













招行一面:什么是分布式緩存?它是如何工作的?
在日常開發中,我們經常會使用到緩存,當數據集較小時,通常將所有緩存數據保存在一臺服務器上就足夠了,但是當數據集較大時,我們需要將緩存數據分布在多個服務器上,這樣就產生了分布式緩存。這篇文章,我們將詳細探討分布式緩存。

一、什么是分布式緩存?
分布式緩存是指分布在多個服務器上的緩存。與本地緩存不同,分布式緩存通常部署在獨立的應用進程中,并與應用進程部署在不同的機器上。因此,數據讀寫操作需要通過網絡來完成。分布式緩存的主要特點包括:
- 可擴展性:當應用程序需要處理大量數據或高并發請求時,可以通過增加服務器節點來擴展分布式緩存的容量和提高性能。
- 數據一致性:分布式緩存的數據一致性可以通過各種技術實現,如緩存同步、分布式鎖等。
- 獨立部署:分布式緩存通常部署在獨立的應用進程中,與應用程序分離,多個應用可以直接共享緩存。
分布式緩存會以元數據服務作為服務發現:客戶端會把自身監聽的IP和端口匯報給元數據服務,也會從元數據服務獲取同一個緩存組內的其他成員的連接方式,進而發現其它客戶端,并通過節點間通信來共享緩存。

二、分布式緩存的組成部分
一個分布式緩存系統通常包括以下組成部分:
- 緩存節點:這些是存儲緩存數據的各個服務器。每個節點都是整體緩存集群的一部分。
- 客戶端庫/緩存客戶端:應用程序使用客戶端庫與分布式緩存通信。這個庫處理連接緩存節點、分布數據和檢索緩存數據的邏輯。
- 一致性哈希:這種方法將數據均勻地分布在緩存節點上。它確保添加或刪除節點對系統的影響最小。
- 復制:為了使系統更可靠,一些分布式緩存會在多個節點上復制數據。如果一個節點宕機,數據仍然可以在另一個節點上獲取。
- 分片:數據被分成分片,每個分片存儲在不同的緩存節點上。它有助于均勻分布數據,并允許緩存水平擴展。
- 驅逐策略:緩存實現驅逐策略,如LRU(最近最少使用)、LFU(最少使用頻率)或TTL(生存時間),以清除舊的或使用較少的數據,為新數據騰出空間。
- 協調和同步:協調機制,如分布式鎖或一致性協議,確保緩存節點保持同步,尤其是在多個節點嘗試更改相同數據時。
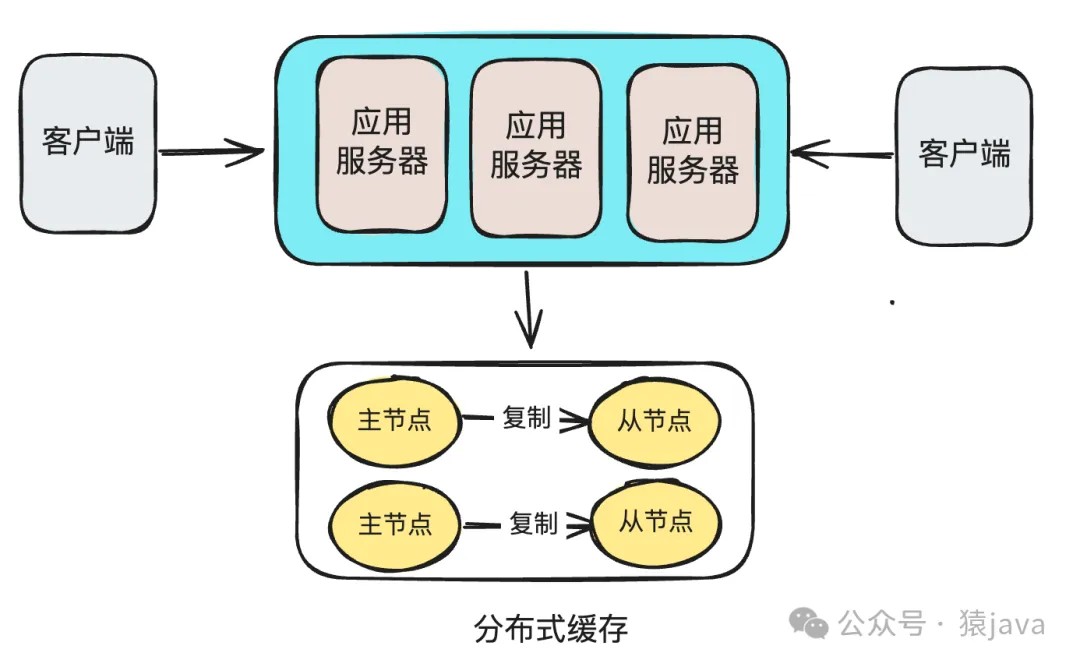
三、分布式緩存如何工作?
(1) 數據分布:當數據被緩存時,客戶端庫通常會對與數據關聯的鍵進行哈希,以確定哪個緩存節點將存儲數據。
(2) 數據復制:為了可靠性,緩存系統會在多個節點上復制緩存數據。因此,如果一個節點(例如A)存儲數據,它可能還會被復制到另一個節點(例如B)作為備份。
(3) 數據檢索:為了從緩存中獲取數據,應用程序提供鍵給客戶端庫。客戶端庫使用這個鍵找到并查詢擁有數據的節點。如果數據存在(緩存命中),它會返回給應用程序。如果沒有(緩存未命中),則從主數據存儲(例如數據庫)獲取數據,并可以緩存以備將來使用。
(4) 緩存失效:為了使緩存數據與主數據源保持同步,需要定期使其失效或更新。緩存系統實現了基于時間的失效或基于事件的失效策略。
(5) 緩存驅逐:由于緩存空間有限,需要驅逐策略為新數據騰出空間。常見的驅逐策略包括:
- 最近最少使用(LRU):驅逐最長時間未訪問的數據。
- 最少使用頻率(LFU):驅逐訪問次數最少的數據。
- 生存時間(TTL):驅逐在緩存中超過指定時間的數據。
四、分布式緩存的優缺點
1.優點
高性能:
- 低延遲:緩存數據通常存儲在內存中,訪問速度遠快于從數據庫或其他持久化存儲中讀取數據。
- 減少數據庫負載:緩存頻繁訪問的數據,減少數據庫查詢次數,從而降低數據庫負載,提高系統的整體性能和響應速度。
可擴展性:
- 水平擴展:通過增加或減少緩存節點,可以輕松擴展緩存容量和處理能力,滿足不同規模的需求。
- 負載均衡:緩存請求可以分散到不同的節點上,避免單點瓶頸,提高系統的吞吐量。
高可用性:
- 容錯能力:緩存數據分布在多個節點上,即使某些節點發生故障,系統仍能繼續運行,提供高可用性。
- 數據復制:通過數據復制和自動故障轉移機制,確保數據的高可用性和系統的容錯能力。
靈活性:
- 多樣的數據結構:支持多種數據結構(如鍵值對、哈希、列表、集合等),方便開發者進行靈活的數據存儲和操作。
- 多種緩存策略:支持多種緩存失效策略(如LRU、LFU、FIFO等),可以根據具體需求進行配置。
實時性:
- 實時數據處理:適用于實時數據處理和事件流處理場景,能夠快速響應和處理大量實時數據。
2.缺點
數據一致性:
- 一致性挑戰:在分布式環境下,保證數據一致性是一個復雜的問題,尤其是在網絡分區或節點故障時。需要采用一致性協議(如Paxos、Raft等)來確保數據一致性,這會增加系統的復雜性和開銷。
- 緩存同步:在多節點之間同步緩存數據可能會引入延遲和一致性問題,需要仔細設計和管理。
數據持久性:
- 數據丟失風險:緩存數據主要存儲在內存中,一旦節點發生故障或重啟,內存中的數據可能會丟失。因此,通常需要結合持久化存儲來保證數據的可靠性。
運維復雜性:
- 監控和管理:分布式緩存系統需要進行監控和管理,及時發現和解決問題,確保系統的穩定性和高性能。這增加了運維的復雜性。
- 配置和調優:需要根據具體應用場景進行配置和調優,以達到最佳性能和穩定性,這需要一定的專業知識和經驗。
網絡開銷:
- 網絡延遲:在分布式環境中,不同節點之間的通信會引入網絡延遲,特別是在跨數據中心的場景下,這可能會影響系統的性能。
- 數據傳輸開銷:在節點之間進行數據復制和同步會增加網絡流量和傳輸開銷。
成本:
- 硬件成本:需要多個節點來存儲和處理緩存數據,這會增加硬件成本和資源消耗。
- 開發成本:需要額外的開發工作來集成和管理分布式緩存系統,增加了開發成本和時間。
五、常見的分布式緩存系統
1.Redis
Redis是一個開源的內存數據存儲,支持存儲各種數據結構,包括字符串、哈希、列表、集合、有序集合、位圖、HyperLogLog和地理空間索引。
它支持數據復制和持久化,使其成為需要數據持久性和容錯性的應用程序的流行選擇。
使用 Redis作為分布式緩存工具對于一個 Java程序員來說,一定也不陌生!
2.Memcached
Memcached是另一個開源的內存緩存系統,設計用于速度和簡潔。它廣泛用于緩存小塊數據,如數據庫查詢結果、API調用或頁面渲染。
Memcached是一個純內存緩存,沒有持久層。這使得它非常適用于不需要永久存儲數據的用例,如緩存數據庫查詢結果。
3.Ehcache
Ehcache是一種廣泛使用的開源Java緩存庫,旨在提高應用程序的性能。它支持多種緩存策略和配置,能夠緩存數據到內存或磁盤,并能與其他分布式緩存解決方案集成。Ehcache主要用于Java應用中,以減少數據庫查詢次數、提高數據訪問速度和改善整體系統性能。
Ehcache的主要特點如下:
- 簡單易用:提供簡潔的API和配置方式,易于集成到Java應用中。
- 多級緩存:支持內存緩存和磁盤緩存,可以將不常用的數據移到磁盤,節省內存。
- 緩存策略:支持多種緩存失效策略,如LRU(Least Recently Used)、LFU(Least Frequently Used)和FIFO(First In, First Out)。
- 持久化:可以將緩存數據持久化到磁盤,保證在應用重啟后數據仍然可用。
- 分布式緩存:通過與Terracotta等分布式緩存框架集成,支持緩存數據在多個節點之間分布和同步。
- 事務支持:支持緩存事務,確保緩存操作的一致性和原子性。
- 監控和管理:提供豐富的監控和管理功能,可以通過JMX(Java Management Extensions)進行監控和管理。
4.Hazelcast
Hazelcast是一種開源的內存數據網格(In-Memory Data Grid,IMDG)解決方案,旨在提供高性能、分布式的數據存儲和計算能力。它將數據分布在多個節點上,并在內存中進行存儲和處理,從而實現快速的數據訪問和高可用性。Hazelcast適用于各種分布式應用場景,如緩存、會話管理、分布式計算和事件流處理。
Hazelcast的主要特點如下:
- 分布式數據結構:支持多種分布式數據結構,如Map、Queue、Set、List、MultiMap等,方便開發者進行分布式數據存儲和操作。
- 高可用性:通過數據復制和自動故障轉移機制,確保數據的高可用性和系統的容錯能力。
- 可擴展性:可以動態添加或移除節點,實現線性擴展,滿足不同規模的需求。
- 內存存儲:數據存儲在內存中,提供極高的數據訪問速度。
- 分布式計算:支持分布式任務執行、MapReduce等計算框架,能夠在多個節點上并行處理數據。
- 事件處理:支持事件監聽和處理,適用于實時數據處理和事件驅動的應用程序。
- 持久化:提供持久化選項,可以將數據保存到磁盤或數據庫中,以確保數據的持久性。
- 集成與兼容性:與多種技術和框架(如Spring、Hibernate、JCache等)集成,方便在現有項目中使用。
六、分布式緩存使用場景
分布式緩存在現代計算系統中有著廣泛的應用,特別是在需要高性能、高可用性和可擴展性的場景中。以下是一些常見的分布式緩存使用場景:
1.Web應用加速
分布式緩存可以顯著提升Web應用的響應速度,通過緩存頻繁訪問的數據(如用戶信息、產品詳情、頁面內容等),減少數據庫查詢次數,從而降低數據庫負載,提高系統的吞吐量。
2.會話管理
在分布式系統中,用戶會話數據需要在多個服務器之間共享。分布式緩存可以存儲會話數據,確保用戶無論訪問哪個服務器,都能獲得一致的會話狀態。這對于負載均衡和高可用性尤為重要。
3.配置管理
對于配置數據較多且頻繁讀取的應用,可以將配置數據存儲在分布式緩存中。這樣可以減少配置文件的讀取次數,提高配置數據的訪問速度。
4.數據分析
在大數據分析場景中,分布式緩存可以存儲中間計算結果或頻繁訪問的數據,減少重復計算,提高數據處理效率。例如,在機器學習和數據挖掘任務中,分布式緩存可以加速模型訓練和預測過程。
5.實時數據處理
在實時數據處理場景中,如物聯網數據處理、金融交易處理、監控和報警系統等,分布式緩存可以存儲實時數據和事件流,提供快速的數據讀取和寫入能力,確保系統的實時性和高性能。
6.分布式計算
在分布式計算框架中(如MapReduce、Spark等),分布式緩存可以用于存儲任務的中間結果,減少數據傳輸和重復計算,提高計算效率。
7.CDN
在CDN(內容分發網絡)系統中,分布式緩存用于存儲和分發靜態內容(如圖片、視頻、文件等),提高內容分發速度,減少服務器負載。
8.搜索引擎
搜索引擎需要快速響應用戶的查詢請求,分布式緩存可以存儲索引數據和查詢結果,加速搜索過程,提高用戶體驗。
9.購物車
在電商平臺中,用戶的購物車數據需要在多個服務器之間共享和同步。分布式緩存可以存儲購物車數據,確保用戶在不同設備和瀏覽器中看到一致的購物車狀態。
10.推薦系統
推薦系統需要快速訪問用戶行為數據和推薦結果。分布式緩存可以存儲用戶的歷史行為數據和推薦結果,提供快速的推薦服務。
七、總結
分布式緩存是一種數據緩存技術,通過將數據分布在多個節點上,提高系統的性能、可擴展性和高可用性。其主要優點包括低延遲、高性能、水平擴展能力和容錯能力,適用于Web應用加速、會話管理、數據分析和實時數據處理等場景。然而,分布式緩存也面臨數據一致性挑戰、數據持久性問題、運維復雜性和網絡開銷等缺點。合理使用分布式緩存需要權衡這些優缺點,并進行適當的配置和管理,以滿足具體應用的需求。


























