Python讓數(shù)據(jù)處理更簡(jiǎn)單的九個(gè)代碼片段
在數(shù)據(jù)處理領(lǐng)域,Python憑借其豐富的庫(kù)和簡(jiǎn)潔的語(yǔ)法成為眾多開(kāi)發(fā)者的首選語(yǔ)言。無(wú)論是數(shù)據(jù)清洗、統(tǒng)計(jì)分析還是復(fù)雜的數(shù)據(jù)處理任務(wù),Python都能提供高效的解決方案。本文將介紹九個(gè)實(shí)用的Python技巧,幫助你簡(jiǎn)化日常的數(shù)據(jù)處理工作。

1. 使用列表推導(dǎo)式快速處理數(shù)據(jù)
列表推導(dǎo)式是Python中一種非常強(qiáng)大的工具,它允許我們以簡(jiǎn)潔的方式創(chuàng)建新的列表。相比于傳統(tǒng)的循環(huán)結(jié)構(gòu),列表推導(dǎo)式的語(yǔ)法更加簡(jiǎn)潔,同時(shí)執(zhí)行效率也更高。
示例:假設(shè)我們需要從一個(gè)數(shù)字列表中篩選出所有的偶數(shù)。
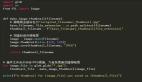
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
even_numbers = [num for num in numbers if num % 2 == 0] # 列表推導(dǎo)式
print(even_numbers) # 輸出: [2, 4, 6, 8, 10]這里的[num for num in numbers if num % 2 == 0]就是列表推導(dǎo)式的語(yǔ)法結(jié)構(gòu),它可以讀作“從numbers中選擇所有能夠被2整除的元素,并將它們放入新列表中”。
2. 利用Pandas庫(kù)進(jìn)行高效的數(shù)據(jù)清洗
Pandas是一個(gè)非常流行的Python數(shù)據(jù)分析庫(kù),它提供了大量用于操作表格數(shù)據(jù)的功能。當(dāng)涉及到數(shù)據(jù)清洗時(shí),Pandas簡(jiǎn)直是神器般的存在。
示例:去除DataFrame中的重復(fù)行。
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie', 'Alice'],
'Age': [25, 30, 35, 25]}
df = pd.DataFrame(data)
# 去重
df_unique = df.drop_duplicates()
print(df_unique)運(yùn)行上述代碼后,你會(huì)得到一個(gè)沒(méi)有重復(fù)記錄的新DataFrame:
Name Age
0 Alice 25
1 Bob 30
2 Charlie 353. 使用NumPy進(jìn)行高效的數(shù)組運(yùn)算
NumPy是Python科學(xué)計(jì)算的基礎(chǔ)包之一,它支持大量的多維數(shù)組(矩陣)和向量代數(shù)運(yùn)算。對(duì)于那些需要頻繁處理數(shù)值型數(shù)據(jù)的朋友來(lái)說(shuō),NumPy絕對(duì)是不二之選。
示例:計(jì)算兩個(gè)數(shù)組之間的歐幾里得距離。
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
distance = np.linalg.norm(a - b)
print(distance) # 輸出: 5.196152422706632這里,np.linalg.norm()函數(shù)計(jì)算了兩個(gè)向量之間的歐氏距離。這個(gè)距離可以用來(lái)衡量?jī)山M數(shù)據(jù)之間的相似度。
4. 字典推導(dǎo)式輕松完成數(shù)據(jù)映射
除了列表推導(dǎo)式之外,Python還支持字典推導(dǎo)式,這使得我們可以非常方便地創(chuàng)建或修改字典。
示例:根據(jù)給定的鍵值對(duì)創(chuàng)建一個(gè)新的字典。
keys = ['a', 'b', 'c']
values = [1, 2, 3]
mapped_dict = {key: value for key, value in zip(keys, values)}
print(mapped_dict) # 輸出: {'a': 1, 'b': 2, 'c': 3}{key: value for key, value in zip(keys, values)}就是字典推導(dǎo)式的語(yǔ)法形式,它表示“將keys和values中的對(duì)應(yīng)元素作為鍵值對(duì)添加到新字典中”。
5. 運(yùn)用集合(set)快速找出兩組數(shù)據(jù)的交集
集合是Python內(nèi)置的一種數(shù)據(jù)類(lèi)型,它不允許包含重復(fù)元素,并且支持一些數(shù)學(xué)上的集合操作,如并集、交集等。
示例:找出兩個(gè)列表的公共元素。
list1 = [1, 2, 3, 4, 5]
list2 = [4, 5, 6, 7, 8]
common_elements = set(list1).intersection(set(list2))
print(common_elements) # 輸出: {4, 5}通過(guò)調(diào)用set().intersection()方法,我們輕松地找到了兩個(gè)列表中的共有項(xiàng)。這種方法比傳統(tǒng)的雙重循環(huán)檢查方式要高效得多。
6. 使用生成器表達(dá)式節(jié)省內(nèi)存
生成器表達(dá)式類(lèi)似于列表推導(dǎo)式,但它返回的是一個(gè)生成器對(duì)象,而不是一個(gè)列表。這意味著生成器表達(dá)式只會(huì)在需要的時(shí)候生成數(shù)據(jù),從而大大節(jié)省內(nèi)存。
示例:創(chuàng)建一個(gè)生成器表達(dá)式來(lái)計(jì)算平方數(shù)。
squares = (x ** 2 for x in range(10))
for square in squares:
print(square, end=' ')輸出:
0 1 4 9 16 25 36 49 64 81在這個(gè)例子中,(x ** 2 for x in range(10))是一個(gè)生成器表達(dá)式。它會(huì)按需生成每個(gè)平方數(shù),而不是一次性生成整個(gè)列表。這樣可以顯著減少內(nèi)存消耗。
7. 使用正則表達(dá)式進(jìn)行復(fù)雜的字符串匹配
正則表達(dá)式是一種強(qiáng)大的文本處理工具,可以用來(lái)搜索、替換和解析字符串。Python中的re模塊提供了豐富的正則表達(dá)式功能。
示例:提取字符串中的電子郵件地址。
import re
text = "Hello, my email is example@example.com and my phone number is +1234567890."
# 匹配電子郵件地址
email_pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
emails = re.findall(email_pattern, text)
print(emails) # 輸出: ['example@example.com']
# 匹配電話(huà)號(hào)碼
phone_pattern = r'\+\d{10}'
phones = re.findall(phone_pattern, text)
print(phones) # 輸出: ['+1234567890']這里,re.findall()函數(shù)用于查找所有匹配指定模式的子串。r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b' 是一個(gè)正則表達(dá)式,用于匹配電子郵件地址。同樣,r'\+\d{10}' 用于匹配電話(huà)號(hào)碼。
8. 使用字典的方法進(jìn)行高效的數(shù)據(jù)統(tǒng)計(jì)
字典提供了許多有用的方法,可以幫助我們快速完成數(shù)據(jù)統(tǒng)計(jì)任務(wù)。例如,collections.Counter類(lèi)可以方便地統(tǒng)計(jì)元素出現(xiàn)的次數(shù)。
示例:統(tǒng)計(jì)列表中各個(gè)元素出現(xiàn)的次數(shù)。
from collections import Counter
fruits = ['apple', 'banana', 'apple', 'orange', 'banana', 'banana']
fruit_counts = Counter(fruits)
print(fruit_counts) # 輸出: Counter({'banana': 3, 'apple': 2, 'orange': 1})Counter(fruits) 創(chuàng)建了一個(gè)計(jì)數(shù)器對(duì)象,其中包含了每個(gè)元素及其出現(xiàn)的次數(shù)。這種方法比手動(dòng)編寫(xiě)循環(huán)統(tǒng)計(jì)要簡(jiǎn)單得多。
9. 使用Pandas進(jìn)行數(shù)據(jù)聚合與分組
Pandas不僅支持基本的數(shù)據(jù)清洗,還可以進(jìn)行復(fù)雜的數(shù)據(jù)聚合和分組操作。這對(duì)于分析大規(guī)模數(shù)據(jù)集非常有幫助。
示例:根據(jù)性別分組計(jì)算平均年齡。
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie', 'Alice', 'Bob'],
'Gender': ['F', 'M', 'M', 'F', 'M'],
'Age': [25, 30, 35, 25, 30]}
df = pd.DataFrame(data)
# 分組并計(jì)算平均年齡
grouped = df.groupby('Gender')['Age'].mean()
print(grouped)輸出:
Gender
F 25.0
M 31.7
Name: Age, dtype: float64這里,df.groupby('Gender')['Age'].mean() 將數(shù)據(jù)按照性別分組,并計(jì)算每個(gè)性別下的平均年齡。這種方法非常適合進(jìn)行數(shù)據(jù)分析和報(bào)告生成。
總結(jié)
本文介紹了九個(gè)實(shí)用的Python技巧,涵蓋了列表推導(dǎo)式、Pandas庫(kù)、NumPy、字典推導(dǎo)式、集合操作、生成器表達(dá)式、正則表達(dá)式、字典統(tǒng)計(jì)以及Pandas的數(shù)據(jù)聚合。通過(guò)這些技巧的應(yīng)用,你可以更高效地處理各種數(shù)據(jù)問(wèn)題。希望這些內(nèi)容能幫助你在日常工作中提升效率。