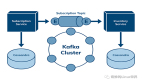
聊聊不同版本 Kafka Producer 的分區策略
1 問題現象
某微服務,使用 log4j kafka appender 寫日志到 kafka 中。業務同學反饋,微服務日志中有頻繁出現類似如下的kafka連接斷開的日志,希望分析下kafka連接斷開的原因,并確認是否會因此丟失微服務日志。
2024-08-08 07:10:06.994 -INFO [kafka-producer-network-thread | producer-1] org.apache.kafka.clients. NetworkClient -[Producer clientId=producer-1] Node 2 disconnected.)kafka連接斷開的具體日志如下圖所示:
 圖片
圖片
2 問題分析
- 由于kafka集群有多個broker節點,kafka topic 也有多個分區,所以微服務作為 kafka producer,在底層會建立對個 tcp 連接,以發送日志到各個 kafka topic partition。
- 通過 awk 篩選微服務日志可見,微服務針對同一個 kafka broker的tcp 連接,并不會頻繁斷開,且斷開的時點,一般是在業務低峰期,打印日志不多的時候:
 圖片
圖片
- 為進一步確認問題,在微服務節點上,可以查看下 TCP 連接的狀態(可以通過命令 netstat -apn -t|grep -i 9092 或 ss -antop |grep -i 9092),甚至通過 tcpdump 抓包分析下(可以通過命令nohup tcpdump tcp port 9092 -i any -s100 -B 8192 -p -n -w /tmp/9092.pcap >> /tmp/9092.out 2>&1 &)。
- 在生產環境中,使用上述命令,抓了近2個小時的包,并對 tcpdump 包文件進行了分析,如下圖可見,所有的tcp連接斷開,都是由微服務(即 kafka producer)主動斷開的,且具體來說,是微服務長達540秒,都不需要發送日志到某個具體的kafka topic partition時,因超時主動斷開的:
 圖片
圖片
image
 圖片
圖片
image
 圖片
圖片
3.問題原因
3.1 kafka 對空閑連接檢查和清理機制-producer 參數connections.max.idle.ms
為減輕對kafka broker 服務端的壓力,kafka producer 有空閑連接的檢查和清理機制:
- 當某個tcp連接長時間idle時,kafka producer就會主動關閉該空閑連接,并打印日志org.apache.kafka.clients. NetworkClient -[Producer clientId=producer-1] Node 2 disconnected;
- 判斷空閑連接的空閑閾值,就是參數 connections.max.idle.ms,該參數默認 540000 即 9 分鐘,這也與上述tcpdump抓包體現的,kafka producer 在540秒的空閑后,主動斷開連接的現象一致:
 圖片
圖片
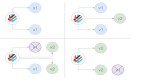
3.2 Kafka在key=null 時的分區策略- Sticky Partitioner vs Round Robin Partitioner
- Kafka producer 寫ProducerRecord到kafka topic時, ProducerRecord對應的具體 partiton分區,是由Partitioner分區器決定的。當 ProducerRecord 的key=null 時,會采用默認的分區器,在Kafka 2.3 及kafka2.3以下版本,默認的分區策略是Round Robin Partitioner;而Kafka 2.4 及以上版本,默認的分區策略是Sticky Partitioner。
- 目前該微服務,寫日志到 kafka 時,log4j2.xml中都沒有配置 kafka record key,且采用的是kafka-clients-3.4.0.jar,所以此時會使用 Sticky Partitioner 而不是 Round Robin Partitioner,相鄰的多個ProducerRecord都會屬于同一個 record batch,都會 “sticky” 到同一個分區,所以在日志低峰期,可能長時間都不會發送日志到某些分區,如果該時間超過了producer 參數 connections.max.idle.ms(默認 540000 即 9 分鐘),則該分區對應的 TCP 連接,就會被 PRODUCER 主動關閉,如果 kafka 分區較多比如100個,而微服務日志較少且 batch.size 和 linger.ms 較大,該現象會更加明顯。
4 問題總結
- 為減輕對服務端kafka broker的壓力,kafka producer 有空閑連接的檢查和清理機制,當某個tcp連接的idle時長大于參數connections.max.idle.ms時(該參數默認 540000 即 9 分鐘),kafka producer就會主動關閉該空閑連接,并打印日志org.apache.kafka.clients. NetworkClient -[Producer clientId=producer-1] Node 2 disconnected,此時所有的日志都會被正常落地,不會丟失日志數據;
- 當使用Kafka 2.4 及以上版本的 kafka producer時,如果沒有指定ProducerRecord的key,當業務低峰期微服務日志較少且 batch.size 和 linger.ms 較大時,上述kafka producer主動關閉空閑連接的現象會更加明顯,因為此時會使用默認的分區策略Sticky Partitioner,此時相鄰的多個ProducerRecord都會屬于同一個 record batch,都會 “sticky” 到同一個分區,所以可能長時間都不會發送日志到某些分區,如果該空閑時間超過了上述producer 參數 connections.max.idle.ms,則該分區對應的 TCP 連接,就會被 PRODUCER 主動關閉。
5.技術背景
5.1 KAFKA 客戶端和服務端在版本上的雙向兼容性
- KAFKA 客戶端和服務端在版本上具有雙向兼容性,即客戶端和服務端的版本可以不同:Kafka has a "bidirectional" client compatibility policy. In other words, new clients can talk to old servers, and old clients can talk to new servers. This allows users to upgrade either clients or servers without experiencing any downtime.
- 在上述案例中,kafka 集群服務端,使用的是kafka_2.11-2.2.0.jar;
- 在上述案例中,該微服務,通過logj寫日志到kafka時,使用的 kafka producer 版本是 kafka-clients-3.4.0.jar
- 目前 apache kafka 最新版是 Kafka 3.8 (截止 202409);
 圖片
圖片
5.2 kafka 對空閑連接檢查和清理機制-producer 參數connections.max.idle.ms
為減輕對kafka broker 服務端的壓力,kafka producer 有空閑連接的檢查和清理機制:
- 當某個tcp連接長時間idle時,kafka producer就會主動關閉該空閑連接,并打印日志org.apache.kafka.clients. NetworkClient -[Producer clientId=producer-1] Node 2 disconnected;
- 判斷空閑連接的空閑閾值,就是參數 connections.max.idle.ms,該參數默認 540000 即 9 分鐘,這也與上述tcpdump抓包體現的,kafka producer 在540秒的空閑后,主動斷開連接的現象一致;
5.3 Kafka在 key=null 時的分區策略- Sticky Partitioner vs Round Robin Partitioner
- Kafka producer 寫ProducerRecord到kafka topic時, ProducerRecord對應的具體 partiton分區,是由Partitioner分區器決定的;
- 當 ProducerRecord 的key=null 時,會采用默認的分區器,在Kafka 2.3 及kafka2.3以下版本,默認的分區策略是Round Robin Partitioner;而Kafka 2.4 及以上版本,默認的分區策略是Sticky Partitioner。
- When key=null, the producer has a default partitioner that varies: Round Robin: for Kafka 2.3 and below;Sticky Partitioner: for Kafka 2.4 and above:
With Kafka producer <= v2.3: when there’s no partition and no key specified, the default partitioner sends data in a round-robin fashion. This results in more batches (one batch per partition) and smaller batches (imagine with 100 partitions). And this is a problem because smaller batches lead to more requests as well as higher latency.
With Kafka producer >= v2.4: Sticky Partitioner improves the performance of the producer especially with high throughput. It is a performance goal to have all the records sent to a single partition and not multiple partitions to improve batching. The producer sticky partitioner will “stick” to a partition until the batch is full or linger.ms has elapsed; After sending the batch, kafka producer will change the partition that is "sticky". This will lead to larger batches and reduced latency (because we have larger requests, and the batch.size is more likely to be reached). Over time, the records are still spread evenly across partitions, so the balance of the cluster is not affected.
5.4 相關源碼與參考鏈接
-- 相關源碼
org.apache.kafka.clients.producer.Partitioner
org.apache.kafka.clients.producer.internals.DefaultPartitioner
org.apache.kafka.clients.producer.UniformStickyPartitioner
org.apache.kafka.clients.producer.RoundRobinPartitioner
-- 參考連接:
KIP-480: Sticky Partitioner
KIP-794: Strictly Uniform Sticky Partitioner
https://cwiki.apache.org/confluence/display/KAFKA/KIP-794%3A+Strictly+Uniform+Sticky+Partitioner
https://cwiki.apache.org/confluence/display/KAFKA/KIP-480%3A+Sticky+Partitioner