













首個國產開源MoE大模型來了!性能媲美Llama 2-7B,計算量降低60%
開源MoE模型,終于迎來首位國產選手!
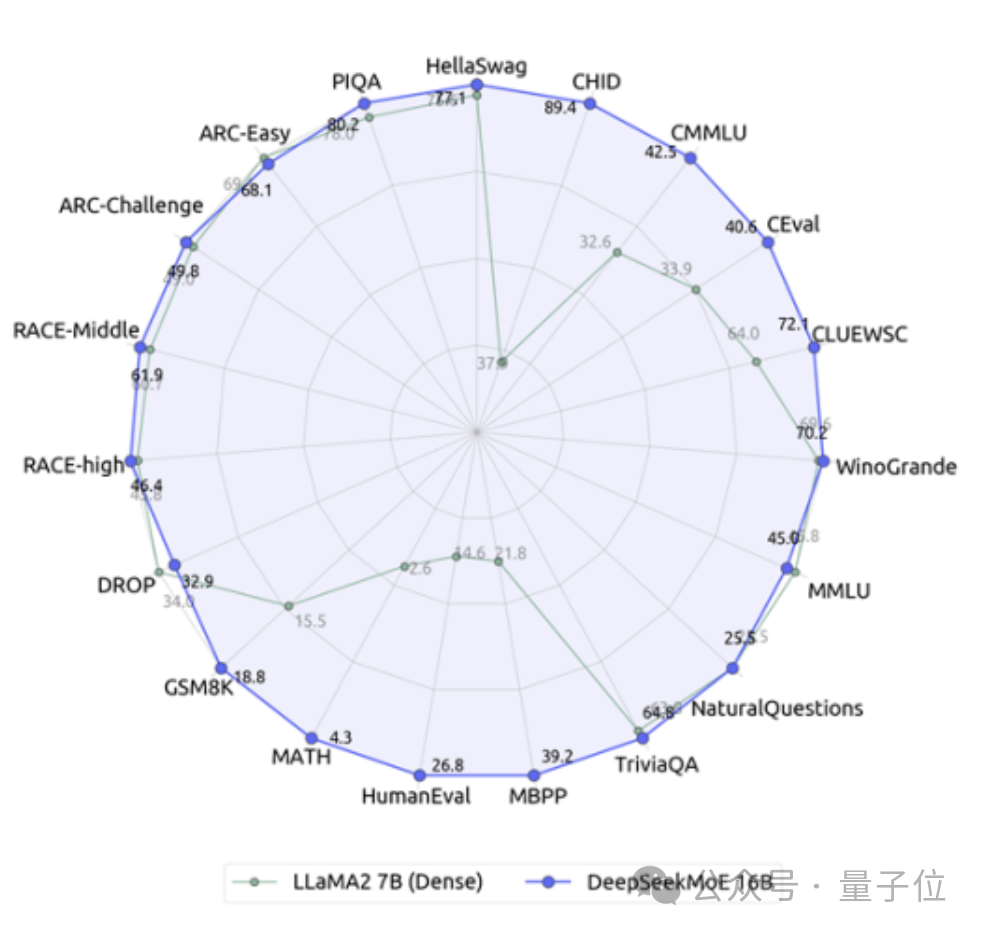
它的表現完全不輸給密集的Llama 2-7B模型,計算量卻僅有40%。
這個模型堪稱19邊形戰士,特別是在數學和代碼能力上對Llama形成了碾壓。
它就是深度求索團隊最新開源的160億參數專家模型DeepSeek MoE。
除了性能上表現優異,DeepSeek MoE主打的就是節約計算量。
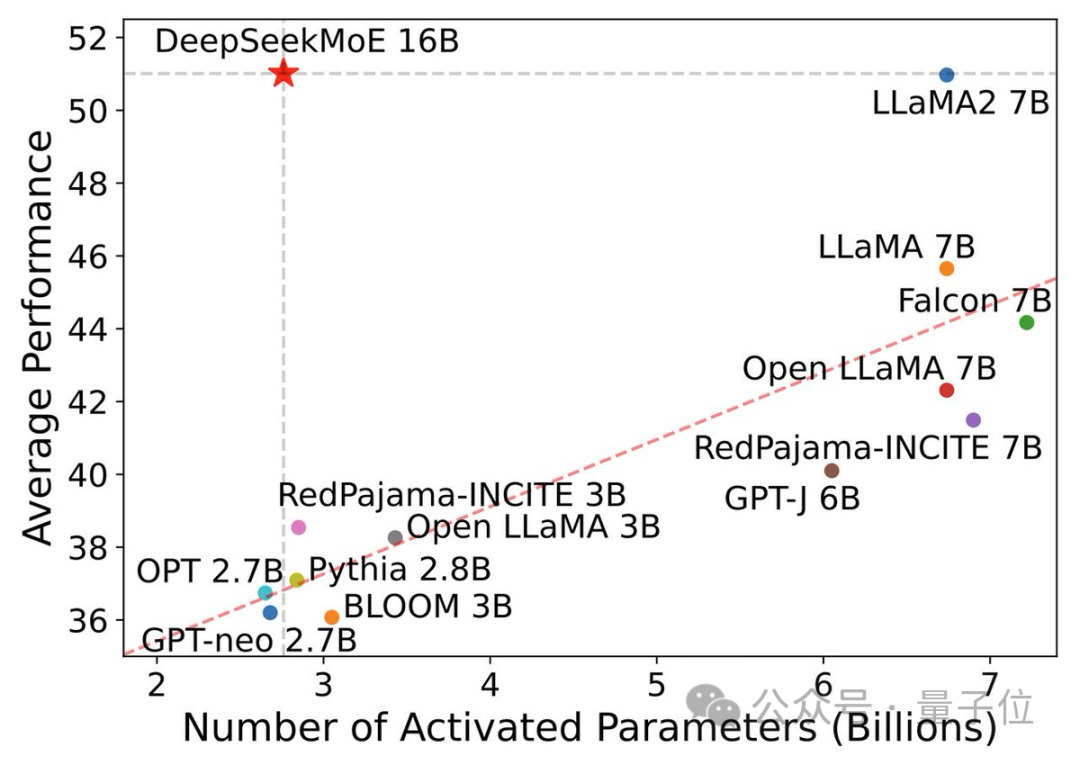
在這張表現-激活參數量圖中,它“一枝獨秀”地占據了左上角的大片空白區。
發布僅一天,DeepSeek團隊在X上的推文就有大量轉發關注。

JP摩根的機器學習工程師Maxime Labonne測試后也表示,DeepSeek MoE的chat版本表現要略勝于微軟的“小模型”Phi-2。

同時,DeepSeek MoE還在GitHub上獲得了300+星標,并登上了Hugging Face文本生成類模型排行榜的首頁。

那么,DeepSeek MoE的具體表現究竟怎么樣呢?
計算量減少60%
DeepSeek MoE目前推出的版本參數量為160億,實際激活參數量大約是28億。
與自家的7B密集模型相比,二者在19個數據集上的表現各有勝負,但整體比較接近。
而與同為密集模型的Llama 2-7B相比,DeepSeek MoE在數學、代碼等方面還體現出來明顯的優勢。
但兩種密集模型的計算量都超過了180TFLOPs每4k token,DeepSeek MoE卻只有74.4TFLOPs,只有兩者的40%。

在20億參數量時進行的性能測試顯示,DeepSeek MoE同樣能以更少的計算量,達到與1.5倍參數量、同為MoE模型的GShard 2.8B相當甚至更好的效果。

此外深度求索團隊還基于SFT微調除了DeepSeek MoE的Chat版本,表現同樣接近自家密集版本和Llama 2-7B。

此外,深度求索團隊還透露,DeepSeek MoE模型還有145B版本正在研發。
階段性的初步試驗顯示,145B的DeepSeek MoE對GShard 137B具有極大的領先優勢,同時能夠以28.5%的計算量達到與密集版DeepSeek 67B模型相當的性能。
研發完畢后,團隊也將對145B版本進行開源。

而在這些模型表現的背后,是DeepSeek全新的自研MoE架構。
自研MoE新架構
首先是相比于傳統的MoE架構,DeepSeek擁有更細粒度專家劃分。
在總參數量一定的情況下,傳統模型分出N個專家,而DeepSeek可能分出2N個。
同時,每次執行任務時選擇的專家數量也是傳統模型的2倍,所以總體使用的參數量也不變,但選擇的自由度增加了。
這種分割策略允許更靈活和適應性的激活專家組合,從而提高了模型在不同任務上的準確性和知識獲取的針對性。

除了專家劃分上的差異,DeepSeek還創新性地引入了“共享專家”的設置。
這些共享專家對所有輸入的token激活,不受路由模塊影響,目的是捕獲和整合在不同上下文中都需要的共同知識。
通過將這些共享知識壓縮到共享專家中,可以減少其他專家之間的參數冗余,從而提高模型的參數效率。
共享專家的設置有助于其他專家更加專注于其獨特的知識領域,從而提高整體的專家專業化水平。

消融實驗結果表明,這兩個方案都為DeepSeek MoE的“降本增效”起到了重要作用。

論文地址:https://arxiv.org/abs/2401.06066。
參考鏈接:https://mp.weixin.qq.com/s/T9-EGxYuHcGQgXArLXGbgg。





























