













小紅書一面:Kafka 是如何選擇 Leader 的?
Kafka作為一款優(yōu)秀的分布式消息中間件,內(nèi)部也存在一些選舉機(jī)制,這篇文章,我們將詳細(xì)地分析 Kafka如何實現(xiàn)選擇 Leader?

一、Kafka集群整體架構(gòu)
Kafka集群是由多個 Kafka Broker通過連同一個 Zookeeper組成,整個架構(gòu)可以抽象成下圖:
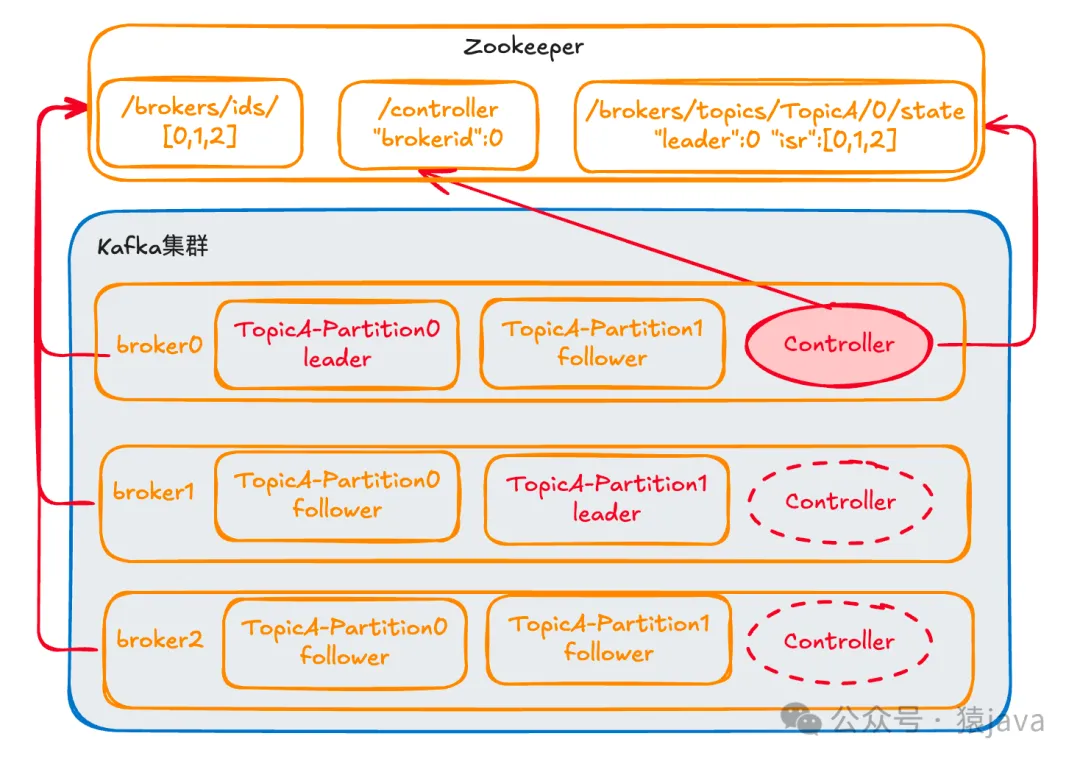
在 Kafka中,數(shù)據(jù)以 Topic的形式組織,每個主題又被劃分為多個分區(qū)(Partition),每個分區(qū)的數(shù)據(jù)在 Broker之間有多個副本(Replica),保證數(shù)據(jù)的高可用和持久性。
二、Controller的作用
Kafka Controller是一個特殊的 Broker實例,它負(fù)責(zé) Kafka集群中的領(lǐng)導(dǎo)者選舉、分區(qū)的分配、以及在 Broker上下線期間重新分配 Leader和副本。Controller通過與 Zookeeper交互來感知集群狀態(tài)的變化,從而進(jìn)行必要的領(lǐng)導(dǎo)者重新選舉。
三、選主的原理分析
1.Leader的概念
在 Kafka中,每個分區(qū)會有多個副本,其中只有一個副本是Leader,其他副本為Follower。Producer和 Consumer會向分區(qū)的Leader寫入或讀取數(shù)據(jù),F(xiàn)ollower從 Leader復(fù)制數(shù)據(jù)。這樣設(shè)計實現(xiàn)了高吞吐量的同時保證了數(shù)據(jù)的冗余。
2.選主過程
選主過程主要包括兩個方面:Controller選舉和分區(qū)Leader選舉。
(1) Controller選舉
在 Kafka啟動時,會注冊到 Zookeeper的/brokers/ids的路徑下,其中會有一個 Broker節(jié)點通過與 Zookeeper的交互被選舉為 Controller。具體而言,Brokers通過在 Zookeeper的/controller路徑嘗試創(chuàng)建一個臨時節(jié)點(ephemeral node)來競爭成為 Controller,選舉規(guī)則也很簡單,誰先注冊到 Zookeeper中的/controller節(jié)點,誰就是 Controller。
當(dāng)當(dāng)前Controller失效(如宕機(jī)或網(wǎng)絡(luò)問題)時,Zookeeper會刪除/controller節(jié)點,其他Broker會再次競爭,該過程保證了Controller的高可用。
(2) 分區(qū)Leader選舉
一旦一個 Broker成為 Controller,它會獲取所有分區(qū)的最新信息,并基于持久化在 Zookeeper的數(shù)據(jù)進(jìn)行當(dāng)前各分區(qū) Leader的選舉。Controller使用 ISR(In-Sync Replica)列表,即當(dāng)前與 Leader保持同步的所有Follower副本進(jìn)行選主。默認(rèn)情況下,ISR中第一個副本被選為新的 Leader。
比如上圖中 TopicA中的 Partition0號分區(qū),選擇 broker0作為 Leader, 然后會將選擇的節(jié)點信息注冊到 Zookeeper的/brokers/topics路徑下,記錄誰是 Leader,有哪些服務(wù)器可用。
Kafka 在實現(xiàn) Controller選舉方面采用了一種基于 Zookeeper的機(jī)制,這種機(jī)制充分利用了 Zookeeper的特性來確保集群的高可用性和一致性,接下來,我將深入解析這兩種選主的機(jī)制。
四、Controller選舉機(jī)制詳解
1. Zookeeper的Role
Zookeeper在Kafka中作為一個分布式協(xié)調(diào)服務(wù),其負(fù)責(zé)維護(hù)集群的元數(shù)據(jù)信息,包括Kafka節(jié)點的活動狀態(tài)和每個分區(qū)的Replica信息。在Controller選舉過程中,Zookeeper充當(dāng)著協(xié)調(diào)者的角色,利用其特有的臨時節(jié)點機(jī)制來實現(xiàn)一個分布式的鎖。
2. 臨時節(jié)點
在Zookeeper中,臨時節(jié)點(Ephemeral Znode)是一個重要的特性,這種節(jié)點在客戶端會話結(jié)束時自動被刪除。Kafka利用這一特性實現(xiàn)Controller的自動化選舉。
3. Controller選舉過程
Kafka的Controller選舉過程主要分為以下幾個步驟:
- 初始化: 當(dāng)Kafka Broker啟動時,所有Broker都試圖成為Controller。每個Broker會進(jìn)行一次自檢,初始化必要的Controller管理器和相關(guān)結(jié)構(gòu)。
- 創(chuàng)建Zookeeper路徑: 每個Broker嘗試在Zookeeper的特定路徑(通常是/controller)下創(chuàng)建一個臨時節(jié)點。該節(jié)點的路徑即為Zookeeper中控制選舉的關(guān)鍵路徑。
- 競爭鎖: 因為臨時節(jié)點的特性,只有第一個成功創(chuàng)建的節(jié)點會存在于Zookeeper。因此,能創(chuàng)建成功的Broker就會成為當(dāng)前集群的Controller。這相當(dāng)于分布式鎖機(jī)制,誰獲取到鎖誰成為Controller。
- 故障處理與重新選舉: 如果當(dāng)前的Controller(持有Zookeeper節(jié)點的Broker)崩潰或因網(wǎng)絡(luò)問題與Zookeeper斷開連接,Zookeeper會自動刪除該Broker創(chuàng)建的臨時節(jié)點。剩余的Broker會監(jiān)聽這個節(jié)點的變化(通過Zookeeper的Watcher機(jī)制),當(dāng)節(jié)點被刪除時,會重新發(fā)起競爭,確保能夠快速選出一個新的Controller。
4. 實現(xiàn)細(xì)節(jié)
從實現(xiàn)的角度來看,我們可以看看 Kafka的相關(guān)主要類和方法涉及的過程:
- Zookeeper客戶端初始化: 初始化時,Kafka的KafkaController類通過Zookeeper客戶端來與ZooKeeper服務(wù)建立連接,這是基礎(chǔ)。
- Controller路徑定義: 在Kafka源碼中,通常由ControllerZNodePaths.CONTROLLER_PATH常量定義Controller路徑。
在ControllerEventManager類中,核心的方法參與Zookeeper節(jié)點的創(chuàng)建與監(jiān)聽:
public void onControllerFailover() {
try {
// 嘗試在Zookeeper創(chuàng)建臨時節(jié)點
zkClient.createEphemeralPathExpectConflictHandleZnode(
ControllerZNodePaths.CONTROLLER_PATH,
controllerString(),
onControllerFailover);
// 設(shè)置Controller監(jiān)聽器
zkClient.subscribeDataChanges(ControllerZNodePaths.CONTROLLER_PATH, new ControllerChangeListener());
} catch (Exception e) {
// 異常處理
}
}在上述代碼段中,展示了當(dāng)一個 Broker準(zhǔn)備競選為Controller時,他會在Zookeeper的/controller路徑創(chuàng)建一個臨時節(jié)點,并設(shè)置對該節(jié)點變化的監(jiān)聽器。
5. 監(jiān)聽機(jī)制
每個Broker通過設(shè)置Watcher來監(jiān)聽/controller節(jié)點的刪除事件。一旦現(xiàn)有Controller的連接丟失,所有的Broker都會收到這個事件通知。這個機(jī)制確保了在現(xiàn)有Controller失效時,能夠迅速選出新的Controller。
6. Leader和集群的穩(wěn)定性
一旦新的Controller被選出,它就會獲取集群的元數(shù)據(jù),并開始執(zhí)行其職責(zé),包括領(lǐng)導(dǎo)者重新選舉和分區(qū)管理等操作。為了確保集群狀態(tài)的一致性和穩(wěn)定性,Controller必須在全面獲取并更新當(dāng)前集群狀態(tài)后才能完全上線。
五、分區(qū)Leader選舉詳解
當(dāng)然,Kafka中的分區(qū)Leader選舉是確保數(shù)據(jù)高可用性和一致性的關(guān)鍵機(jī)制之一。讓我們更詳細(xì)地探討一下這一過程,包括其觸發(fā)條件、具體步驟和相關(guān)代碼實現(xiàn)細(xì)節(jié)。
1.分區(qū)Leader選舉的觸發(fā)條件
分區(qū)Leader選舉主要在以下幾種情況下被觸發(fā):
- Broker新增或宕機(jī):當(dāng)一個Broker加入集群或者從集群中失聯(lián)(掉線)時,需要重新分配分區(qū)的Leader。
- ISR(In-Sync Replica)變化:ISR列表中的Replica發(fā)生變化,比如某個Replica落后過多或恢復(fù)同步。
- Controller切換:如果當(dāng)前的Controller失效,新Controller上線后需要重新確認(rèn)并分配分區(qū)的Leader。
2.選舉的具體步驟
分區(qū)Leader選舉過程主要涉及以下幾步:
(1) 獲取分區(qū)信息
一旦選舉觸發(fā),Controller需獲取每個分區(qū)的元數(shù)據(jù)信息,包括:
- 當(dāng)前Leader。
- ISR列表(保持與Leader同步的副本集合)。
- 所有分區(qū)的Replica列表。
(2) 確定新Leader
Controller根據(jù)ISR列表來選擇新的Leader,通常選擇第一個Replica作為新的Leader,這樣保證選擇的是同步的且相對最新的副本。此外,Kafka允許通過配置參數(shù)自定義選舉策略,確保更靈活地處理特殊場景。
(3) 更新Zookeeper
選出新的Leader后,需將這個新的Leader信息更新到Zookeeper,這包括更新分區(qū)的Leader和ISR信息。此步驟確保其他Broker即使在Controller切換的情況下,也能從Zookeeper獲取到正確的分區(qū)Leader信息。
(4) 通知各Broker
更新完Zookeeper后,Controller通過向集群中其他Broker發(fā)送Leader和ISR更新信息,通知它們該分區(qū)的Leader已發(fā)生改變。這涉及使用Kafka的內(nèi)部API向其他Broker推送集群狀態(tài)變更。
3.核心代碼分析
以下是分區(qū)Leader選舉過程中的一些核心代碼實現(xiàn)示例:
(1) 獲取ISR列表
public List<Integer> getIsrForPartition(Partition partition) {
// 獲取分區(qū)的ISR列表
return partition.getIsr();
}ISR列表的獲取是選舉過程中的基礎(chǔ)步驟,確保后續(xù)的Leader選舉從一致的數(shù)據(jù)集合中挑選。
(2) 選舉新Leader
下面的代碼展示了如何選擇 Leader,通過從 ISR中挑選第一個節(jié)點作為新 Leader,確保選擇的 Leader始終是最新同步過的一個。
public int selectNewLeader(/* some parameters */) {
List<Integer> isr = currentIsr(partition);
if (isr.isEmpty()) {
throw new IllegalStateException("ISR should not be empty");
}
// 默認(rèn)選擇ISR列表中的第一個
int newLeader = isr.get(0);
// 更新新Leader信息到Zookeeper
zkClient.updateLeaderAndIsr(newLeader, isr);
return newLeader;
}(3) 更新到Zookeeper
public void updateLeaderAndISR(int newLeader, List<Integer> newIsrList, Partition partition) {
zkClient.setData(ControllerZNodePaths.getTopicPartitionStatePath(partition),
new LeaderAndIsrZNodeData(newLeader, newIsrList));
}這段代碼表示將新的 Leader和 ISR信息更新到Zookeeper,確保全局一致性。
總結(jié)
本文,我們分析了 Kafka的 Leader選舉機(jī)制原理,它通過巧妙利用 Zookeeper和 ISR列表,提升了 Kafka的可靠性和可用性,但是,因為重度依賴 Zookeeper,因此使得 Kafka也存在很多風(fēng)險。作為程序員,了解 Kafka的機(jī)制,可以幫助我們更好地使用和運(yùn)維 Kafka。


























