













可「自主進化」的Agent?首個端到端智能體符號化訓練框架開源了
本文主要作者來自波形智能、浙江大學、和北京航空航天大學。共同一作中,周王春澍是波形智能的聯合創始人和 CTO,歐翌昕是浙江大學碩士二年級,丁盛為為北京航空航天大學四年級本科生。文章的通訊作者為周王春澍和姜昱辰,姜昱辰是波形智能的聯合創始人和 CEO。
隨著各類大模型 API 的迭代以及各類 AI Agent 框架的開源,基于大模型的智能體在學術界和工業界收獲了廣泛的關注、研究、和應用。
盡管基于大模型的智能體 (AI Agent) 在很多場景都取得了不錯的效果,并且在一些場景下已經能夠實際落地應用,AI Agent 的研究和開發的進展仍然局限于 “expert-centric”,或者說 “engineering-centric” 的范式中。也就是說,現在的 Agent 的創建和調優過程還是幾乎完全依賴人類專家 (算法工程師) 的人力和經驗來設計智能體的 promtps, tools,和 workflow。這樣的過程費時費力,并且注定了無法使用海量數據對智能體的這些符號化元素進行學習和訓練。而大部分智能體依賴于閉源的 API 調用,無法對大模型基座本身進行優化,即使使用開源大模型,對模型基座本身的優化也在大部分 AI 智能體的應用場景中受到資源、算力、穩定性等原因而無法實際進行。因此現在的智能體還處于 “專家系統” 的發展階段。
眾所周知,神經網絡成為機器學習 / 人工智能的基礎范式的重要原因正是因為可以高效地使用海量數據進行訓練和優化,而不需要手工設計復雜的結構和學習算法。因此,來自波形智能的研究人員們認為,AI Agent 從以專家經驗為核心 (expert-centric) 到以數據為核心 (data-centric) 的轉變,將會是基于大模型的智能體的一個重要發展方向。
為了實現這個目標,來自波形智能的研究團隊借鑒連接主義訓練神經網絡 (connectionist learning) 的基本方式,即反向傳播和梯度下降,將 AI Agent 和神經網絡進行類比,使用文本和大模型建模損失函數、梯度、和優化器,模擬反向傳播和梯度下降算法,實現對 Agent 的端到端的符號化訓練算法,構建了一套可以對 AI 智能體進行端到端訓練的算法框架,代碼已經開源在 GitHub。

- 論文地址:https://arxiv.org/pdf/2406.18532
- 代碼倉庫:https://github.com/aiwaves-cn/agents
具體來說,團隊首先將基于大模型的智能體解構為三個主要元素,即 prompts, tools, 和 agent pipeline (workflow)。接著,框架中將一個 Agent 系統看作是一個 “符號化” 神經網絡,將 Agent workflow 中的每一個 node 看作是網絡中的一個 layer,而將每個節點中的 prompts 和 tools 看作是這個 layer 的 weights,智能體的 workflow/pipeline 則可以看作是網絡的計算圖。這樣下來,智能體系統可以看作是一個權重從數字 / 張量空間變成離散符號空間 (文字,代碼都是符號化的表示) 的神經網絡,而這種網絡的訓練自然也就可以參考傳統神經網絡的優化方式,即反向傳播和梯度下降。
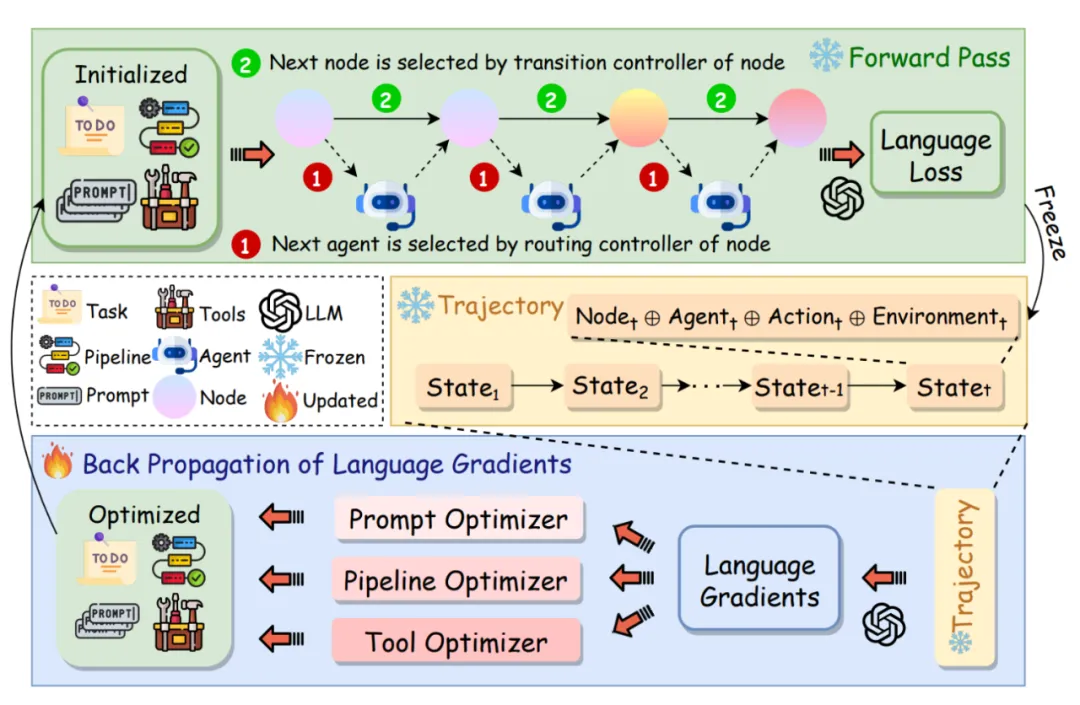
圖 1: Agent Symbolic Learning 框架示意圖
要使傳統的反向傳播和梯度下降能夠處理符號化的權重空間,agent symbolic learning 框架中通過文本和大模型 + 提示詞的方式建模了損失,損失函數,反向傳播的流程,梯度,以及基于梯度的優化器。具體來說,前向傳播過程中,框架會將每一層的輸入、權重、和輸出都保存在計算圖中。接下來,通過大模型 + 提示詞的方式,在提示詞中結合當前樣本的輸入,輸出,和整體任務的描述,之后由大語言模型輸出對當前樣本任務完成情況的評價和總結。得到的文本形式的評價 / 總結,正如神經網絡中的 loss 一樣,用來衡量任務完成的好壞,研究團隊將其稱為 “文本形式的損失”,即 language-based loss。
之后,該研究通過大語言模型和精心設計的提示詞工程,來生成智能體流程中對最后一個節點的 “反思”。反思中包括模型的輸出應該怎樣變化才能更符合要求,以及提示詞和工具調用應該如何優化才能使輸出朝這樣的方向發生變化。這一內容和神經網絡優化中梯度的作用剛好一致,都是包含了參數應該如何調整才能最小化整個模型的損失的信息,因此研究團隊將這樣的反思稱作 “文本形式的梯度”,即 language-based gradient。
接下來要做的就是從后向前,得到每一層的梯度,這對于神經網絡的優化至關重要。受到神經網絡中基于鏈式法則的公式的反向傳播的啟發,波形智能的研究人員通過文本和大模型,用一套精心設計的 prompt 來模擬了傳統神經網絡優化的鏈式法則。具體來說,這套 prompts 讓大模型基于上一層的梯度信息 (即對上一層執行任務的反思) 以及本層的輸入、輸出、以及權重 (這些輸入和反向傳播公式中的參數完全對應),輸出對當前節點的 prompt/tool usage 的反思,即當前層的 language-based gradient。這樣基于文本的反向傳播的方案使得該研究能夠得到一個包含多個節點和復雜 workflow 的智能體中每一節點 / 層的參數的梯度,也就可以直接優化每一個 prompt 和 tool 對整個智能體性能的作用,從而實現 end-to-end 的 joint optimization。
最后,得到了每組參數的 language-based gradient 之后,框架中使用基于大模型的 optimizer,使用精心設計的 prompt,以每一層的提示詞和工具調用,以及基于文本的梯度作為輸入,輸出優化過后的 prompts 和 tools,從而實現對智能體參數的更新。
除此之外,框架中還支持了對網絡結構,即 agent workflow 的優化。具體來說,框架中將 agent workflow 以特定的編程語言進行表示,這樣就將智能體網絡的 “計算圖” 也處理成了符號化的權重。之后通過一個單獨設計的基于大模型的優化器,以當前智能體的工作流和工作流中的各個節點的文本形式的梯度為輸入來對智能體的工作流進行更新。這在神經網絡中訓練中可以類比自動網絡結構搜索相關的研究。

圖 2: Agent Symbolic Learning 算法流程

圖 3 大模型評測任務上的實驗結果

圖 4 智能體級別評測任務的實驗結果
波形智能的研究人員在大模型和智能體的一系列 benchmark 上對該算法進行了評估,如圖 3 和圖 4 所示,agent symbolic learning 相比 DSpy 和傳統的沒有學習能力的智能體框架相比,在各類任務上都有了明顯的提升,在一些任務上甚至使用 GPT-3.5 也能和其他智能體框架使用 GPT-4 的表現類似。而簡單的對智能體中每一個節點中的提示詞使用局部的基于大語言模型的提示詞自動優化算法 (AutoPE) 則無法取得很明顯的效果。另外,如圖 5 所示,該算法在創意寫作任務中,從初始的只基于一個提示詞進行寫作的單節點智能體,自主進化到了支持寫作 + 編輯的工作流,并且將寫作節點的提示詞進行了更新和優化。

圖 5 Agent Symbolic Learning 框架學習效果展示 (以創意寫作任務為例)
波形智能的研究團隊介紹了 Agent Symbolic Learning 的兩種應用場景。首先,該框架可以用于開發者或研究人員創建和調優智能體系統中。像神經網絡的訓練一樣,開發者和研究人員可以對指定的任務收集(或者使用框架中提供的自動生成)大量的樣本,之后使用該框架在大量數據上完成 “data-centric” 的智能體的訓練和優化,在之后像普通智能體的部署一樣,在產品生產環境中以靜態的方式部署優化過后的智能體。
除此之外,該框架的另一個重要應用場景是支持能夠在環境 / 交互中自主進化的 Agent。具體來說,因為該訓練框架本身只需要調用大模型的能力而不需要復雜的基于 GPU 的訓練和部署,因此一個 Agent 可以將該訓練框架作為其自身可以調用的一個工具,通過在環境中探索或者和人類進行交互的過程中,不斷收集新的訓練樣本,定期或者主動調用智能體訓練的算法工具,對自身的 prompts, tools, 和 workflow 進行更新。波形智能在 AIWaves Agents 的開源代碼庫中也支持了這樣的部署邏輯,實現了首個可以在被部署到實際產品和生產環境中之后,依然可以不斷自主進化、自我迭代的智能體系統。
Agent Symbolic Learning 框架將 AI Agent 視作由復雜 workflow 中的 prompts 和 tools 連接而成的符號化 “神經網絡”,通過基于自然語言模擬反向傳播和梯度下降,使得基于大模型的智能體可以自主對自身的 “網絡參數”,即 prompts 和 tools,以及 “網絡結構”,即 agent workflow,進行優化,從而實現了能夠高效利用大量數據和經驗,進行 “data-centric learning” 的智能體框架,讓能夠持續自主進化的智能體系統變成了可能。目前,該框架已經在波形智能的多個產品和應用中發揮作用,解決了 Agent 人工優化和評測困難的問題。為了推進 “Data-centric Agent” 和 “Agent Learning” 的發展和研究,波形智能的研究團隊也將算法的全部代碼開源,期待智能體領域學術界和工業界一起探索更多更有趣的算法和應用。























