最新NaViT模型炸場!適用任何長寬比+分辨率,性能能打的Transformer
今天要介紹的是NaViT,這是一種適用于任何長寬比以及分辨率的Transformer模型。

在使用計算機視覺模型處理圖像之前,要先將圖像調整到固定的分辨率,這種方式很普遍,但并不是最佳選擇。
Vision Transformer(ViT)等模型提供了靈活的基于序列的建模,因此可以改變輸入序列的長度。
在本篇論文中,研究人員利用NaViT(原生分辨率ViT)的這一優勢,在訓練過程中使用序列打包,來處理任意分辨率和長寬比的輸入內容。
在靈活使用模型的同時,研究人員還展示了在大規模監督和對比圖像-文本預訓練中訓練效率的提高。
NaViT可以高效地應用于圖像和視頻分類、物體檢測和語義分割等標準任務,并在魯棒性和公平性基準方面取得了更好的結果。
在推理時,輸入分辨率的靈活性可用于平滑地控制測試時間的性價比權衡。
研究人員相信,NaViT標志著脫離了大多數計算機視覺模型所使用的標準CNN設計的輸入和建模流水線,代表了ViTs的一個有前途的方向。
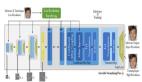
如下圖所示,NaViT在預訓練期間(左圖)有顯著的計算效率,并可用于下游微調(中圖)。
且單個NaViT可成功應用于多個分辨率(右圖),在性能和推理成本之間實現平衡。
 圖片
圖片
要知道,深度神經網絡通常以成批輸入進行訓練和運行。
為了在硬件上實現高效的處理,意味著批次形狀是固定的,反過來又說明計算機視覺應用的圖像大小是固定的。
這一點再加上卷積神經網絡歷來存在的架構限制,導致研究人員要么調整圖像大小,要么將圖像填充為固定大小。
但這兩種方法都存在缺陷:前者損害性能,后者效率低下。
ImageNet、LVIS和WebLI分別作為分類、檢測和網絡圖像數據集的代表實例,對其長寬比的分析表明,大多數圖像通常不是正方形的,如下圖所示。
 圖片
圖片
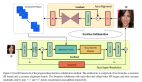
在語言建模中,通常通過示例打包繞過固定序列長度的限制:來自多個不同示例的標記被組合在一個序列中,這可以顯著加快語言模型的訓練。
通過將圖像視為補丁(標記)序列,研究人員發現,Vision Transformers也能從同樣的范式中獲益,研究人員稱之為Patch n' Pack。
應用這種技術,可以在原有的分辨率的圖像上訓練視覺transformer。
示例包裝后可以在保持長寬比的情況下實現可變分辨率圖像,從而減少訓練時間,提高性能和靈活性。
研究人員展示了為支持Patch n'Pack而需要修改的數據預處理和建模。
 圖片
圖片
研究人員在NaViT中使用的基本架構沿用了Vanilla ViT,并進行了必要修改。
此外,研究人員還對ViT進行了一些小的改進。
研究人員在兩種設置中對NaViT進行預訓練:在JFT-4B上進行分類訓練和在WebLI上進行對比語言圖像訓練。
通常情況下,對于JFT,在訓練前會對圖像進行截取。而在這兩種情況下,圖像都會被調整為正方形。
除非另有說明,所有NaViT模型都是在沒有這些操作的情況下進行預訓練的,并保留了原有的長寬比。
NaViT使用FLAX庫,在JAX中實現,并在Scenic中進行構建。
這里研究人員進行了兩種不同的與訓練——
分類預訓練和對比預訓練。
 圖片
圖片
上圖展示了通過序列打包實現的連續token丟棄策略,提高了表現性能。
研究人員對論文中所介紹的的因子化嵌入及其設計選擇進行評估。
他們關注的是絕對性能,以及對訓練體系之外的分辨率的推斷。
為了測試這一點,研究人員在JFT上對NaViT-B/16模型進行了200k步的訓練,分辨率為R~U(160, 352)。
在不修改嵌入變量的情況下,研究人員評估了一系列分辨率下的性能,將ViT-B/16與在固定分辨率256下訓練的ViT-B/16進行比較。
對于相同數量的圖像,在新的分辨率下使用位置嵌入的標準插值進行了評估。
下圖則是測試結果。
很明顯能發現的是,因子化方法優于基線ViT和Pix2struct的學習型二維嵌入,后者尤其難以泛化到更高分辨率。
NaViT在ImageNet-A上的表現也更好,因為ImageNet-A上有許多長寬比極高的圖像,而且重要信息都在圖片中心之外。
 圖片
圖片
下圖展示了使用NaViT-L/16或ViT-L/16評估根據公平性相關信號訓練的注釋器的準確性。
左圖:NaViT提供了更好的表示方法,提高了注釋器的準確性。
右圖:與將圖像大小調整為正方形相比,在NaViT中使用原始長寬比可獲得更高的性能。
 圖片
圖片
研究人員已經證明,Patch n' Pack--序列打包在視覺變換器中的簡單應用--可顯著提高訓練效率。由此產生的NaViT模型可在推理時應用于多種分辨率,并以低成本適應新任務。
Patch n'Pack使得以前因為需要固定形狀而進行不下去的各種研究成為可能,包括自適應計算和提高訓練和推理效率的新算法。
詳細研究請參考原論文。因能力有限,本文翻譯中若有錯訛,深表歉意。