英偉達開源NVLM 1.0屠榜多模態!純文本性能不降反升
文本大模型經過多年的發展,逐漸發展成了統一的純解碼器Transformer架構。
反觀現有的多模態大模型架構仍然處于混亂狀態,開源模型在選擇LLM主干、視覺編碼器以及訓練數據方面都存在差異,性能優異的閉源多模態大模型也沒有公布相關信息,無法直接進行模型對比和研究。
并且,不同模型在處理高分辨率圖像輸入時的設計(如動態高分辨率)雖然可以提高了與OCR相關的任務(例如,OCRBench)的性能,但與低分辨率版本模型相比,在推理相關任務(例如,MMMU)上的準確率卻會下降。
此外,雖然開源的多模態大模型在視覺-語言任務上取得了非常亮眼的基準測試結果,但在純文本任務上的性能卻有顯著下降,與領先的閉源模型(如GPT-4o)的表現并不一致。
為了改變這一現狀,英偉達的研究團隊最近宣布推出NVLM 1.0,在視覺-語言任務上取得了最先進的成果,能夠與最強大的閉源模型(如GPT-4o)和開源模型(如Llama 3-V 405B和InternVL 2)相媲美,并且在多模態訓練后,其文本性能甚至超過了所采用的LLM主干模型。

論文鏈接:https://arxiv.org/pdf/2409.11402
項目主頁:https://nvlm-project.github.io/
在模型設計方面,研究人員對純解碼器多模態大模型(如LLaVA)和基于交叉注意力的模型(如Flamingo)進行了全面對比,并根據總結出的優勢和劣勢,提出了一種全新架構,提升了模型的訓練效率和多模態推理能力。
文中還引入了一種1-D圖塊(tile)標簽設計,可用于基于tile的動態高分辨率圖像,能夠顯著提高多模態推理和與OCR相關任務的性能。

在訓練數據方面,研究人員在文中詳細介紹了多模態預訓練和監督微調數據集的詳細信息,結果表明,數據集的質量和任務多樣性比規模更重要,對所有的架構來說都是如此。
值得注意的是,研究人員將高質量的純文本數據集精心整合到多模態訓練中,并輔以大量的多模態數學和推理數據,從而在各個模態上增強了數學和編碼能力,使其在視覺-語言任務上表現出色的同時,保持甚至提高了純文本性能。
NVLM 1.0模型架構
NVLM-1.0包括三種可選架構:
1. 僅解碼器的NVLM-D
2. 基于Cross (X)-attention的NVLM-X
3. 采用混合架構的NVLM-H

1. 共享視覺路徑(Shared Vision Pathway)
研究人員使用單一的、大型的、表現優異的視覺編碼器InternViT-6B-448px-V1-5作為默認選項,在所有訓練階段都保持凍結狀態,以固定的分辨率448×448處理圖像,生成1024個輸出token,在訓練中最多6個圖塊(tiles),預定義的寬高比為{1:1, 1:2, 1:3, 1:4, 1:5, 1:6, 2:1, 2:2, 2:3, 3:1, 3:2, 4:1, 5:1, 6:1},覆蓋了所有可能情況。

然后執行下采樣(downsampling)操作,沿著通道維度將1024個圖像token減少到256個,將四個相鄰的圖像token組合成一個,以節省LLM處理開銷。
動態高分辨率(DHR)設計顯著提高了與OCR相關的任務性能,但當所有tile的圖像token直連輸入到LLM時,有時會導致推理相關任務的性能下降,研究人員在三種架構中分別解決該問題。
2. NVLM-D:純解碼器模型
NVLM-D模型使用一個2層多層感知器(MLP)作為投影器(projector)或模態對齊(modality-alignment)模塊,將預訓練視覺編碼器連接到大型語言模型。

NVLM-D的訓練包括兩個階段:預訓練和有監督微調(SFT),其中MLP是隨機初始化的,需要先進行預訓練,同時保持視覺編碼器和LLM主干凍結。
在探索過程中,研究人員發現當視覺編碼器相對較弱(如ViT-L/14)且預訓練數據集足夠多樣化時,MLP投影器和視覺編碼器的聯合預訓練是有益的;在升級到更強大的InternViT-6B-448px-V1-5后,性能增益變得微乎其微。
為了簡化,研究人員選擇在預訓練期間保持視覺編碼器凍結;在SFT階段,MLP投影器和LLM都需要訓練以學習帶有新指令的新視覺-語言任務,且保持視覺編碼器凍結。
以往文獻中很少討論的是,在多模態SFT訓練期間不凍結LLM權重通常會導致純文本性能顯著下降,NVLM-D模型通過整合高質量的純文本SFT數據集,有效地保持了純文本性能。
動態高分辨率的圖塊(tile)標簽
大型語言模型(LLM)的主干需要處理所有動態高分辨率tile的扁平圖像token,包括一個額外的縮略圖tile,如果不加分隔符可能在輸入LLM時產生歧義,因為語言模型沒有動態平鋪(dynamic tiling)過程的先驗知識。
為了解決這個問題,研究人員在輸入序列中插入一個基于文本的tile標簽以標記圖塊的開始以及在整個平鋪結構中的位置,然后在標簽后附加tile的256個圖像token,總共設計了三種標簽:
1)無標簽:無tile標簽直接連接,也是InternVL-1.5的設計。
2)1-D扁平化tile標簽:<tile_1>, <tile_2>, ..., <tile_6>, <tile_global>
3)2-D網格標簽:<tile_x0_y0>, <tile_x1_y0>, ..., <tile_xW_yH>, <tile_global>
4)2-D邊界框標簽:<box> (x0, y0), (x1, y1) </box>, ..., <box> (xW, yH), (xW+1, yH+1) </box>,其中兩個坐標分別為(左, 頂部),(右, 底部)。

從消融實驗結果中可以觀察到:
1)純粹的動態高分辨率方法(DHR + 無標簽)在所有基準測試中的性能都有顯著提高;
2)在LLM解碼器中插入其他類型的圖塊標簽,其性能顯著優于簡單的無標簽連接,還能極大改善與OCR相關任務的性能。
3)1-D瓦片標簽<tile_k>通常比其他標簽表現更好,雖然無法提供2-D信息(例如,2×3與3×2),但在測試階段具有更好的泛化能力。
3. NVLM-X:X-attention模型

NVLM-X使用門控交叉注意力來處理圖像token,與Flamingo模型不同的是:
1)感知器重采樣器對自然圖像描述是有益的,但對密集OCR任務會產生負面影響,主要是因為感知器中的交叉注意力到潛在數組混合了輸入圖像token,可能會破壞圖像塊之間的空間關系,而這些關系對于文檔OCR至關重要,所以NVLM-X完全依使用交叉注意力直接從視覺編碼器讀取圖像token
2)在多模態監督式微調(SFT)階段凍結大型語言模型(LLM)會損害視覺-語言任務的性能,因為模型需要快速適應在純文本指令調整期間未遇到的新任務和新指令;因此,在多模態SFT期間,研究人員解凍了NVLM-X的LLM主干,并混合了高質量的純文本SFT數據集,以保持強大的純文本性能。
NVLM-X的動態高分辨率圖塊標簽與NVLM-D相同,采用門控X-attention來處理每個圖塊的扁平化圖像token。

消融實驗中,使用低分辨率448×448輸入,動態高分辨率(DHR)無圖塊標簽和帶有1-D <tile_k>標簽的情況,可以發現:原始的動態高分辨率方法(DHR + 無標簽)在所有基準測試中都顯著優于其低分辨率對應結果;添加圖塊標簽在所有基準測試中都提高了性能,包括多模態推理和OCR相關的任務。
4. NVLM-H:混合模型
NVLM-H是一種混合架構,結合了NVLM-D和NVLM-X的優勢,將圖像token的處理分為兩條路徑:縮略圖token與文本token一起輸入到大型語言模型中,并由自注意力層處理,實現了聯合多模態推理。

同時,通過門控交叉注意力處理動態數量的常規圖塊(regular tile),使模型能夠捕捉更精細的圖像細節,相比NVLM-X增強了高分辨率能力,與NVLM-D相比顯著提高了計算效率,在訓練中的吞吐量高于NVLM-D

動態高分辨率的圖塊標簽
NVLM-H使用了與NVLM-D相同的1-D平展圖塊標簽<tile_k>,主要區別在于處理位置,<tile_k>的文本嵌入與視覺嵌入一起集成到門控交叉注意力層中,能夠在預訓練期間有效地對齊文本和視覺嵌入,使模型能夠在交叉注意力機制內無縫解釋圖塊標簽。
實驗結果
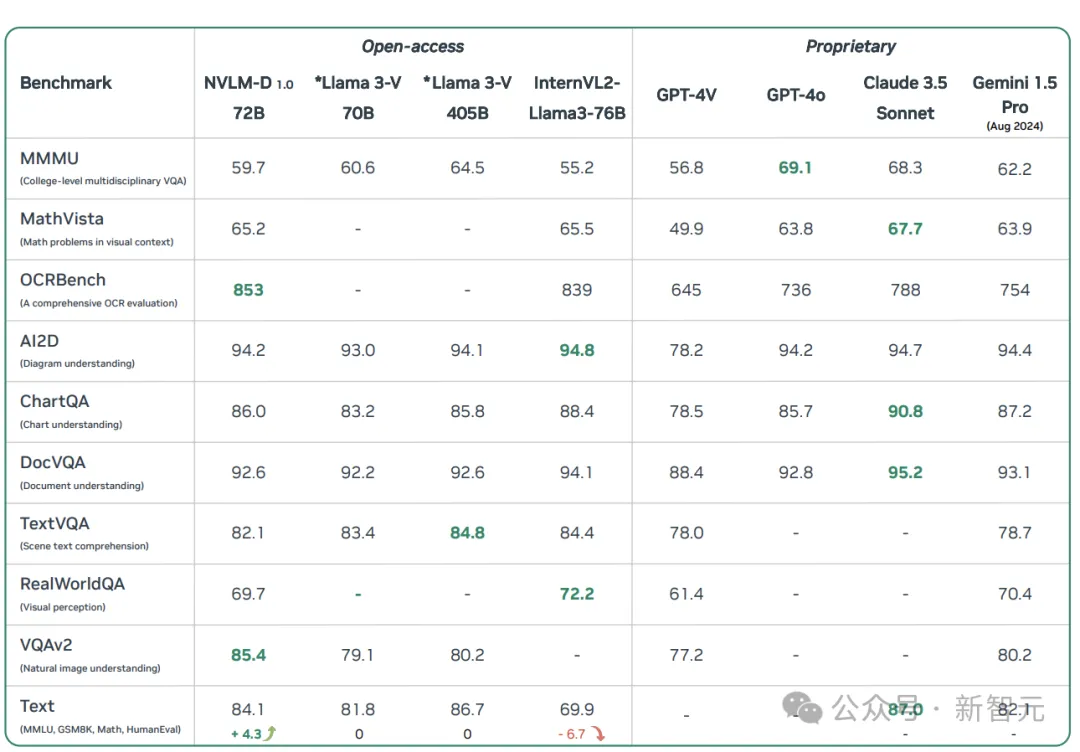
在九個視覺-語言基準測試和四個純文本基準測試上的結果顯示,NVLM-1.0 72B模型可以與其他最強的開源、閉源模型(例如,GPT-4o)相媲美,包括尚未公開可用的LLaMA 3V和InternVL 2

NVLM-D1.0 72B在OCRBench(853)和VQAv2(85.4)上取得了所有對比模型的最高分,其MMMU得分(59.7)也在本報告發布時顯著超過了所有開源模型,包括LLaVAOneVision 72B(56.8)和InternVL-2-Llama3-76B(55.2)。在AI2D、TextVQA、ChartQA和DocVQA上,其表現僅略遜于表現最佳的InternVL-2-Llama3-76B,與的GPT-4o相當,并顯著優于其他開源模型。
NVLM-H1.0 72B在所有開源多模態LLMs中取得了最高的MMMU(Val)得分(60.2),還在NVLM-1.0家族中取得了最佳的MathVista得分(66.6),已經超越了許多非常強大的模型,包括GPT-4o、Gemini Pro 1.5(2024年8月)、InternVL-2-Pro,證明了其卓越的多模態推理能力。
NVLM-X1.0 72B也取得了前沿級別的結果,并且作為同類中最佳的基于交叉注意力的多模態LLMs,能夠與尚未發布的Llama 3-V 70B相媲美。NVLM-X1.0還有一個優勢:訓練和推理速度更快。
開源的多模態大型語言模型,如LLaVA-OneVision 72B和InternVL-2-Llama3-76B,在多模態訓練后在純文本任務上表現出顯著的性能下降;相比之下,NVLM-1.0模型的純文本性能甚至略有提高,主要得益于包含了高質量的純文本監督式微調(SFT)數據,也表明,只要融入了高質量的文本對齊數據,在多模態SFT期間解凍LLM主干并不會損害文本性能。