













明確了:文本數(shù)據(jù)中加點(diǎn)代碼,訓(xùn)練出的大模型更強(qiáng)、更通用
如今說起大語言模型(LLM),寫代碼能力恐怕是「君子六藝」必不可少的一項(xiàng)。
在預(yù)訓(xùn)練數(shù)據(jù)集中包含代碼,即使對于并非專門為代碼設(shè)計(jì)的大模型來說,也已是必不可少的事。雖然從業(yè)者們普遍認(rèn)為代碼數(shù)據(jù)在通用 LLM 的性能中起著至關(guān)重要的作用,但分析代碼對非代碼任務(wù)的精確影響的工作卻非常有限。
在最近由 Cohere 等機(jī)構(gòu)提交的一項(xiàng)工作中,研究者系統(tǒng)地研究了代碼數(shù)據(jù)對通用大模型性能的影響。

論文鏈接:https://arxiv.org/abs/2408.10914
設(shè)問「預(yù)訓(xùn)練中使用的代碼數(shù)據(jù)對代碼生成以外的各種下游任務(wù)有何影響」。作者對范圍廣泛的自然語言推理任務(wù)、世界知識(shí)任務(wù)、代碼基準(zhǔn)和 LLM-as-a-judge 勝率進(jìn)行了廣泛的消融和評估,模型的參數(shù)大小從 4.7 億到 2.8 億個(gè)參數(shù)不等。
在各種配置中,我們可以看到存在一致的結(jié)果:代碼是泛化的關(guān)鍵模塊,遠(yuǎn)遠(yuǎn)超出了編碼任務(wù)的范圍,并且代碼質(zhì)量的改進(jìn)對所有任務(wù)都有巨大影響。預(yù)訓(xùn)練期間投資代碼質(zhì)量和保留代碼數(shù)據(jù),可以產(chǎn)生積極影響。
這里有幾個(gè)因素很重要,包括確保代碼比例正確、通過包含合成代碼和代碼相鄰數(shù)據(jù)(例如 commits)來提高代碼質(zhì)量,以及在冷卻期間等多個(gè)訓(xùn)練階段利用代碼。該研究結(jié)果表明,代碼是泛化的關(guān)鍵構(gòu)建塊,遠(yuǎn)遠(yuǎn)超出了編碼任務(wù)的范圍,代碼質(zhì)量的提高對性能有巨大的影響。
再進(jìn)一步,作者對廣泛的基準(zhǔn)進(jìn)行了廣泛的評估,涵蓋世界知識(shí)任務(wù)、自然語言推理和代碼生成,以及 LLM 作為評判者的勝率。在對 4.7 億到 28 億參數(shù)模型進(jìn)行實(shí)驗(yàn)后,以下是詳細(xì)結(jié)果:
1. 代碼為非代碼任務(wù)的性能提供了重大改進(jìn)。使用代碼預(yù)訓(xùn)練模型進(jìn)行初始化可提高自然語言任務(wù)的性能。特別是,與純文本預(yù)訓(xùn)練相比,添加代碼可使自然語言推理能力相對增加 8.2%,世界知識(shí)增加 4.2%,生成勝率提高 6.6%,代碼性能提高 12 倍。
2. 代碼質(zhì)量和屬性很重要。使用標(biāo)記樣式的編程語言、代碼相鄰數(shù)據(jù)集(例如 GitHub commits)和合成生成的代碼可提高預(yù)訓(xùn)練的性能。特別是,與預(yù)訓(xùn)練中的基于 Web 的代碼數(shù)據(jù)相比,在更高質(zhì)量的合成生成的代碼數(shù)據(jù)集上進(jìn)行訓(xùn)練可使自然語言推理和代碼性能分別提高 9% 和 44%。此外,與不包含代碼數(shù)據(jù)的代碼模型初始化相比,包含合成數(shù)據(jù)的代碼模型持續(xù)預(yù)訓(xùn)練分別使自然語言推理和代碼性能相對提高 1.9% 和 41%。
3. 冷卻中的代碼可進(jìn)一步改善所有任務(wù)。在預(yù)訓(xùn)練冷卻中包含代碼數(shù)據(jù),其中高質(zhì)量數(shù)據(jù)集被加權(quán),與冷卻前的模型相比,自然語言推理性能增加 3.6%,世界知識(shí)增加 10.1%,代碼性能增加 20%。更重要的是,包含代碼的冷卻比基線(無冷卻的模型)的勝率高出 52.3%,其中勝率比無代碼的冷卻高出 4.1%。
方法概覽
在方法部分,研究者從預(yù)訓(xùn)練數(shù)據(jù)、評估、訓(xùn)練與模型細(xì)節(jié)三個(gè)部分著手進(jìn)行介紹。下圖 1 為高級實(shí)驗(yàn)框架。

預(yù)訓(xùn)練數(shù)據(jù)
研究者描述了預(yù)訓(xùn)練和冷卻(cooldown)數(shù)據(jù)集的細(xì)節(jié)。目標(biāo)是在當(dāng)前 SOTA 實(shí)踐的標(biāo)準(zhǔn)下,評估代碼在預(yù)訓(xùn)練中的作用。因此,他們考慮了由以下兩個(gè)階段組成的預(yù)訓(xùn)練運(yùn)行,即持續(xù)預(yù)訓(xùn)練和冷卻。
其中持續(xù)預(yù)訓(xùn)練是指訓(xùn)練一個(gè)從預(yù)訓(xùn)練模型初始化而來并在固定 token 預(yù)算下訓(xùn)練的模型。冷卻是指在訓(xùn)練的最后階段,提高高質(zhì)量數(shù)據(jù)集的權(quán)重并對相對較少數(shù)量的 token 進(jìn)行學(xué)習(xí)率的退火。
關(guān)于文本數(shù)據(jù)集,研究者使用 SlimPajama 預(yù)訓(xùn)練語料庫作為他們的自然語言文本數(shù)據(jù)源。
關(guān)于代碼數(shù)據(jù)集,為了探索不同屬性的代碼數(shù)據(jù)的影響,研究者使用了不同類型的代碼源,包括如下:
基于 web 的代碼數(shù)據(jù),這是主要的代碼數(shù)據(jù)源,包括用于訓(xùn)練 StarCoder 的 Stack 數(shù)據(jù)集。該數(shù)據(jù)集包含了爬取自 GitHub 的自由授權(quán)的代碼數(shù)據(jù)。研究者使用了質(zhì)量過濾器,并選定了基于文檔數(shù)(document count)的前 25 種編程語言。在走完所有過濾步驟后,僅代碼和 markup 子集的規(guī)模為 139B tokens。
Markdown 數(shù)據(jù)。研究者單獨(dú)處理了 mark-up 風(fēng)格的語言,比如 Markdown、CSS 和 HTML。走完所有過濾步驟后,markup 子集的規(guī)模為 180B tokens。
合成代碼數(shù)據(jù)。為了對代碼數(shù)據(jù)集進(jìn)行消融測試,研究者使用了專門的合成生成代碼數(shù)據(jù)集, 包含已經(jīng)正式驗(yàn)證過的 Python 編程問題。他們將該數(shù)據(jù)集作為高質(zhì)量代碼數(shù)據(jù)源,最終的合成數(shù)據(jù)集規(guī)模為 3.2B tokens。
相鄰代碼數(shù)據(jù)。為了探索不同屬性的代碼數(shù)據(jù),研究者還使用了包含 GitHub 提交、jupyter notebooks、StackExchange threads 等輔助數(shù)據(jù)的代碼數(shù)據(jù)。這類數(shù)據(jù)的規(guī)模為 21.4B tokens。
預(yù)訓(xùn)練冷卻數(shù)據(jù)集。冷卻包含在預(yù)訓(xùn)練最后階段提高更高質(zhì)量數(shù)據(jù)集的權(quán)重。對此,研究者選擇了包含高質(zhì)量文本、數(shù)學(xué)、代碼和指令型文本數(shù)據(jù)集的預(yù)訓(xùn)練冷卻混合。
評估
本文的目標(biāo)是系統(tǒng)地理解代碼對通用任務(wù)性能的影響,因此使用了一個(gè)廣泛的評估組件,涵蓋了包含代碼生成在內(nèi)的多樣下游任務(wù)。
為此,研究者在包含 1)世界知識(shí)、2)自然語言推理和 3)代碼性能的基準(zhǔn)上對模型進(jìn)行了評估。此外,他們還報(bào)告了通過 LLM-as-a-judge 評估的勝率(win-rates)。
下表 1 展示了完整的評估組件以及相應(yīng)的任務(wù)、數(shù)據(jù)集、指標(biāo)。

研究者對不同規(guī)模的模型(從 470M 到 2.8B 參數(shù))展開了性能評估。由于最小規(guī)模的模型能力有限,因此為了保證公平比較,他們只比較了所有模型均能達(dá)到隨機(jī)以上性能的基準(zhǔn)。
除了特定于任務(wù)的判別式性能,研究者評估了使用 LLM-as-a-judge 勝率的生成式性能。
訓(xùn)練與模型細(xì)節(jié)
如上文所說,對于預(yù)訓(xùn)練模型,研究者使用了 470M 到 2.8B 參數(shù)的 decoder-only 自回歸 Transformer 模型,它們按照標(biāo)準(zhǔn)語言建模目標(biāo)來訓(xùn)練。
具體來講,研究者使用了并行注意力層、SwiGLU 激活、沒有偏差的密集層和包含 256000 個(gè)詞匯的字節(jié)對編碼(BPE)tokenizer。所有模型使用 AdamW 優(yōu)化器進(jìn)行預(yù)訓(xùn)練,批大小為 512,余弦學(xué)習(xí)率調(diào)度器的預(yù)熱步為 1325,最大序列長度為 8192。
在基礎(chǔ)設(shè)施方面,研究者使用 TPU v5e 芯片進(jìn)行訓(xùn)練和評估。所有模型在訓(xùn)練中使用了 FAX 框架。為了嚴(yán)格進(jìn)行消融評估,研究者總共預(yù)訓(xùn)練了 64 個(gè)模型。每次預(yù)訓(xùn)練運(yùn)行使用 200B tokens,470M 參數(shù)模型用了 4736 TPU 芯片時(shí),2.8B 參數(shù)模型用了 13824 TPU 芯片時(shí)。每次冷卻運(yùn)行使用了 40B tokens,470M 參數(shù)模型用了 1024 TPU 芯片時(shí)。
實(shí)驗(yàn)結(jié)果
該研究展開了系統(tǒng)的實(shí)驗(yàn),探究了以下幾方面的影響:
- 使用代碼預(yù)訓(xùn)練模型初始化 LLM
- 模型規(guī)模
- 預(yù)訓(xùn)練數(shù)據(jù)中代碼的不同比例
- 代碼數(shù)據(jù)的質(zhì)量和屬性
- 預(yù)訓(xùn)練冷卻中的代碼數(shù)據(jù)
為了探究使用具有大量代碼數(shù)據(jù)的 LM 作為初始化是否可以提高模型性能,該研究針對不同的預(yù)訓(xùn)練模型初始化進(jìn)行了實(shí)驗(yàn)。如圖 2 所示,使用 100% 代碼預(yù)訓(xùn)練模型(code→text)進(jìn)行初始化能讓模型在自然語言 (NL) 推理基準(zhǔn)上獲得最佳性能,緊隨其后的是 balanced→text 模型。


為了了解上述結(jié)果是否可以遷移到更大的模型,該研究以 470M 模型相同的 token 預(yù)算,訓(xùn)練了 2.8B 參數(shù)模型。下圖顯示了 2.8B 模型與 470M 模型的比較結(jié)果。

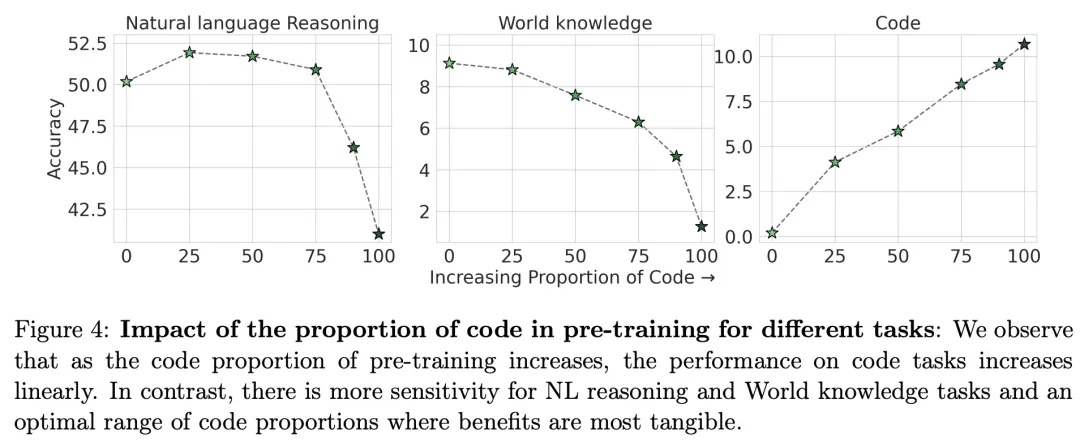
該研究探究了預(yù)訓(xùn)練中代碼數(shù)據(jù)比例對不同任務(wù)模型性能的影響,觀察到隨著預(yù)訓(xùn)練代碼數(shù)據(jù)比例的增加,代碼任務(wù)的性能呈線性提高,而對于 NL 推理任務(wù)和世界知識(shí)任務(wù)則存在效益最明顯的最佳代碼數(shù)據(jù)比例范圍。
如圖 5 (a) 所示,在評估代碼質(zhì)量和代碼構(gòu)成的影響方面,該研究觀察到,包含不同的代碼源和合成代碼,都會(huì)導(dǎo)致自然語言性能的提高,但是,只有合成生成的代碼才能提高代碼性能。
如圖 5 (b) 所示,在 NL 推理任務(wù)和代碼任務(wù)中,balanced+synth→text 比 balanced→text 分別實(shí)現(xiàn)了 2% 和 35% 的相對改進(jìn)。這進(jìn)一步證實(shí),即使是一小部分的高質(zhì)量代碼數(shù)據(jù),也可以提高代碼和非代碼任務(wù)的性能。

如圖 6 所示,該研究發(fā)現(xiàn):在預(yù)訓(xùn)練冷卻中包含代碼數(shù)據(jù),模型的NL推理性能增加 3.6%,世界知識(shí)性能增加 10.1%,代碼性能增加 20%。

如圖 7 所示,正如預(yù)期的那樣,冷卻對以勝率衡量的生成性能有重大影響。

采用不同預(yù)訓(xùn)練方案的模型的性能比較結(jié)果如表 2 所示,Balanced→Text 實(shí)現(xiàn)了最佳的 NL 性能,而 Balanced-only 在代碼生成方面明顯表現(xiàn)更好。


























