













檢索總結能力超博士后,首個大模型科研智能體PaperQA2開源了
最近一段時間,有關 AI 科學家的研究越來越多。大語言模型(LLM)有望幫助科學家檢索、綜合和總結文獻,提升人們的工作效率,但在研究工作中使用仍然有很多限制。
對于科研來說,事實性至關重要,而大模型會產生幻覺,有時會自信地陳述沒有任何現有來源或證據的信息。另外,科學需要極其注重細節,而大模型在面對具有挑戰性的推理問題時可能會忽略或誤用細節。
最后,目前科學文獻的檢索和推理基準尚不完善。AI 無法參考整篇文獻,而是局限于摘要、在固定語料庫上檢索,或者只是直接提供相關論文。這些基準不適合作為實際科學研究任務的性能代理,更重要的是,它們通常缺乏與人類表現的直接比較。因此,語言模型和智能體是否適合用于科學研究仍不清楚。
近日,來自 FutureHouse、羅切斯特大學等機構的研究者們嘗試構建一個更為強大的科研智能體,并對 AI 系統和人類在三個現實任務上的表現進行嚴格比較。這三個任務有關搜索整個文獻以回答問題;生成一篇有引用的、維基百科風格的科學主題文章;從論文中提取所有主張,并檢查它們與所有文獻之間的矛盾。
這可能是第一個在多個現實文獻搜索任務上評估單個 AI 系統的強大程序。利用新開發的評估方法,研究者探索了多種設計,最終形成了 PaperQA2 系統,它在檢索和總結任務上的表現超過了博士生和博士后。

將 PaperQA2 應用于矛盾檢測任務讓我們能夠大規模識別生物學論文中的矛盾。例如,ZNF804A rs1344706 等位基因對精神分裂癥患者的大腦結構有積極影響的說法與后來發表的研究相矛盾,該研究發現 rs1344706 對大腦皮質厚度、表面積和皮質體積的影響會加劇患精神分裂癥的風險。

- 論文地址:https://storage.googleapis.com/fh-public/paperqa/Language_Agents_Science.pdf
- GitHub 鏈接:https://github.com/Future-House/paper-qa
網友紛紛表示這項工作太棒了,并且是開源的。

回答科學問題
為了評估 AI 系統對科學文獻的檢索能力,研究者首先生成了 LitQA2,這是一組共 248 個多項選擇題,其答案需要從科學文獻中檢索。LitQA2 問題的設計目的是讓答案出現在論文正文中,但不出現在摘要中,理想的情況下,在所有科學文獻中只出現一次。這些約束使我們能夠通過將系統引用的來源 DOI 與問題創建者最初分配的 DOI 進行匹配來評估回答的準確性(下圖 A)。
為了執行這些標準,研究者生成了大量關于最近論文中模糊的中間發現的問題,然后排除了任何現有 AI 系統或人類注釋者可以使用替代來源進行回答的問題。它們都是由專家生成的。
在回答 LitQA2 問題時,模型可以通過選擇「信息不足,無法回答此問題」來拒絕回答。與先前的研究和實際的科學問題類似,有些問題本來就是無法回答的。研究者評估了兩個指標:精確度(即在提供答案時正確回答的問題的比例)和準確度(即所有問題中正確答案的比例)。此外還考慮了召回率,即系統將其答案歸因于 LitQA2 中表示的正確源 DOI 的問題的總百分比。

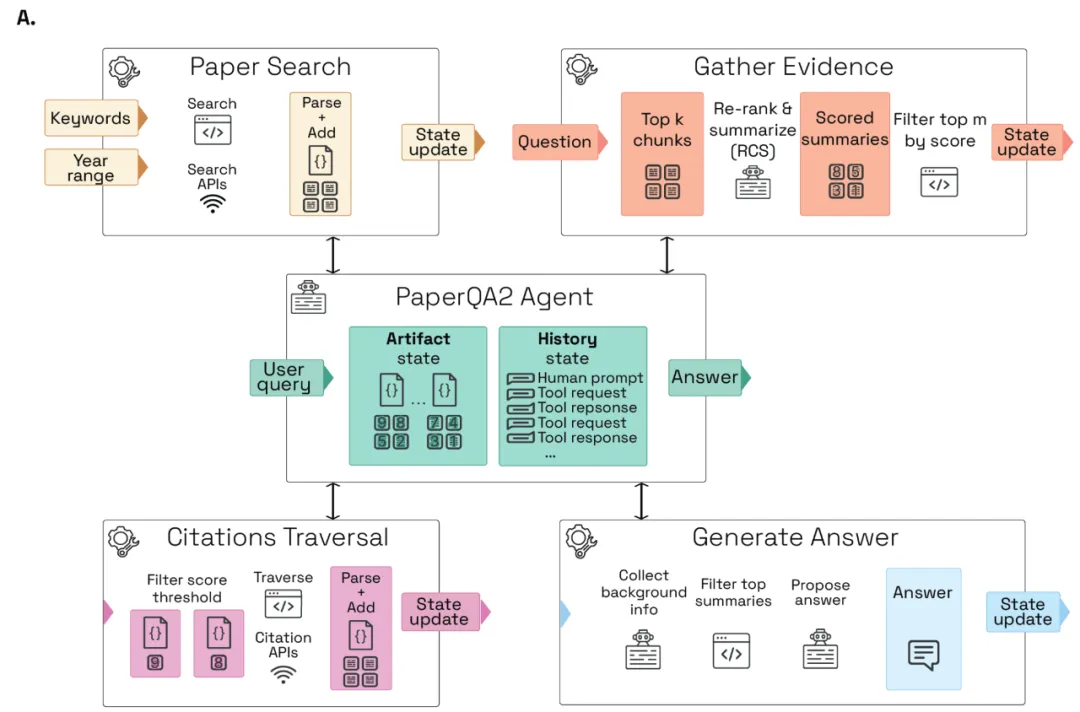
在開發了 LitQA2 之后,研究者利用它來設計一個科學文獻的 AI 系統。在 PaperQA 的啟發下,PaperQA2 是一個 RAG 智能體,它將檢索和響應生成視為一個多步驟智能體任務,而不是一個直接過程。PaperQA2 將 RAG 分解為工具,使其能夠修改其搜索參數,并在生成最終答案之前生成和檢查候選答案(下圖 A)。
PaperQA2 可以訪問「論文搜索」工具,其中智能體模型將用戶請求轉換為用于識別候選論文的關鍵字搜索。候選論文被解析為機器可讀的文本,并分塊以供智能體稍后使用。PaperQA2 使用最先進的文檔解析算法(Grobid19),能可靠地解析論文中的章節、表格和引文。找到候選論文后,PaperQA2 可以使用「收集證據」工具,該工具首先使用 top-k 密集向量檢索步驟對論文塊進行排序,然后進行大模型重新排序和上下文摘要(RCS)步驟。
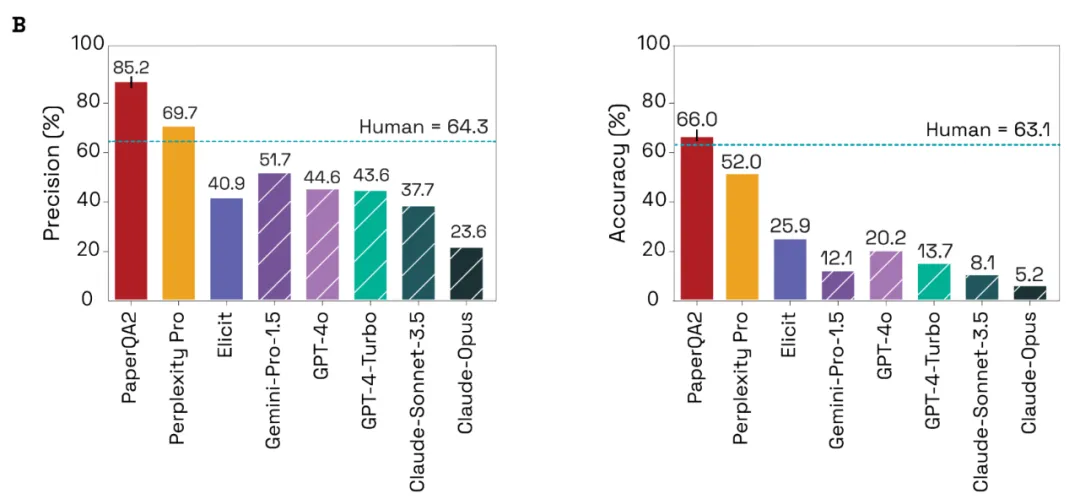
在回答 LitQA2 問題時,PaperQA2 平均每道題解析并使用 14.5 ± 0.6(平均值 ± SD,n = 3)篇論文。在 LitQA2 上運行 PaperQA2 可獲得 85.2% ± 1.1%(平均值 ± SD,n = 3)的精確度和 66.0% ± 1.2%(平均值 ± SD,n = 3)的準確度。另外,系統在 21.9% ± 0.9%(平均值 ± SD,n = 3)的答案中選擇報告「信息不足」(下圖 B)。
研究者發現 PaperQA2 在 LitQA2 基準測試中的精確度和準確度均優于其他 RAG 系統。我們還可以發現,除 Elicit 外所有測試的 RAG 系統在精確度和準確度方面均優于非 RAG 前沿模型。
為了確保 PaperQA2 不會過擬合,從而無法在 LitQA2 上取得優異成績,研究者在對 PaperQA2 進行大量工程改動后,生成了一組新的 101 個 LitQA2 問題。
PaperQA2 在原始 147 個問題上的準確率與后一組 101 個問題的準確率沒有顯著差異,這表明在第一階段的優化已經很好地推廣到了新的 LitQA2 問題(下表 2)。

PaperQA2 性能分析
研究者嘗試改變 PaperQA2 的參數,以了解哪些參數決定其準確性(下圖 C)。他們創建了一個非智能體版本,其中包含一個硬編碼操作序列(論文搜索、收集證據,然后生成答案)。非智能體系統的準確率明顯較低(t (3.7)= 3.41,p= 0.015),驗證了使用智能體的選擇。
研究者將性能差異歸因于智能體更好的記憶能力,因為它可以在觀察到找到的相關論文數量后返回并更改關鍵字搜索(論文搜索工具調用)。
結果顯示,LitQA2 運行準確度最高時為每個問題進行了 1.26 ± 0.07(平均值 ± SD)次搜索,每個問題進行了 0.46 ± 0.02(平均值 ±SD)次引用遍歷,這表明智能體有時會返回進行額外搜索或遍歷引用圖以收集更多論文。
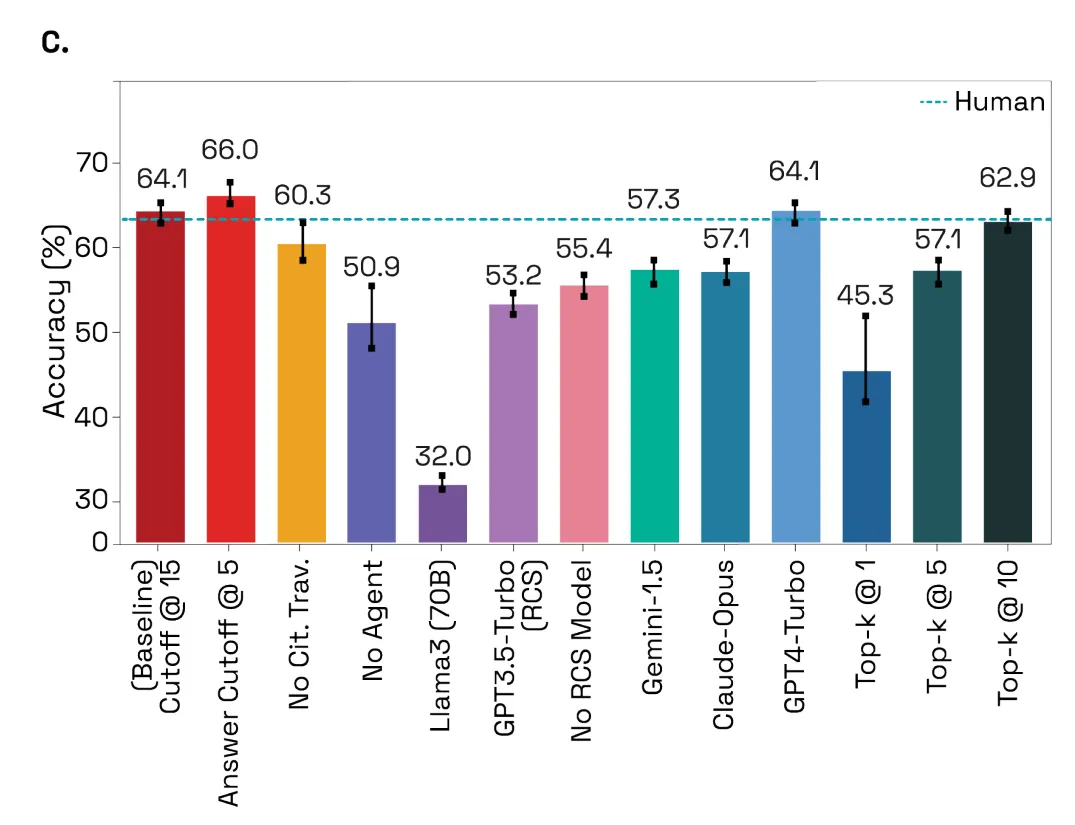
為了改進相關塊檢索,研究者假設,找到的論文對于現有相關塊的引用者或被引用者而言將是一種有效的分層索引形式。通過去除「引用遍歷」工具驗證了這一點,該工具顯示準確率有所提高(t (2.55) = 2.14,p= 0.069),DOI 召回率顯著提高(t (3) = 3.4,p = 0.022),并在 PaperQA2 流程的所有階段都是如此。該工具的流程反映了科學家與文獻互動的方式。
研究者曾假設解析質量會影響準確度,但 Grobid 解析和更大的塊并沒有顯著提高 LitQA2 的精度、準確度或召回率(下圖 6)。

總結科學主題
為了評估 PaperQA2 的摘要功能,研究者設計了一個名為 WikiCrow 的系統。該系統通過結合多個 PaperQA2 調用來生成有關人類蛋白質編碼基因的維基百科風格文章,而這些調用涉及基因的結構、功能、相互作用和臨床意義等主題。
研究者使用 WikiCrow 生成了 240 篇有關基因的文章,這些文章已經有非存根維基百科文章進行匹配比較。WikiCrow 文章平均為 1219.0 ± 275.0 個字(平均值 ± SD,N = 240),比相應的維基百科文章(889.6 ± 715.3 個字)長。平均文章生成時間為 491.5 ± 324.0 秒,平均每篇文章成本為 4.48 ± 1.02 美元(包括搜索和 LLM API 的費用)。

同時,「引用但不受支持」評估類別包括不準確的陳述(例如真實幻覺或推理錯誤)和準確但引用不當的聲明。
為了進一步調查維基百科和 WikiCrow 中的錯誤性質,研究者手動檢查了所有報告的錯誤,并嘗試將問題分類為以下幾類:
- 推理問題,即書面信息自相矛盾、過度推斷或不受任何引用支持;
- 歸因問題,即信息可能得到另一個包含的來源支持,但該聲明在本地沒有包含正確的引用或來源太寬泛(例如數據庫門戶鏈接);
- 瑣碎的聲明,這些聲明雖是真實的段落,但過于迂腐或沒有必要。

檢測文獻中的矛盾
由于 PaperQA2 可以比人類科學家探索吞吐量高得多的科學文獻,因此研究者推測可以部署它來系統地、大規模地識別文獻中矛盾和不一致的地方。矛盾檢測是一個「一對多」問題,原則上涉及將一篇論文中的觀點或聲明與文獻中所有其他觀點或聲明進行比較。在規模上,矛盾檢測變成了「多對多」問題,對人類來說失去了可行性。
因此,研究者利用 PaperQA2 構建了一個名為 ContraCrow 的系統,可以自動檢測文獻中的矛盾(下圖 A)。

ContraCrow 首先使用一系列 LLM completion 調用從提供的論文中提取聲明,然后將這些聲明輸入到 PaperQA2 中,并附帶矛盾檢測提示。該提示指示系統評估文獻中是否存在與提供的聲明相矛盾的內容,并提供答案和 11-point 李克特量表的選擇。使用李克特量表可讓系統在提供排名時給出更可靠、更易于解釋的分數。

接下來,研究者評估了 ContraCrow 檢測 ContraDetect 中矛盾的能力。通過將李克特量表輸出轉換為整數,他們能夠調整檢測閾值并獲得 AUC 為 0.842 的 ROC 曲線。將閾值設置為 8(矛盾),ContraCrow 實現了 73% 的準確率、88% 的精度和僅為 7% 的假陽性率(下圖 C)。

研究者將 ContraCrow 應用于從數據庫中隨機選擇的 93 篇生物學相關論文,平均每篇論文識別出 35.16 ± 21.72(平均值 ± SD,N = 93)個聲明。在對 93 篇論文分析出的 3180 個聲明中,ContraCrow 認為 6.85% 與文獻相矛盾,其中分別有 2.89%、3.77% 和 0.19% 的聲明被打了 8 分、9 分和 10 分(下圖 D)。

此外,當將李克特量表閾值設定為 8,研究者發現平均每篇論文有 2.34 ± 1.99 個矛盾(平均值 ± SD)(下圖 E)。

更多任務細節和測試結果請參閱原論文。



















