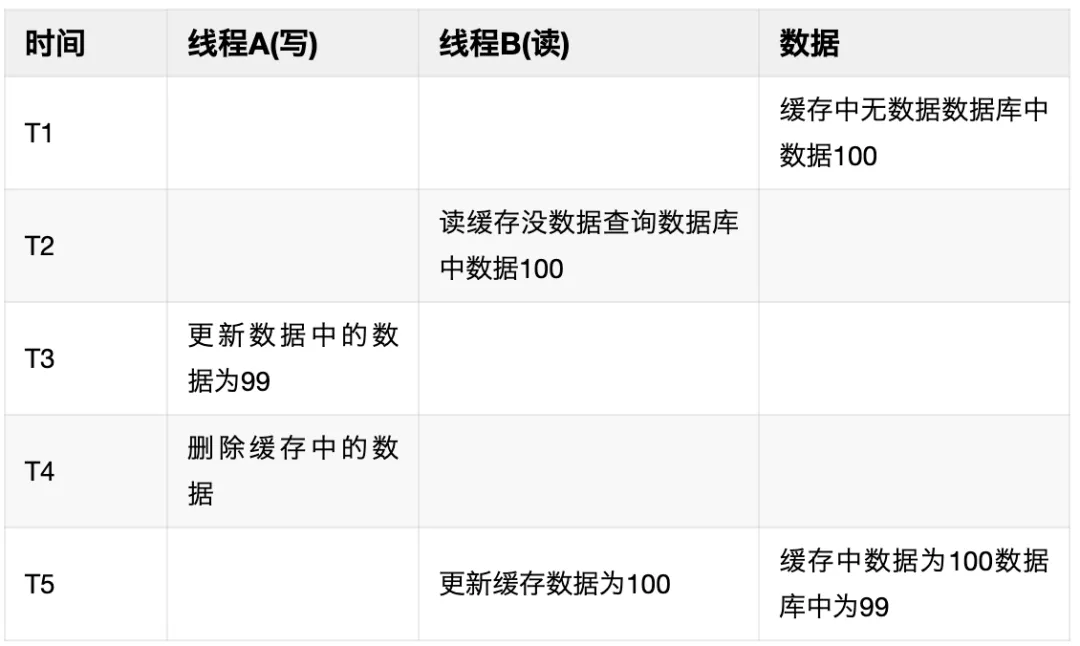
當數據庫中的數據變更時,如何保證緩存跟數據庫中的數據一致,通常有以下幾種方案:更新緩存再更新DB,更新DB再更新緩存,先更新DB再刪除緩存,刪除緩存再更新DB。這幾種方案都有可能會出現緩存跟數據庫中的數據不一致的情況,最常用的還是更新DB再刪除緩存,因為這種方案導致數據不一致的概率最小,但是也依然會存在數據不一致的問題。例如在T1時緩存中無數據,數據庫中數據為100,線程B查詢緩存沒有查詢到數據,讀取到數據庫的數據100然后去更新緩存,但是此時線程A將數據庫中的數據更新為99,然后在T4時刻刪除緩存中的數據,但是此時緩存中還沒有數據,在T5的時候線程B才更新緩存數據為100,這時候就會導致緩存跟數據庫中的數據不一致。
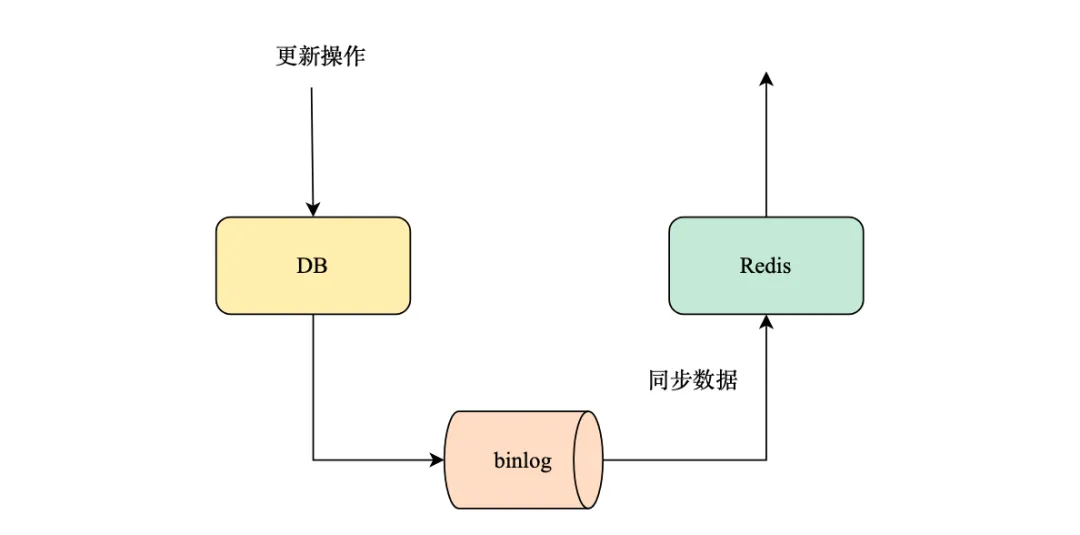
為保證緩存與數據庫數據的一致性。常用的解決方案有兩種,一種是延時雙刪,先刪除緩存,后續更新數據庫,休眠一會再刪除緩存。文章池服務中就是利用這種方案保證數據一致性,如何實現延遲刪除,是通過go語言中channel實現簡單延時隊列,沒有引入第三方的消息隊列,主要為了防止服務的復雜化;另外一種可以訂閱DB的變更binlog,數據更新時只更新DB,通過消費DB的binlog日志,解析變更操作進行緩存變更,更新失敗時不進行消息的提交,通過消息隊列的重試機制實現最終一致性。
2.并行化處理
redis在版本6.0之前都是號稱單線程模型,主要是利用epllo管理用戶海量連接,使用一個線程通過事件循環來處理用戶的請求,優點是避免了線程切換和鎖的競爭,以及實現簡單,但是缺點也比較明顯,不能有效的利用cpu的多核資源。隨著數據量和并發量的越來越大,I/O成了redis的性能瓶頸點,因此在6.0版本引入了多線程模型。redis的多線程將處理過程最耗時的sockect的讀取跟解析寫入由多個I/O 并發完成,對于命令的執行過程仍然由單線程完成。
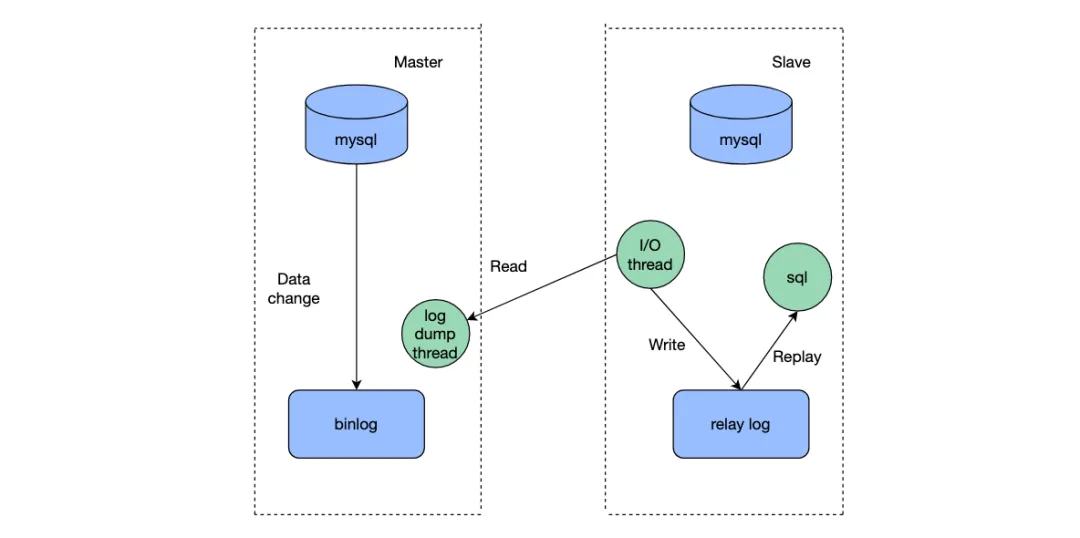
mysql的主從同步過程從數據庫通過I/Othread讀取住主庫的binlog,將日志寫入到relay log中,然后由sqlthread執行relaylog進行數據的同步。其中sqlthread就是由多個線程并發執行加快數據的同步,防止主從同步延遲。sqlthread多線程化也經歷了多個版本迭代,按表維度分發到同一個線程進行數據同步,再到按行維度分發到同一個線程。
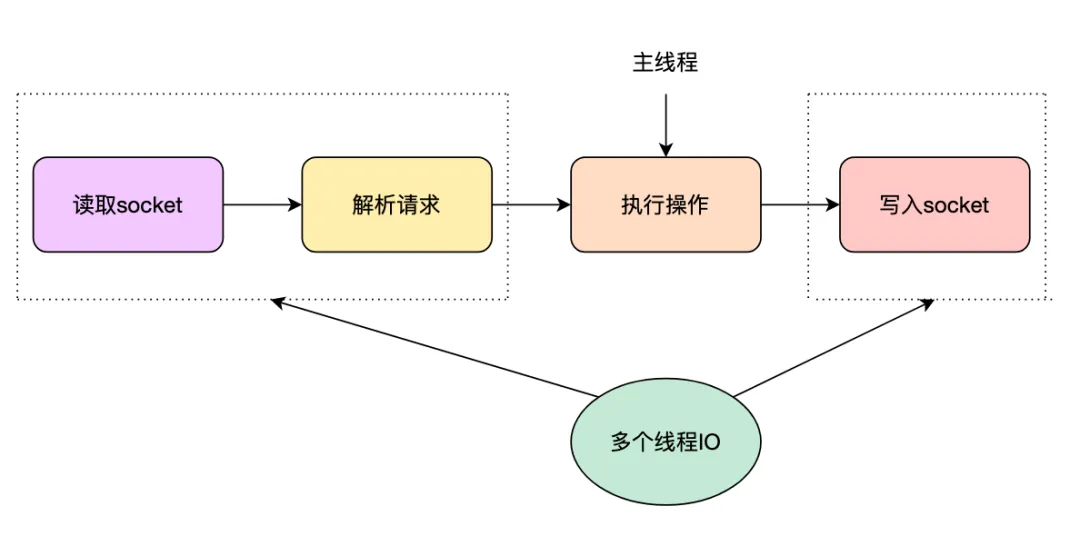
小到線程的并發處理,大到redis的集群,以及kafka的分topic分區都是通過多個client并行處理提高服務的讀寫性能。在我們的服務設計中可以通過創建多個容器對外服務提高服務的吞吐量,服務內部可以將多個串行的I/O操作改為并行處理,縮短接口的響應時長,提升用戶體驗。對于I/O存在相互依賴的情況,可以進行多階段分批并行化處理,另外一種常見的方案就是利用DAG加速執行,但是需要注意的是DAG會存在開發維護成本較高的情況,需要根據自己的業務場景選擇合適的方案。并行化也不是只有好處沒有壞處的,并行化有可能會導致讀擴散嚴重,以及線程切換頻繁存在一定的性能影響。
3.批量化處理
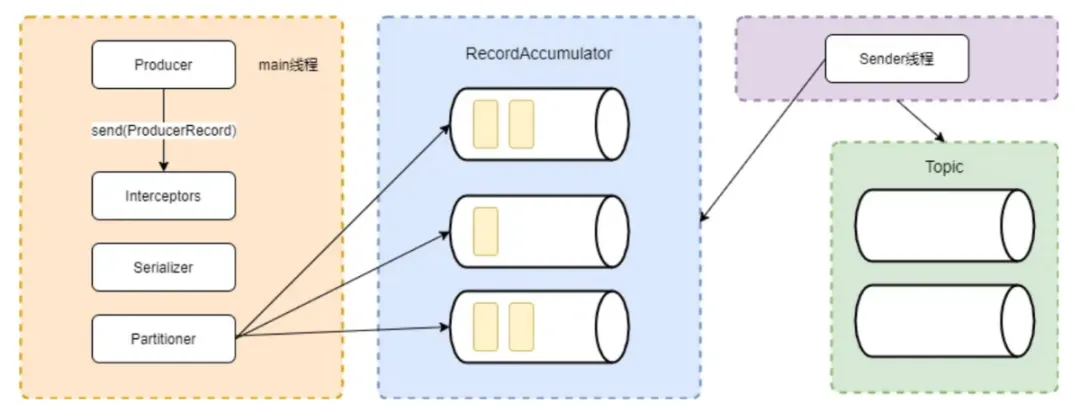
kafka的消息發送并不是直接寫入到broker中的,發送過程是將發送到同一個topic同一個分區的消息通過main函數的partitioner組件發送到同一個隊列中,由sender線程不斷拉取隊列中消息批量發送到broker中。利用批量發送消息處理,節省大量的網絡開銷,提高發送效率。
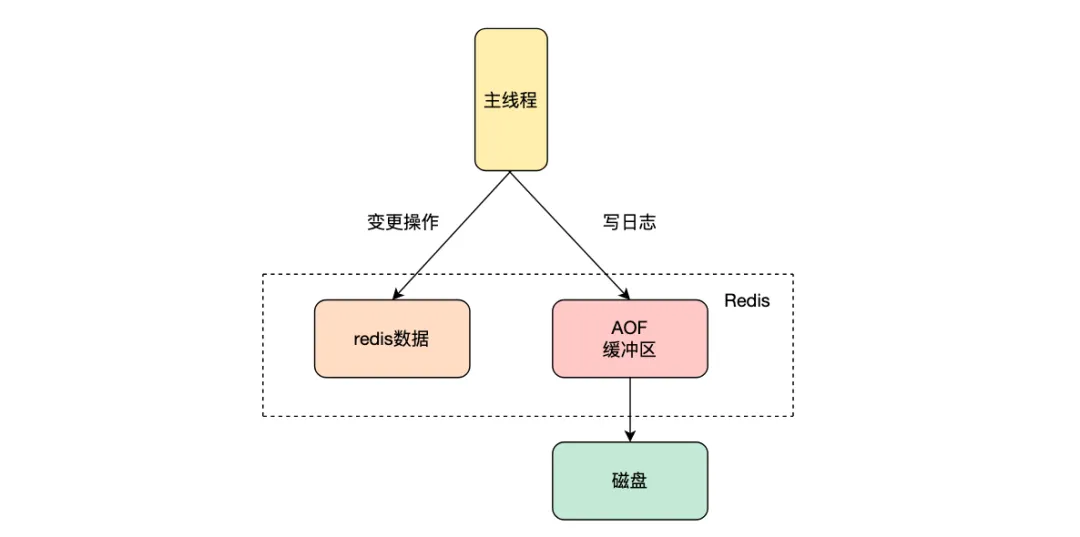
redis的持久化方式有RDB跟AOF兩種,其中AOF在執行命令寫入內存后,會寫入到AOF緩沖區,可以選擇合適的時機將AOF緩沖區中的數據寫入到磁盤中,刷新到磁盤的時間通過參數appendfsync控制,有三個值always、everysec、no。其中always會在每次命令執行完都會刷新到磁盤來保證數據的可靠性;everysec是每秒批量寫入到磁盤,no是不進行同步操作,由操作系統決定刷新到寫回磁盤,當redis異常退出時存在丟數據的風險。AOF命令刷新到磁盤的時機會影響redis服務寫入性能,通常配置為everysec批量寫入到磁盤,來平衡寫入性能和數據可靠性。
我們讀取下游服務或者數據庫的時候,可以一次多查詢幾條數據,節省網絡I/O;讀取redis的還可以利用pipeline或者lua腳本處理多條命令,提升讀寫性能;前端請求js文件或者小圖片時,可以將多個js文件或者圖片合并到一起返回,減少前端的連接數,提升傳輸性能。同樣需要注意的是批量處理多條數據,有可能會降低吞吐量,以及本身下游就不支持過多的批量數據,此時可以將多條數據分批并發請求。對于事件底層頁服務中不同組件下配置的不同文章id,會統一批量請求下游內容服務獲取文章詳情,對于批量的條數也會做限制,防止單批數據量過大。
4.數據壓縮合并
redis的AOF重寫是利用bgrewriteaof命令進行AOF文件重寫,因為AOF是追加寫日志,對于同一個key可能存在多條修改修改命令,導致AOF文件過大,redis重啟后加載AOF文件會變得緩慢,導致啟動時間過長。可以利用重寫命令將對于同一個key的修改只保存一條記錄,減小AOF文件體積。

大數據領域的Hbase、cassandra等nosql數據庫寫入性能都很高,它們的底層存儲數據結構就是LSM樹(log structured merge tree),這種數據結構的核心思想是追加寫,積攢一定的數據后合并成更大的segement,對于數據的刪除也只是增加一條刪除記錄。同樣對一個key的修改記錄也有多條。這種存儲結構的優點是寫入性能高,但是缺點也比較明顯,數據存在冗余和文件體積大。主要通過線程進行段合并將多個小文件合并成更大的文件來減少存儲文件體積,提升查詢效率。
對于kafka進行傳輸數據時,在生產者端和消費者端可以開啟數據壓縮。生產者端壓縮數據后,消費者端收到消息會自動解壓,可以有效減小在磁盤的存儲空間和網絡傳輸時的帶寬消耗,從而降低成本和提升傳輸效率。需要注意生產者端和消費者端指定相同的壓縮算法。
在降本增效的浪潮中,降低redis成本的一種方式,就是對存儲到redis中的數據進行壓縮,降低存儲成本,重構后的內容微服務通過持久化存儲全量數據,采用snappy壓縮,壓縮后只是原來數據的40%-50%;還有一種方式是將服務之間的調用從http的json改為trpc的pb協議,因為pb協議編碼后的數據更小,提升傳輸效率,在服務優化時,將原來請求tab的協議從json轉成pb,降低幾毫秒的時延,此外內容微服務存儲的數據采用flutbuffer編碼,相比較于protobuffer有著更高的壓縮比跟更快的編解碼速度;對于JS/CSS多個文件下發也可以進行混淆和壓縮傳遞;對于存儲在es中的數據也可以手動調用api進行段合并,減小存儲數據的體積,提高查詢速度;在我們工作中還有一個比較常見的問題是接口返回的冗余數據特別多,一個接口服務下發的數據大而全,而不是對于當前場景做定制化下發,不滿足接口最小化原則,白白浪費了很多帶寬資源和降低傳輸效率。
5.無鎖化
redis通過單線程避免了鎖的競爭,避免了線程之間頻繁切換才有這很好的讀寫性能。
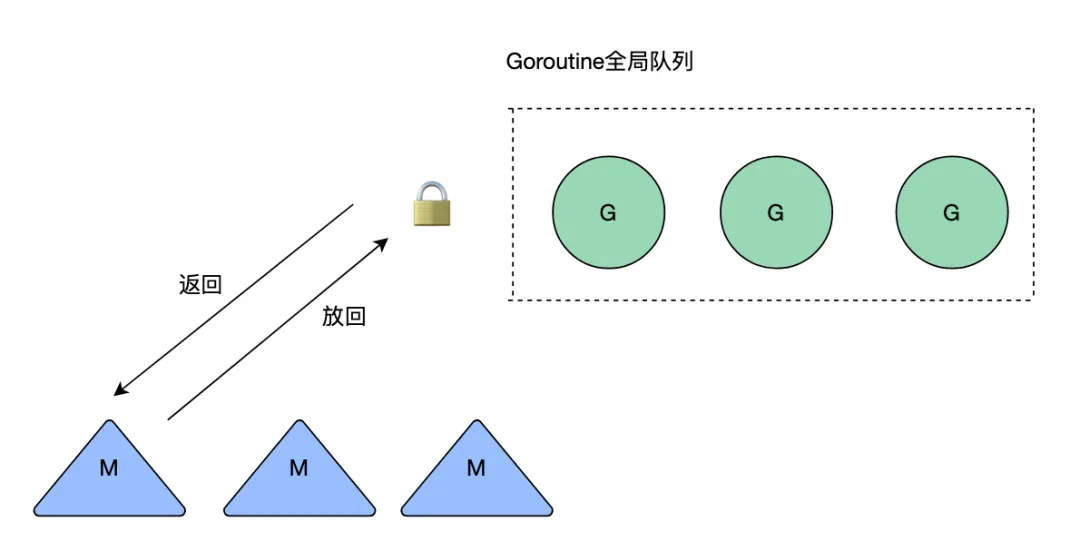
go語言中提供了atomic包,主要用于不同線程之間的數據同步,不需要加鎖,本質上就是封裝了底層cpu提供的原子操作指令。此外go語言最開始的調度模型時GM模型,所有的內核級線程想要執行goroutine需要加鎖從全局隊列中獲取,所以不同線程之間的競爭很激烈,調度效率很差。
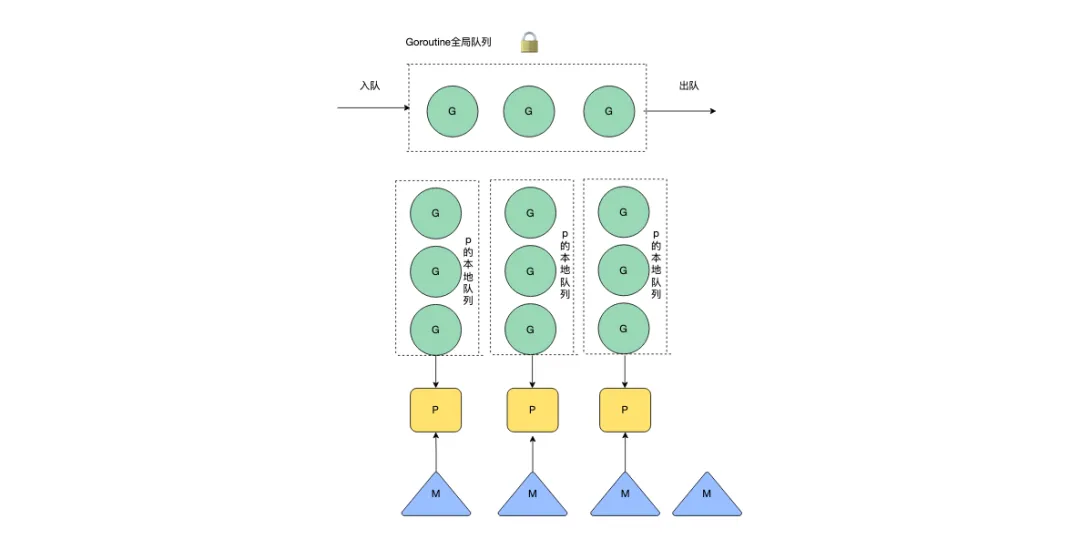
后續引入了P(Processor),每一個M(thread)要執行G(gorontine)的時候需要綁定一個P,其中P中會有一個待執行G的本地隊列,只由當前M可以進行讀寫(少數情況會存在偷其他協程的G),讀取P本地隊列時不需要進行加鎖,通過降低鎖的競爭大幅度提升調度G的效率。
mysql利用mvcc實現多個事務進行讀寫并發時保證數據的一致性和隔離型,也是解決讀寫并發的一種無鎖化設計方案之一。它主要通過對每一行數據的變更記錄維護多個版本鏈來實現的,通過隱藏列rollptr和undolog來實現快照讀。在事務對某一行數據進行操作時,會根據當前事務id以及事務隔離級別判斷讀取那個版本的數據,對于可重復讀就是在事務開始的時候生成readview,在后續整個事務期間都使用這個readview。mysql中除了使用mvcc避免互斥鎖外,bufferpool還可以設置多個,通過多個bufferpool降低鎖的粒度,提升讀寫性能,也是一種優化方案。
日常工作 在讀多寫少的場景下可以利用atomic.value存儲數據,減少鎖的競爭,提升系統性能,例如配置服務中數據就是利用atomic.value存儲的;syncmap為了提升讀性能,優先使用atomic進行read操作,然后再進行加互斥鎖操作進行dirty的操作,在讀多寫少的情況下也可以使用syncmap。
秒殺系統的本質就是在高并發下準確的增減商品庫存,不出現超賣少賣的問題。因此所有的用戶在搶到商品時需要利用互斥鎖進行庫存數量的變更。互斥鎖的存在必然會成為系統瓶頸,但是秒殺系統又是一個高并發的場景,所以如何進行互斥鎖優化是提高秒殺系統性能的一個重要優化手段。

無鎖化設計方案之一就是利用消息隊列,對于秒殺系統的秒殺操作進行異步處理,將秒殺操作發布一個消息到消息隊列中,這樣所有用戶的秒殺行為就形成了一個先進先出的隊列,只有前面先添加到消息隊列中的用戶才能搶購商品成功。從隊列中消費消息進行庫存變更的線程是個單線程,因此對于db的操作不會存在沖突,不需要加鎖操作。
另外一種優化方式可以參考golang的GMP模型,將庫存分成多份,分別加載到服務server的本地,這樣多機之間在對庫存變更的時候就避免了鎖的競爭。如果本地server是單進程的,因此也可以形成一種無鎖化架構;如果是多進程的,需要對本地庫存加鎖后在進行變更,但是將庫存分散到server本地,降低了鎖的粒度,提高整個服務性能。
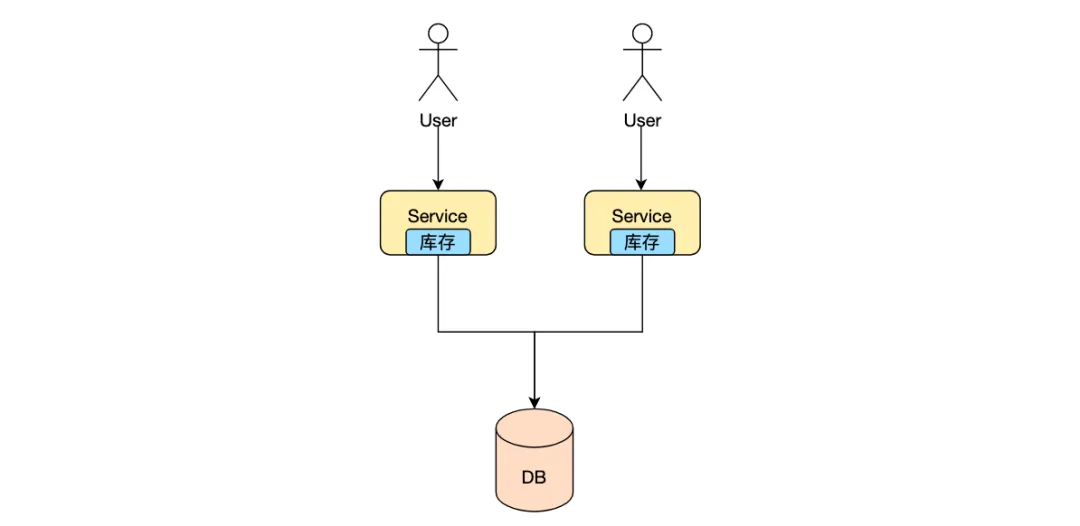
6.順序寫
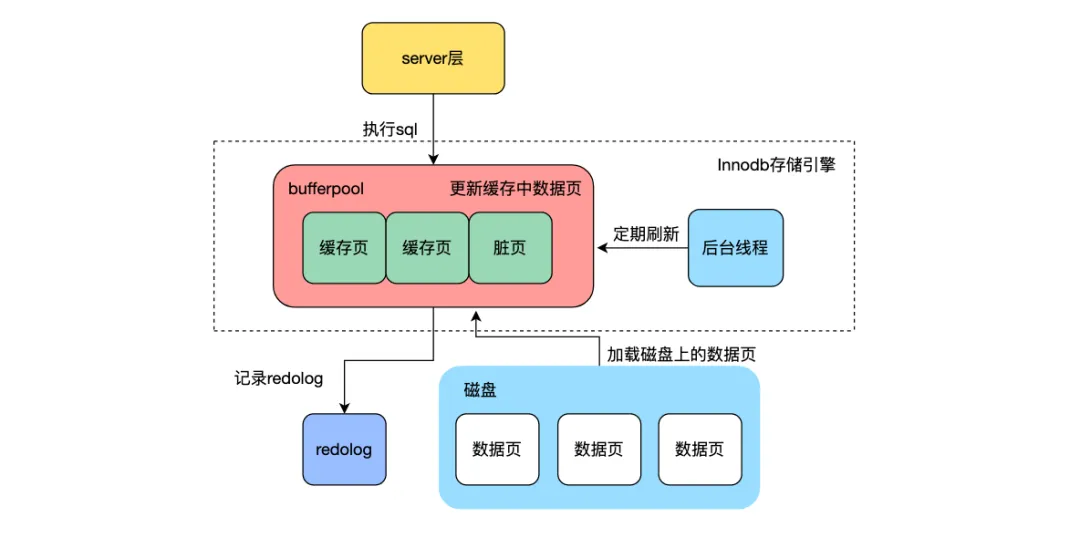
mysql的InnoDB存儲引擎在創建主鍵時通常會建議使用自增主鍵,而不是使用uuid,最主要的原因是InnoDB底層采用B+樹用來存儲數據,每個葉子結點是一個數據頁,存儲多條數據記錄,頁面內的數據通過鏈表有序存儲,數據頁間通過雙向鏈表存儲。由于uuid是無序的,有可能會插入到已經空間不足的數據頁中間,導致數據頁分裂成兩個新的數據頁以便插入新數據,影響整體寫入性能。
此外mysql中的寫入過程并不是每次將修改的數據直接寫入到磁盤中,而是修改內存中buffer pool內存儲的數據頁,將數據頁的變更記錄到undolog和binlog日志中,保證數據變更不丟失,每次記錄log都是追加寫到日志文件尾部,順序寫入到磁盤。對數據進行變更時通過順序寫log,避免隨機寫磁盤數據頁,提升寫入性能,這種將隨機寫轉變為順序寫的思想在很多中間件中都有所體現。
kakfa中的每個分區是一個有序不可變的消息隊列,新的消息會不斷的添加的partition的尾部,每個partition由多個segment組成,一個segment對應一個物理日志文件,kafka對segment日志文件的寫入也是順序寫。順序寫入的好處是避免了磁盤的不斷尋道和旋轉次數,極大的提高了寫入性能。
順序寫主要會應用在存在大量磁盤I/O操作的場景,日常工作中創建mysql表時選擇自增主鍵,或者在進行數據庫數據同步時順序讀寫數據,避免底層頁存儲引擎的數據頁分裂,也會對寫入性能有一定的提升。
7.分片化
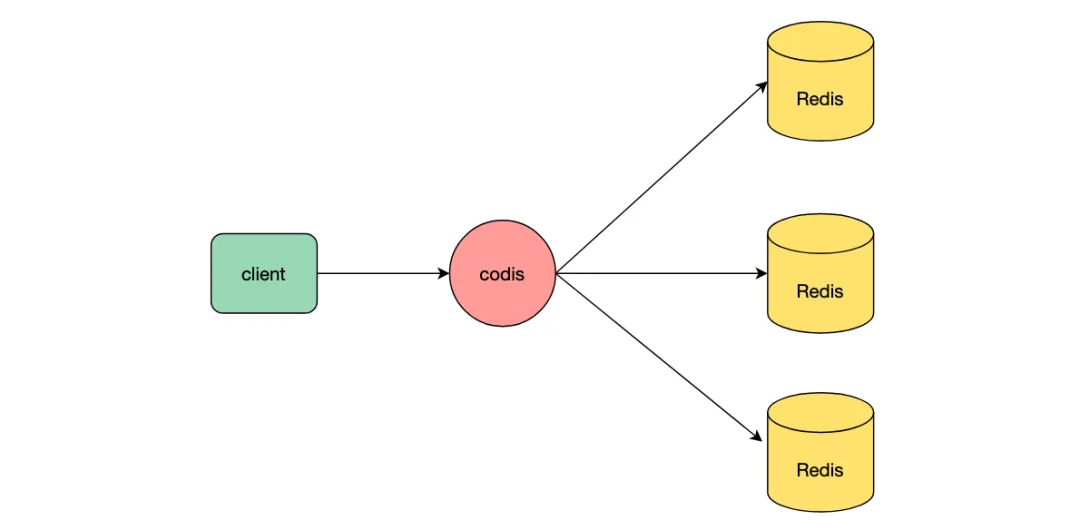
redis對于命令的執行過程是單線程的,單機有著很好的讀寫性能,但是單機的機器容量跟連接數畢竟有限,因此單機redis必然會存在讀寫上限跟存儲上限。redis集群的出現就是為了解決單機redis的讀寫性能瓶頸問題,redis集群是將數據自動分片到多個節點上,每個節點負責數據的一部分,每個節點都可以對外提供服務,突破單機redis存儲限制跟讀寫上限,提高整個服務的高并發能力。除了官方推出的集群模式,代理模式codis等也是將數據分片到不同節點,codis將多個完全獨立的redis節點組成集群,通過codis轉發請求到某一節點,來提高服務存儲能力和讀寫性能。
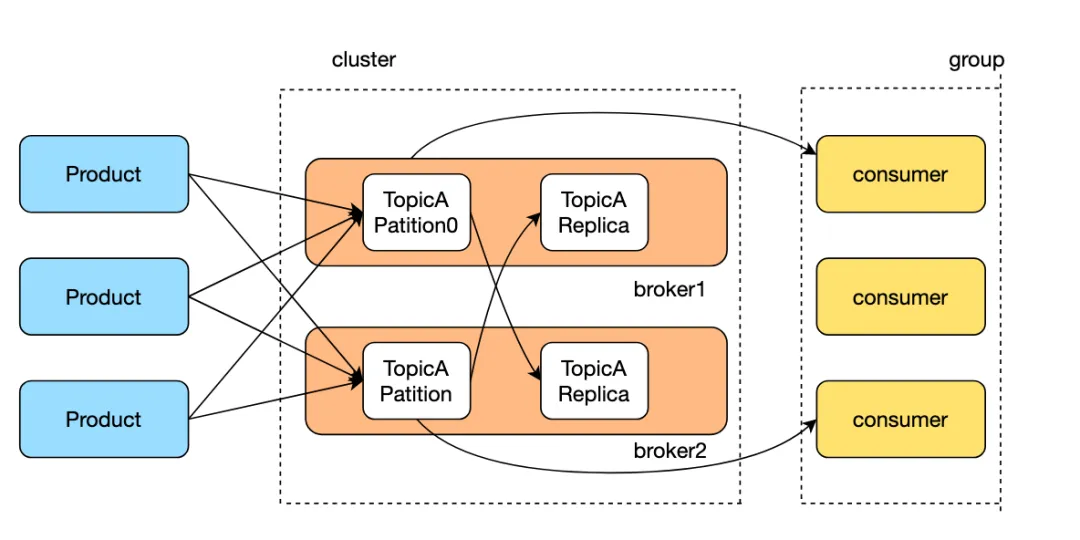
同樣的kafka中每個topic也支持多個partition,partition分布到多個broker上,減輕單臺機器的讀寫壓力,通過增加partition數量可以增加消費者并行消費消息,提高kafka的水平擴展能力和吞吐量。
新聞每日會生產大量的圖文跟視頻數據,底層是通過tdsql存儲,可以分采分片化的存儲思想,將圖文跟視頻或者其他介質存儲到不同的數據庫或者數據表中,同一種介質每日的生產量也會很大,這時候就可以對同一種介質拆分成多個數據表,進一步提高數據庫的存儲量跟吞吐量。另外一種角度去優化存儲還可以將冷熱數據分離,最新的數據采用性能好的機器存儲,之前老數據訪問量低,采用性能差的機器存儲,節省成本。
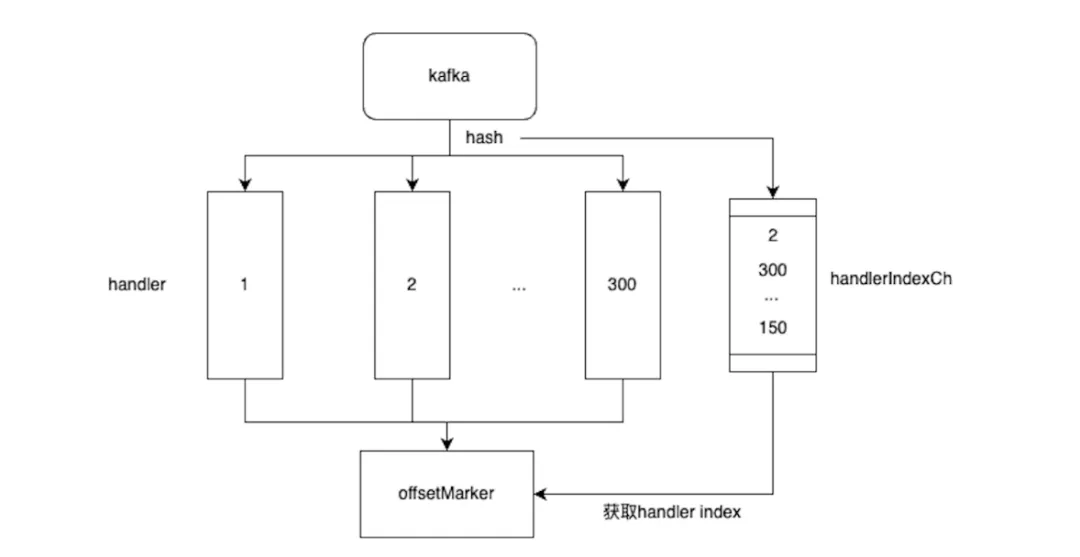
在微服務重構過程中,需要進行數據同步,將總庫中存儲的全量數據通過kafka同步到內容微服務新的存儲中,預期同步qps高達15k。由于kafka的每個partition只能通過一個消費者消費,要達到預期qps,因此需要創建750+partition才能夠實現,但是kafka的partition過多會導致rebalance很慢,影響服務性能,成本和可維護行都不高。采用分片化的思想,可以將同一個partition中的數據,通過一個消費者在內存中分片到多個channel上,不同的channel對應的獨立協程進行消費,多協程并發處理消息提高消費速度,消費成功后寫入到對應的成功channel,由統一的offsetMaker線程消費成功消息進行offset提交,保證消息消費的可靠性。
避免請求
為提升寫入性能,mysql在寫入數據的時候,對于在bufferpool中的數據頁,直接修改bufferpool的數據頁并寫redolog;對于不在內存中的數據頁并不會立刻將磁盤中的數據頁加載到bufferpool中,而是僅僅將變更記錄在緩沖區,等后續讀取磁盤上的數據頁到bufferpool中時會進行數據合并,需要注意的是對于非唯一索引才會采用這種方式,對于唯一索引寫入的時候需要每次都將磁盤上的數據讀取到bufferpool才能判斷該數據是否已存在,對于已存在的數據會返回插入失敗。
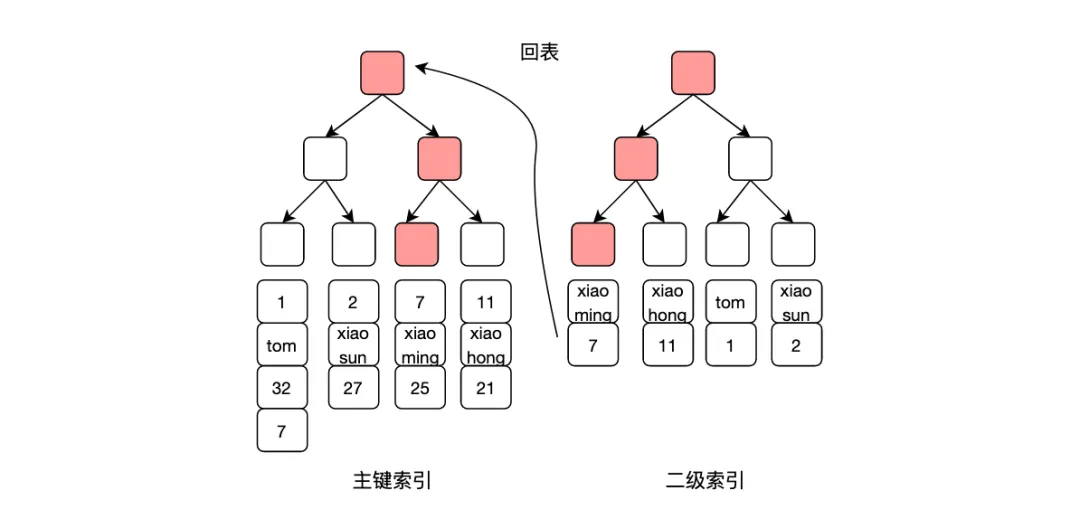
另外mysql查詢例如select * from table where name = 'xiaoming' 的查詢,如果name字段存在二級索引,由于這個查詢是*,表示需要所在行的所有字段,需要進行回表操作,如果僅需要id和name字段,可以將查詢語句改為select id , name from tabler where name = 'xiaoming' ,這樣只需要在name這個二級索引上就可以查到所需數據,避免回表操作,減少一次I/O,提升查詢速度。
web應用中可以使用緩存、合并css和js文件等,避免或者減少http請求,提升頁面加載速度跟用戶體驗。
在日常移動端開發應用中,對于多tab的數據,可以采用懶加載的方式,只有用戶切換到新的tab之后才會發起請求,避免很多無用請求。服務端開發隨著版本的迭代,有些功能字段端上已經不展示,但是服務端依然會返回數據字段,對于這些不需要的數據字段可以從數據源獲取上就做下線處理,避免無用請求。另外在數據獲取時可以對請求參數的合法性做準確的校驗,例如請求投票信息時,運營配置的投票ID可能是“” 或者“0”這種不合法參數,如果對請求參數不進行校驗,可能會存在很多無用I/O請求。另外在函數入口處通常會請求用戶的所有實驗參數,只有在實驗期間才會用到實驗參數,在實驗下線后并沒有下線ab實驗平臺的請求,可以在非實驗期間下線這部分請求,提升接口響應速度。
8.池化
golang作為現代原生支持高并發的語言,池化技術在它的GMP模型就存在很大的應用。對于goroutine的銷毀就不是用完直接銷毀,而是放到P的本地空閑隊列中,當下次需要創建G的時候會從空閑隊列中直接取一個G復用即可;同樣的對于M的創建跟銷毀也是優先從全局隊列中獲取或者釋放。此外golang中sync.pool可以用來保存被重復使用的對象,避免反復創建和銷毀對象帶來的消耗以及減輕gc壓力。
mysql等數據庫也都提供連接池,可以預先創建一定數量的連接用于處理數據庫請求。當請求到來時,可以從連接池中選擇空閑連接來處理請求,請求結束后將連接歸還到連接池中,避免連接創建和銷毀帶來的開銷,提升數據庫性能。
在日常工作中可以創建線程池用來處理請求,在請求到來時同樣的從鏈接池中選擇空閑的線程來處理請求,處理結束后歸還到線程池中,避免線程創建帶來的消耗,在web框架等需要高并發的場景下非常常見。
9.異步處理
異步處理在數據庫中同樣應用廣泛,例如redis的bgsave,bgrewriteof就是分別用來異步保存RDB跟AOF文件的命令,bgsave執行后會立刻返回成功,主線程fork出一個線程用來將內存中數據生成快照保存到磁盤,而主線程繼續執行客戶端命令;redis刪除key的方式有del跟unlink兩種,對于del命令是同步刪除,直接釋放內存,當遇到大key時,刪除操作會讓redis出現卡頓的問題,而unlink是異步刪除的方式,執行后對于key只做不可達的標識,對于內存的回收由異步線程回收,不阻塞主線程。
mysql的主從同步支持異步復制、同步復制跟半同步復制。異步復制是指主庫執行完提交的事務后立刻將結果返回給客戶端,并不關心從庫是否已經同步了數據;同步復制是指主庫執行完提交的事務,所有的從庫都執行了該事務才將結果返回給客戶端;半同步復制指主庫執行完后,至少一個從庫接收并執行了事務才返回給客戶端。有多種主要是因為異步復制客戶端寫入性能高,但是存在丟數據的風險,在數據一致性要求不高的場景下可以采用,同步方式寫入性能差,適合在數據一致性要求高的場景使用。 此外對于kafka的生產者跟消費者都可以采用異步的方式進行發送跟消費消息,但是采用異步的方式有可能會導致出現丟消息的問題。對于異步發送消息可以采用帶有回調函數的方式,當發送失敗后通過回調函數進行感知,后續進行消息補償。
在做服務性能優化中,發現之前的一些監控上報,曝光上報等操作都在主流程中,可以將這部分功能做異步處理,降低接口的時延。此外用戶發布新聞后,會將新聞寫入到個人頁索引,對圖片進行加工處理,標題進行審核,或者給用戶增加活動積分等操作,都可以采用異步處理,這里的異步處理是將發送消息這個動作發送消息到消息隊列中,不同的場景消費消息隊列中的消息進行各自邏輯的處理,這種設計保證了寫入性能,也解耦不同場景業務邏輯,提高系統可維護性。
總結
本文主要總結進行服務性能優化的幾種方式,每一種方式在我們常用的中間件中都有所體現,我想這也是我們常說多學習這些中間件的意義,學習它們不僅僅是學會如何去使用它們,也是學習它們底層優秀的設計思想,理解為什么要這樣設計,這種設計有什么好處,后續我們在架構選型或者做服務性能優化時都會有一定的幫助。此外性能優化方式也給出了具體的落地實踐,
希望通過實際的應用例子加強對這種優化方式的理解。此外要做服務性能優化,還是要從自身服務架構出發,分析服務調用鏈耗時分布跟cpu消耗,優化有問題的rpc調用和函數。