紐約大學和博世最新AdaOcc:自適應分辨率占用預測

- 論文鏈接:https://arxiv.org/pdf/2408.13454
- 代碼鏈接:https://github.com/ai4ce/Bosch-NYU-OccupancyNet/
摘要
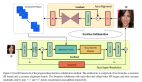
本文介紹了AdaOcc:自適應分辨率占用預測。在復雜的城市場景中實現自動駕駛需要3D感知既全面又精確。傳統的3D感知方法著重于目標檢測,導致缺乏環境細節信息的稀疏表示。最近的方法估計車輛周圍的3D占用,以獲得更全面的場景表示。然而,稠密的3D占用預測提高了計算需求,給效率和分辨率之間的平衡帶來挑戰。高分辨率占用柵格提供了準確性,但是需要大量的計算資源,而低分辨率柵格效率高,但是缺乏細節信息。為了解決這一難題,本文引入了AdaOcc,這是一種新的自適應分辨率、多模態的預測方法。本文方法將以目標為中心的3D重建和整體占用預測集成到一個框架內,僅在感興趣區域(ROIs)內進行高度精細且精確的3D重建。這些高度精細的3D表面以點云表示,因此其精度不受占用地圖的預定義柵格分辨率所限制。本文在nuScenes數據集上進行全面實驗,證明了相比于現有方法具有顯著改進。在近距離場景中,本文方法在IOU上超過先前的基線13%,在Hausdorff距離上超過了40%。總之,AdaOcc提供了更通用、更有效的框架,能夠在各種駕駛場景中提供準確的3D語義占用預測。
主要貢獻
本文的貢獻總結如下:
1)本文提出了一種多模態自適應分辨率方法,在關鍵區域中提供了三種高精度的輸出表示,同時維持實時應用的效率;
2)本文開發了一種有效的聯合訓練范式,可以增強占用預測和目標折疊分支之間的協同作用;
3)本文方法在nuScenes數據集上展現出卓越的精度,特別是在需要精確行為的近距離場景中表現出色。
論文圖片和表格








總結
總之,本文所提出的方法提供了一種多模態自適應分辨率方法,在關鍵區域中提供了三種具有高精度表面的輸出表示,同時確保了實時應用的效率。此外,本文還開發了一種有效的聯合訓練范式,以增強占用和折疊網絡之間的協同作用,從而提高近距離占用預測的性能。本文方法在nuScenes數據集上展現出卓越的精度,突出了對精細表面重建的注重。
局限性:本文發現,聯合訓練方法沒有顯著提高目標檢測任務的質量。需要進一步研究粗略占用預測和目標表面重建之間的相互作用,以提高不同表示之間的一致性。此外,通過更高級的并行化設計,能夠進一步優化統一框架的效率。