Kafka如何修改分區Leader

前幾天有個群友問我: kafka如何修改優先副本? 他們有個需求是, 想指定某個分區中的其中一個副本為Leader
在這里插入圖片描述
需求分析
對于這么一個問題,在我們生產環境還是挺常見的,經常有需要修改某個Topic中某分區的Leader
比如 topic1-0這個分區有3個副本[0,1,2], 按照「優先副本」的規則
那么 0 號副本肯定就是Leader了 我們都知道分區中的只有Leader副本才會提供讀寫副本
其他副本作為備份 假如在某些情況下,「0」 號副本性能資源不夠,或者網絡不太好,或者IO壓力比較大
那么肯定對Topic的整體讀寫性能有很大影響, 這個時候切換一臺壓力較小副本作為Leader就顯得很重要;
優先副本: 分區中的AR(所有副本)信息, 優先選擇排在第一位的副本作為Leader
Leader機制: 分區中只有一個Leader來承擔讀寫,其他副本只是作為備份
那么如何實現這樣一個需求呢?
解決方案
知道了原理之后,我們就能想到對應的解決方案了 只要將 分區的 AR 中的第一個位置,替換成你指定副本就行了;AR = { 0,1,2 } ==> AR = {2,1,0}
一般能夠達到這個目的有兩種方案,下面我們來分析一下
方案一: 分區副本重分配
之前關于分區副本重分配 我已經寫過很多文章了,如果想詳細了解 分區副本重分配、數據遷移、副本擴縮容 可以看看鏈接的文章, 這里我就簡單說一下;
一般分區副本重分配主要有三個流程
- 生成推薦的遷移Json文件
- 執行遷移Json文件
- 驗證遷移流程是否完成
這里我們主要看第2步驟, 來看看遷移文件一般是什么樣子的
- {
- "version": 1,
- "partitions": [{
- "topic": "topic1",
- "partition": 0,
- "replicas": [0,1,2]
- }]
- }
這個遷移Json意思是, 把topic1的「0」號分區的副本分配成[0,1,2] ,也就是說 topic1-0號分區最終有3個副本分別在 {brokerId-0,brokerId-1,brokerId-2} ;
如果你有看過我之前寫的 分區副本重分配原理源碼分析 ,那么肯定就知道
不管你之前的分配方式是什么樣子的, 最終副本分配都是 [0,1,2] , 之前副本多的,會被刪掉,少的會被新增;
那么我們想要實現 我們的需求 是不是把這個Json文件 中的 "replicas": [0,1,2] 改一下就行了
比如改成 "replicas": [2,1,0] 改完Json后執行,執行execute, 正式開始重分配流程! 遷移完成之后, 就會發現,Leader已經變成上面的第一個位置的副本「2」 了
優缺點
優點: 實現了需求, 并且主動切換了Leader
缺點: 操作比較復雜容易出錯,需要先獲取原先的分區分配數據,然后手動修改Json文件,這里比較容易出錯,影響會比較大,當然這些都可以通過校驗接口來做好限制, 最重要的一點是 副本重分配當前只能有一個任務 ! 假如你當前有一個「副本重分配」的任務在,那么這里就不能夠執行了, 「副本重分配」是一個比較「重」 了的操作,出錯對集群的影響比較大
方案二: 手動修改AR順序
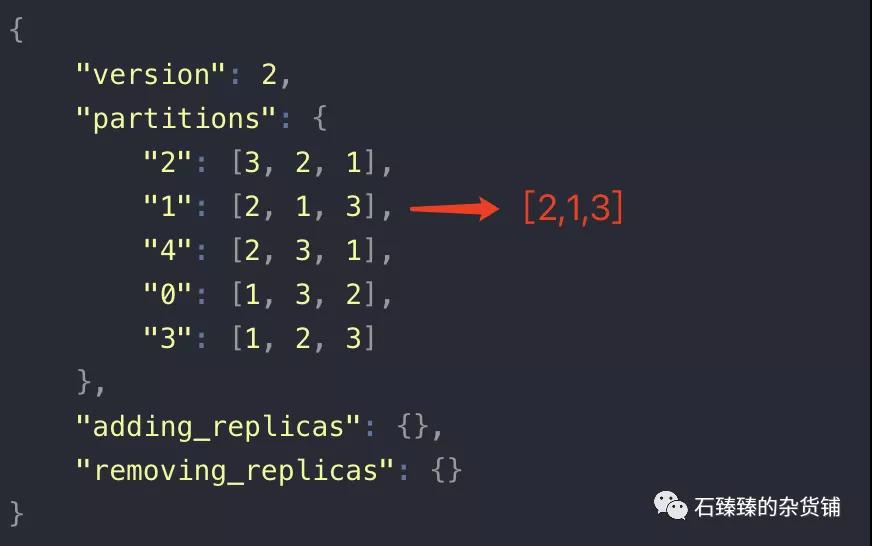
首先,我們知道分區副本的分配數據是保存在zookeeper中的節點brokers/topics/{topicName} 中; 我們看個Topic1的節點數據例子;
- {
- "version": 2,
- "partitions": {
- "2": [3, 2, 1],
- "1": [2, 1, 3],
- "4": [2, 3, 1],
- "0": [1, 3, 2],
- "3": [1, 2, 3]
- },
- "adding_replicas": {},
- "removing_replicas": {}
- }
數據解釋:version:版本信息, 現在有 「1」、「2」 兩個版本
removing_replicas:需要刪除的副本數據, 在進行分區副本重分配過程中, 多余的副本會在數據遷移快完成的時候被刪除掉,刪除成功這里的數據會被清除
adding_replicas:需要新增的副本數據,在進行分區副本重分配過程中, 新增加的副本將會被新增,新增完成這里的數據會清除;
partitions:Topic的所有分區副本分配方式; 上面表示總共有5個分區,以及對應的副本位置;
知道了這些之后,想要修改優先副本,是不是可以通過直接修改zookeeper中的節點數據就行了; 比如 我們把 「1」號分區的副本位置改成 [2,1,3]
改成這樣之后, 還需要 執行 重新進行優先副本選舉操作 ,例如通過kafka的命令執行
- sh bin/kafka-leader-election.sh --bootstrap-server xxxx:9090 --topic Topic1--election-type PREFERRED --partition 1
--election-type : PREFERRED 這個表示的以優先副本的方式進行重新選舉
那么做完這兩步之后, 我們的修改優先副本的目的就達成了.........嗎 ?
實則并沒有, 因為這里僅僅只是修改了 zookeeper節點的數據
而bin/kafka-leader-election.sh 重選舉的操作是Controller來進行的; 如果你對Controller的作用和源碼足夠了解
肯定知道Controller里面保存了每個Topic的分區副本信息, 是保存在JVM內存中的, 然后我們手動修改Zookeeper中的節點,并沒有觸發 Controller更新自身的內存
也就是說 就算我們執行了kafka-leader-election.sh, 它也不會有任何變化,因為優先副本沒有被感知到修改了;
解決這個問題也很簡單,讓Controller感知到數據的變更就行了 最簡單的方法, 讓Controller發生重新選舉, 數據重新加載!
總結
手動修改zookeeper中的「AR」順序
Controller 重新選舉
執行 分區副本重選舉操作(優先副本策略)
簡單代碼
當然上面功能,肯定是要集成到LogiKM中的咯; 簡單代碼如下
- // 這里轉換成HashMap類型,切勿自定義類型,以防kafka節點數據后續新增數據節點,導致數據丟失
- HashMap partitionMap = zkConfig.get(ZkPathUtil.getBrokerTopicRoot(topicName), HashMap.class);
- JSONObject partitionJson = (JSONObject)partitionMap.get("partitions");
- JSONArray partitions = (JSONArray)partitionJson.get(partition);
- //部分代碼省略
- //調換序列 優先副本
- Integer first = partitions.getInteger(0);
- partitions.set(0,targetBroker);
- partitions.set(index,first);
- zkUtils = ZookeeperUtils.getKafkaZkUtils(clusterDO.getZookeeper());
- String json = JSON.toJSONString(partitionMap);
- zkUtils.updatePersistentPath(ZkPathUtil.getBrokerTopicRoot(topicName), json,null);
- //寫入成功之后觸發一下 異步去優先副本選舉
- new Thread(()->{
- try {
- // 1. 先讓Controller重新選舉 (不然上面修改的還沒有生效) (TODO.. 待優化 -> 頻繁的Controller重選舉對集群性能會有影響)
- zkConfig.deletePath(ZkPathUtil.CONTROLLER_ROOT_NODE);
- // 等待 Controller 選舉一下
- Thread.sleep(1000);
- //2. 然后再發起副本重新選舉
- preferredReplicalElectCommand.preferredReplicaElection(clusterId,topicName,partition,"");
- } catch (ConfigException | InterruptedException e) {
- LOGGER.error("重新選舉異常.e:{}",e);
- e.printStackTrace();
- }
- }).start();
優缺點
優點: 實現了目標需求, 簡單, 操作方便
缺點: 頻繁的Controller重選舉對生產環境來說會有一些影響;
優化與改進
第二種方案中,需要Controller 重選舉, 頻繁的選舉肯定是對生產環境有影響的;Controller承擔了非常多的責任,比如分區副本重分配、刪除topic、Leader選舉 等等還有很多都是它在干!
那么如何不進行Controller的重選舉,也能達到我們的需求呢?
我們的需求是,當我們 修改了zookeeper中的節點數據的時候,能夠迅速的讓Controller感知到,并更新自己的內存數據就行了;
對于這個問題,我會在下一期文章中介紹
問題
看完這篇文章,提幾個相關的問題給大家思考一下;
如果我在修改zk中的「AR」信息時候不僅僅是調換順序,而是有新增或者刪除副本會發生什么情況呢?
如果手動修改brokers/topics/{topicName}/partitions/{分區號}/state 節點里面的leader信息,能不能直接更新Leader?
副本選舉的整個流程是什么樣子的?
大家可以思考一下, 問題答案我會在后面的文章中一一講解!