













教AI Agents學會協作&競爭!首個大模型多智能體框架CAMEL已斬獲3.6k星
「什么神奇的技巧讓我們變得智能?竅門就是沒有竅門。智慧的力量源于我們巨大的多樣性,而不是任何單一的、完美的原則。」
——人工智能先驅 馬文·明斯基(Marvin Minsky)
目前來看,在機器通向高級智能的道路上,以ChatGPT為代表的大模型(LLMs)應該是必須經過的里程碑之一,它們以聊天對話的人機交互方式在多個領域的復雜任務解決方面取得了非常耀眼的成就。
隨著LLMs的發展,AI Agents(AI智能體)之間的交互框架也逐漸興起,尤其是在一些復雜的專業領域,以角色扮演等模式預置的智能體完全有能力代替人類用戶在任務中扮演的角色,同時,智能體之間通過以協作和競爭形式的動態交互往往能夠帶來意想不到的效果,這就是被OpenAI人工智能專家Andrej Karpathy等人看作是「通向AGI最重要的前沿研究方向」的AI Agents。

該領域發展的時間線如下[2]:
- 「CAMEL」(駱駝:大模型心智交互框架)- 發布于2023.3.21
- 「AutoGPT」 - 發布于2023.3.30
- 「BabyGPT」 - 發布于2023.4.3
- 「Westworld」 simulation(斯坦福西部世界小鎮) — 發布于2023.4.7
作為最早基于ChatGPT的autonomous agents知名項目,KAUST研究團隊的大模型心智交互CAMEL框架(駱駝)重點探索了一種稱為角色扮演(role-playing)的新型合作代理框架,該框架可以有效緩解智能體對話過程中出現的錯誤現象,從而有效引導智能體完成各種復雜的任務,人類用戶只需要輸入一個初步的想法就可以啟動整個過程。目前,CAMEL已經被國際人工智能頂級會議NeurIPS 2023錄用。

論文鏈接:https://ghli.org/camel.pdf
項目主頁:https://www.camel-ai.org/
AI Agents是當下大模型領域備受關注的話題,用戶可以引入多個扮演不同角色的LLM Agents參與到實際的任務中,Agents之間會進行競爭和協作等多種形式的動態交互,進而產生驚人的群體智能效果。

作者對CAMEL框架設計了靈活的模塊化功能,包括不同代理的實現、各種專業領域的提示示例和AI數據探索框架等,因此CAMEL可以作為一個基礎的Agents后端,支持AI研究者和開發者更加輕松地開發有關于多智能體系統、合作人工智能、博弈論模擬、社會分析、人工智能倫理等方面的應用。
具體的,作者通過涉及兩種角色扮演的合作場景,生成了兩個大型的指令數據集AI Society和AI Code,以及兩個單輪問答數據集AI Math和AI Science,用于探索LLM涌現能力的研究。
CAMEL框架
下圖展示了CAMEL中的role-playing框架,人類用戶需要首先制定一個想要實現的想法或目標,例如:開發一個用于股市場的交易機器人。
這項任務涉及的角色是AI助理智能體(使其扮演Python程序員角色)和AI用戶智能體。
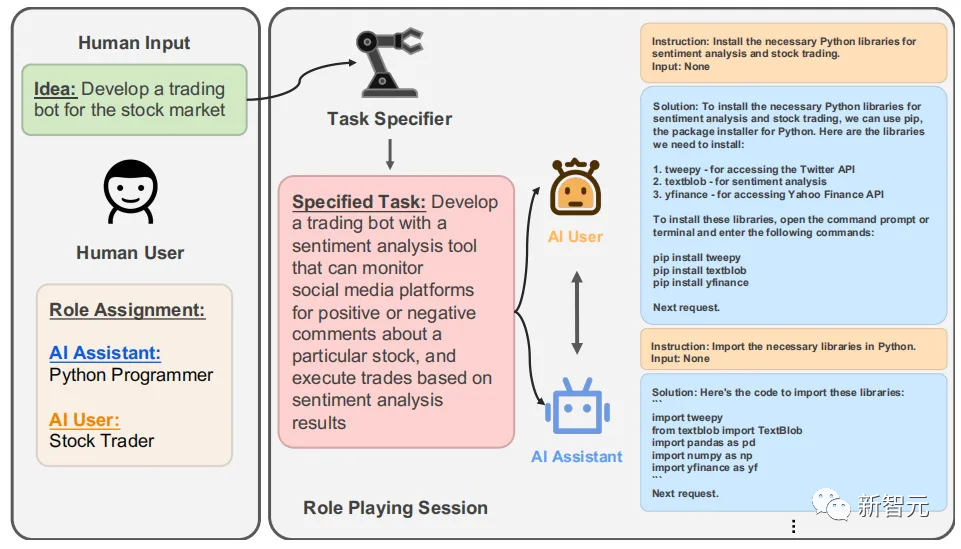
作者首先為CAMEL設置了一個任務細化器(Task Specifier),該細化器會根據輸入的想法來制定一個較為詳細的實現步驟,隨后AI助理智能體(AI Assistant)和AI用戶智能體(AI User)通過聊天的方式來進行協作通信,各自一步步完成指定的任務。
其中協作通信通過系統級的消息傳遞機制來實現,令 為傳遞給AI助理智能體的系統消息,
為傳遞給AI用戶智能體的系統消息。
隨后為AI助理智能體和AI用戶智能體分別實例化為兩個ChatGPT模型 和
,相應得到AI助理智能體
和AI用戶智能體
。
角色分配完成后,AI助理智能體和AI用戶智能體會按照指令跟隨的方式協作完成任務,令 為時間
時刻獲得的用戶指令消息,
為AI助理智能體給出的解決方案,因而
時刻得到的對話消息集為:

在下一個時刻 ,AI用戶智能體
會根據歷史對話消息集
,來生成新的指令
。然后再將新指令消息與歷史對話消息集一起傳遞給AI助理智能體
來生成新一時刻的解決方案:

CAMEL使用示例
1. 協作角色扮演(cooperate role-playing)
CAMEL內置的協作式role-playing框架可以在人類用戶不具備專業知識的情況下,通過Agents之間的協作方式完成復雜任務,下圖展示了CAMEL開發股市場交易機器人的例子,其中AI助理智能體的扮演的角色是一名Python程序員,而AI用戶智能體扮演的角色為一名股交易員。

在role-playing框架中,AI智能體都具有特定領域的專業知識,此時我們只需要指定一個原始想法的Prompt,隨后兩個AI智能體就會圍繞著這一想法展開工作,在上圖中,用戶智能體提出交易機器人需要有對股評論的情緒分析功能,隨后助理智能體直接給出了安裝情緒分析和股交易所需的python庫的腳本。

隨著任務的進行,用戶智能體給出的指示也會越來越明確,上圖中的指示為:定義一個函數以使用Yahoo Finance API獲取特定股的最新股價。助理智能體會根據該指示直接生成一段代碼來解決需求。
2. 具身智能體(embodied agent)
在先前的研究中,AI Agents可以理解為在模擬一些操作,而沒有與現實世界交互或使用外部工具執行操作,目前的LLMs已經具備與互聯網或其他工具API交互的能力,CAMEL也提供了能夠在物理世界中執行各種操作的具身智能體(embodied agent),它們可以瀏覽互聯網、閱讀文檔、創建圖像、音頻和視頻等內容,甚至可以直接執行代碼。

上圖展示了CAMEL通過使用embodied agent調用HuggingFace提供的Stable Diffusion工具鏈生成駱駝科圖像的樣例,在這一過程中,embodied agent首先會推理出駱駝科所包含的所有動物,隨后調用擴散模型生成圖像并進行保存。
3. critic在環(critic-in-the-loop)
為了增強role-playing框架的可控性,作者團隊還為CAMEL設計了一種critic-in-the-loop,這種機制受到了蒙特卡洛樹搜索(MTCS)方法的啟發,它可以結合人類偏好實現樹搜索的決策邏輯來解決任務,CAMEL可以設置一個中間評價智能體(critic)來根據用戶智能體和助理智能體出的各種觀點進行決策來完成最終任務,整體流程如下圖所示。

考慮這樣一個場景,我們讓CAMEL主持一場很具體的科研項目討論會,而科研項目的主題「大型語言模型」,CAMEL可以將用戶智能體的角色設置為一個博士后,將助理智能體的角色設置為博士生,而中間評價智能體的角色設置為教授。任務指示博士生來幫助博士后制定研究計劃,需要圍繞大模型的倫理展開研究。

在接到任務后,博士后智能體首先拋出了關于這一項目的三個觀點,表明項目應該首先從調研大模型倫理方面的相關工作著手。
隨后教授智能體會根據這三個觀點給出自己的看法。并且認為觀點2最為合理的,即研究大模型歧視性算法。同時還會給出另外兩個觀點的缺陷,例如觀點1缺乏更加清晰的結構,觀點3的研究范圍太窄等等。

在教授發言之后,博士生智能體會進行更加具體的項目規劃,例如直接列出一些大模型倫理安全方向的相關文獻,并且討論如何開展具體的研究。
實驗效果
本文的性能評估主要從三個方面進行,并且采用兩個gpt-3.5-turbo作為實驗智能體,實驗的數據集使用CAMEL框架生成的四個AI數據集,其中AI Society和AI Code側重于智能體的對話效果,而AI Math和AI Science側重于智能體的問題解決能力。
1. Agent評估
在這一部分,作者從AI Society和AI Code數據集中分別隨機選擇 100 個任務進行評估,然后使用CAMEL框架和單個gpt-3.5-turbo進行對比實驗。
結果評估方面分為兩部分,一方面由人類受試者對兩種方法給出的解決方案給出453份投票數據,來決定哪種方案更加可行。另一方面,作者提示GPT4模型對兩種方案直接給出評分,具體的對比數據如下表所示。

從上表中可以看出,CAMEL框架給出的解決方案在人類評估和GPT4評估中均大幅優于gpt-3.5-turbo給出的解決方案,其中人類評估和GPT4評估的總體趨勢高度一致。
2. 使用GPT-4對ChatBot評估
在這一部分,作者在CAMEL生成的四個數據集上對LLaMA-7B模型進行了逐步的微調,通過向LLM中不斷注入來自社會、代碼、數學和科學等不同領域的知識,來觀察模型對知識發現的接受效果。
作者首先從AI Society數據集開始,讓模型了解人類的互動常識和社會動態,隨后AI Code和其他數據集的注入,模型獲得了編程邏輯和語法的知識,同時拓寬了模型對科學理論、經驗觀察和實驗方法的理解。
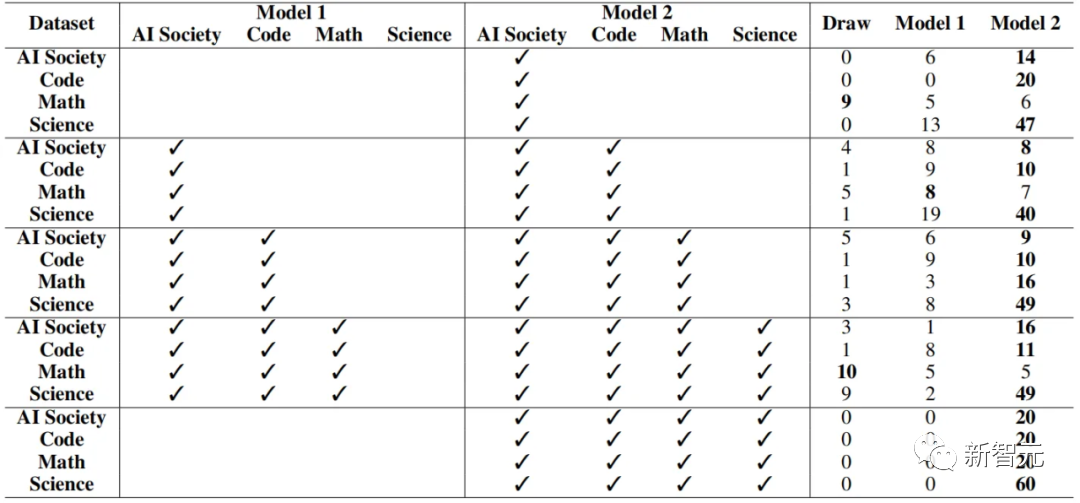
上表展示了模型在20個Society任務、20個代碼編寫任務、20個數學任務和60個科學任務上的測試效果,可以看到在每次添加數據集時,模型在已訓練過的任務域上都會表現得更好。
3. HumanEval
為了進一步評估CAMEL框架的代碼編寫任務解決能力,作者在HumanEval和HumanEval+兩個評估基準上進行了實驗,實驗結果如下表所示。

上表中清楚地證明了CAMEL框架的卓越性能,它不僅遠遠超過了LLaMA-7B模型,而且還大大超過了Vicuna-7B模型,這表明使用CAMEL生成的數據集在增強LLM處理編碼相關任務方面有獨特的效果。
CAMEL AI開源社區
值得一提的是,CAMEL作者團隊正在構建了一個非常完善的CAMEL AI開源社區,社區Github倉庫已經得到了3600+的star數,社區中涵蓋了CAMEL中各種智能體的實現、數據生成pipeline、數據分析工具和已生成的數據集,以支持AI Agents及其他方面的研究,社區目前已吸引了諸多開源愛好者貢獻代碼。
距離CAMEL項目編寫第一行代碼到現在已有9個月,CAMEL-AI.org開源研究技術社區已經吸引超過20名來自KAUST/劍橋/索邦大學/NUS/CMU/芝加哥大學/斯坦福/杜克大學/北大/上交/哈工大/西電/東北大學/成信大以及工業界等獨立代碼貢獻者。
社區正在尋找全職/兼職/實習貢獻者、工程師和研究人員加入一起學習和探索如何推動構建智能體社會的邊界,杰出貢獻者有機會參與框架和其他研究項目論文的撰寫投稿。


如果感興趣加入CAMEL-AI.org的社區,可以將簡歷發送至camel.ai.team@gmail.com或者添加微信號CamelAIOrg進行咨詢!




























