模型無關的局部解釋(LIME)技術原理解析及多領域應用實踐
在當前數據驅動的商業環境中,人工智能(AI)和機器學習(ML)已成為各行業決策制定的關鍵工具。從金融機構的信貸風險預測到醫療保健提供者的疾病診斷,AI模型正在塑造對生活和業務有深遠影響的結果。

然而隨著這些模型日益復雜化,一個重大挑戰浮現:即"黑盒"問題。許多先進的AI模型,尤其是深度學習算法,其運作機制甚至對其創建者而言也難以理解。這種不透明性引發了幾個關鍵問題:
- 信任缺失:利益相關者可能對難以理解的決策過程持謹慎態度。
- 監管合規:多個行業要求可解釋的決策流程。
- 倫理考量:不可解釋的AI可能無意中延續偏見或做出不公平決策。
- 改進困難:若不了解決策過程,優化模型將面臨挑戰。
LIME(模型無關的局部解釋)應運而生,旨在解析AI黑盒,為任何機器學習模型的個別預測提供清晰、可解釋的說明。
LIME的起源:簡要歷史
LIME于2016年由華盛頓大學的Marco Tulio Ribeiro及其同事Sameer Singh和Carlos Guestrin引入機器學習領域。他們的開創性論文"'Why Should I Trust You?': Explaining the Predictions of Any Classifier"在第22屆ACM SIGKDD國際知識發現與數據挖掘會議上發表。
Ribeiro團隊受到AI社區面臨的一個核心問題驅動:如果我們不理解模型的決策機制,如何信任其預測?鑒于復雜的不透明模型(如深度神經網絡)在高風險決策過程中的廣泛應用,這個問題尤為重要。
研究人員認識到,盡管全局可解釋性(理解整個模型)對復雜AI系統通常難以實現,但局部可解釋性(解釋單個預測)可以提供有價值的洞察。這一認識促成了LIME的開發。
LIME的設計基于三個核心原則:
- 可解釋性:解釋應易于人類理解。
- 局部保真度:解釋應準確反映模型在被解釋預測附近的行為。
- 模型無關:該技術應適用于解釋任何機器學習模型。
自引入以來,LIME已成為可解釋AI領域最廣泛使用的技術之一。它在各行業中得到應用,并推動了對模型解釋方法的進一步研究。
LIME的工作原理
LIME的定義
LIME(Local Interpretable Model-Agnostic Explanations)是一種解釋技術,能以人類可理解的方式闡釋任何機器學習分類器的預測結果。它可以被視為一個高效的解釋器,能將復雜的AI模型轉化為易懂的術語,無論原始模型的類型如何。
LIME的核心原理
LIME基于一個基本假設:雖然復雜AI模型的整體行為可能難以理解,但我們可以通過觀察模型在特定預測周圍的局部行為來解釋個別預測。
這可以類比為理解自動駕駛汽車在特定時刻的決策過程。LIME不是試圖理解整個復雜系統,而是聚焦于特定時刻,基于當時的環境因素創建一個簡化的解釋模型。
LIME的工作流程
1、選擇預測實例:確定需要解釋的AI模型特定預測。
2、生成擾動樣本:在選定預測的鄰域生成略微改變的輸入數據變體。
3、觀察模型響應:記錄模型對這些擾動樣本的預測變化。
4、構建簡化模型:基于這些觀察結果,創建一個簡單的、可解釋的模型,以模擬復雜模型在該局部區域的行為。
5、提取關鍵特征:從簡化模型中識別對該特定預測最具影響力的因素。
這一過程使LIME能夠為特定實例提供模型決策過程的洞察,對于尋求理解和解釋AI驅動決策的企業而言,這一功能極為重要。
LIME在實際業務中的應用
以下案例展示了LIME在不同行業和數據類型中的應用,凸顯了其多樣性和對業務運營的影響。
金融領域:信用風險評估
場景:某大型銀行使用復雜的機器學習模型進行信用風險評估和貸款審批。該模型考慮數百個變量來得出結論。盡管機器決策可能基于復雜的模式匹配而具有準確性,但這使得貸款官員難以理解并向客戶解釋決策依據。
# 導入必要的庫
# 加載數據集
# 使用來自openml的德國信用數據集
credit = fetch_openml('credit-g', version=1, as_frame=True)
X = credit.data
y = credit.target
# 將目標變量轉換為二進制(好/壞到0/1)
y = y.map({'good': 0, 'bad': 1})
# 預處理:使用獨熱編碼將分類特征轉換為數值
X = pd.get_dummies(X, drop_first=True)
# 分割數據
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 標準化數據
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 訓練隨機森林分類器
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 初始化LIME
explainer = lime.lime_tabular.LimeTabularExplainer(
training_data=X_train,
feature_names=X.columns,
class_names=['Good', 'Bad'],
mode='classification'
)
# 遍歷測試集中的多個實例
for i in range(3): # 可根據需要調整解釋的實例數量
# 打印實際記錄
actual_record = X_test[i]
print(f"Actual record for instance {i}:")
print(pd.DataFrame(actual_record.reshape(1, -1), columns=X.columns))
# 生成LIME解釋
exp = explainer.explain_instance(X_test[i], model.predict_proba, num_features=5)
# 顯示LIME解釋
exp.show_in_notebook(show_table=True)
exp.as_pyplot_figure()
plt.show()
# 提取并打印解釋詳情
explanation = exp.as_list()
print(f"Explanation for instance {i}:")
for feature, weight in explanation:
print(f"{feature}: {weight:.2f}")
print("\n")
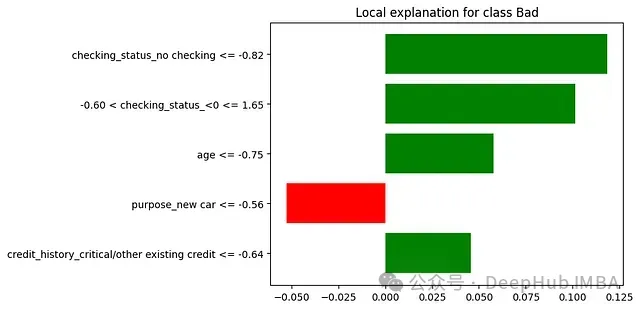

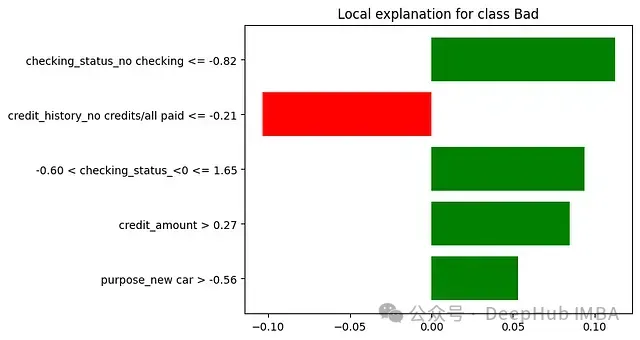

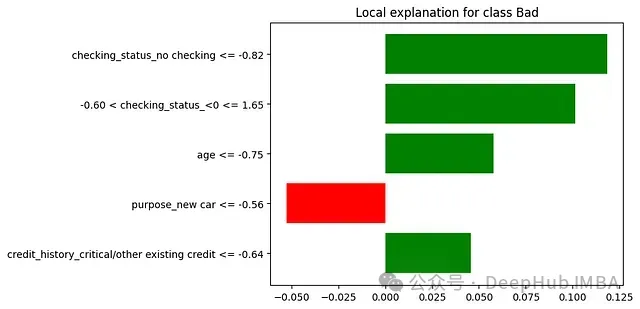
未使用LIME時:若銀行使用模型判定某小企業主不符合貸款條件,貸款官員只能告知申請人AI模型認為其風險較高,而無法提供具體理由。
使用LIME時:LIME能夠分析決策并提供如下解釋:銀行官員現可以準確地傳達決策理由 — "該貸款申請被歸類為高風險,主要基于以下因素:
1.債務收入比:65%(對高風險決策的貢獻為+35%)
- 顯著高于我們首選的36%比率
2.近期信用查詢:過去6個月內7次(+25%)
- 表明頻繁尋求信貸,可能構成風險因素
3.企業年限:14個月(+20%)
- 我們通常偏好運營至少24個月的企業
業務影響:
- 提高客戶溝通透明度:貸款官員能向申請人提供具體、可行的反饋,有助于其改進未來的申請。
- 確保公平貸款實踐:通過審查多個決策的LIME解釋,銀行可以驗證模型決策過程中是否存在無意的偏見。
- 模型優化:信用風險團隊可以驗證模型是否考慮了適當的因素,并在必要時進行調整。例如,如果發現行業風險因素的權重過高,可以考慮降低其影響。
- 監管合規:在審計時,銀行可以為每個貸款申請展示清晰、可解釋的決策過程。
- 員工培訓:可以培訓貸款官員理解這些解釋,提高其與AI系統協同工作的能力。
文本數據分析:酒店業客戶反饋評估
場景:本例展示了LIME如何在基于文本分類的機器學習模型中提供解釋。考慮一個大型連鎖酒店利用AI模型分析來自各種平臺的數千條客戶評論,將它們分類為特定的贊揚或關注領域(如清潔度、服務、設施)。
# 導入必要的庫
# 加載數據集
file_path = '/content/sample_data/Hotel_Reviews.csv'
data = pd.read_csv(file_path)
# 合并'Negative_Review'和'Positive_Review'列
negative_reviews = data[['Negative_Review']].rename(columns={'Negative_Review': 'Review'})
negative_reviews['Sentiment'] = 'negative'
positive_reviews = data[['Positive_Review']].rename(columns={'Positive_Review': 'Review'})
positive_reviews['Sentiment'] = 'positive'
# 連接正面和負面評論
reviews = pd.concat([negative_reviews, positive_reviews])
reviews = reviews[reviews['Review'].str.strip() != ''] # 移除空評論
# 將標簽編碼為二進制
reviews['Sentiment'] = reviews['Sentiment'].map({'positive': 1, 'negative': 0})
# 分割數據
X_train, X_test, y_train, y_test = train_test_split(reviews['Review'], reviews['Sentiment'], test_size=0.2, random_state=42)
# 向量化文本數據并移除停用詞
vectorizer = TfidfVectorizer(max_features=1000, stop_words='english')
X_train_tfidf = vectorizer.fit_transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)
# 訓練邏輯回歸模型
model = LogisticRegression()
model.fit(X_train_tfidf, y_train)
# 初始化LIME
explainer = lime.lime_text.LimeTextExplainer(class_names=['negative', 'positive'])
# 定義預測函數
def predict_proba(texts):
texts_transformed = vectorizer.transform(texts)
return model.predict_proba(texts_transformed)
# 遍歷測試集中的多個實例
for i in range(5): # 可根據需要調整解釋的實例數量
# 打印實際評論
actual_review = X_test.iloc[i]
print(f"Explanation for instance {i}:")
print(actual_review)
# 生成LIME解釋
exp = explainer.explain_instance(actual_review, predict_proba, num_features=6)
# 顯示LIME解釋
exp.show_in_notebook()
exp.as_pyplot_figure()
plt.show()
# 提取并打印解釋詳情
explanation = exp.as_list()
print(f"Explanation for instance {i}:")
for phrase, weight in explanation:
print(f"{phrase}: {weight:.2f}")
print("\n")
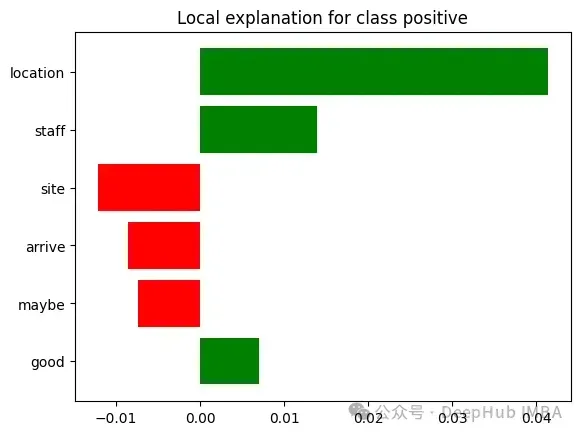

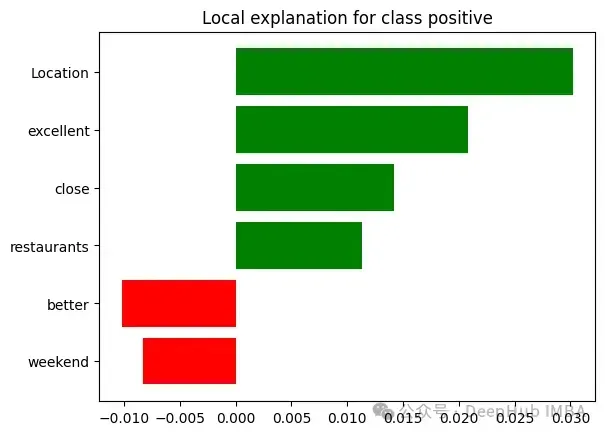
未使用LIME時:客戶體驗團隊觀察到某家酒店因"服務質量差"而被標記,但無法理解導致這一分類的具體問題。
使用LIME時:對于一條被歸類為"服務質量差"的評論,LIME可能提供如下解釋:"該評論被歸類為'服務質量差',基于以下關鍵問題:
- '等待30分鐘才能辦理入住'(+40%影響)
- '員工對請求反應遲鈍'(+30%影響)
- '客房服務訂單錯誤'(+15%影響)
- '沒有為不便道歉'(+10%影響)
- '經理不在場'(+5%影響)
值得注意的是,諸如'房間干凈'和'位置很好'等正面短語對這一分類的影響微乎其微。"
業務影響:
- 精準改進:酒店管理層可以聚焦需要改進的具體領域,如縮短入住時間和提高員工響應速度。
- 培訓機會:人力資源部門可以開發針對性的培訓計劃,解決已識別的問題,例如關于如何迅速處理客人請求的研討會。
- 實時警報:系統可以設置為在收到含有強烈負面服務指標的評論時立即通知管理人員,允許快速響應和服務補救。
- 趨勢分析:通過長期匯總LIME解釋,連鎖酒店可以識別不同物業或季節性的反復出現的問題,為更廣泛的戰略決策提供依據。
- 客戶溝通:營銷團隊可以利用正面評論中的洞察(即使在整體負面反饋中)來突出酒店的優勢。
- 模型驗證:數據科學團隊可以確保模型正確解釋微妙或諷刺的語言,必要時進行調整。
圖像數據分析:制造業質量控制
場景:本例展示了LIME如何用于解釋基于圖像分類的機器學習模型。
為了說明圖像可解釋性,我們將使用MNIST數據集,該數據集包含大量從0到9的手寫數字圖像。
# 導入必要的庫
# 加載MNIST數據集(用作制造組件圖像的代理)
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 預處理數據
X_train = X_train.reshape(-1, 28, 28, 1).astype('float32') / 255
X_test = X_test.reshape(-1, 28, 28, 1).astype('float32') / 255
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# 訓練一個簡單的CNN模型
model = Sequential([
Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 3)),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train_rgb, y_train, epochs=5, batch_size=200, verbose=1, validation_data=(X_test_rgb, y_test))
# 初始化LIME
explainer = lime.lime_image.LimeImageExplainer()
# 定義預測函數
def predict_proba(images):
return model.predict(images)
# 選擇實例進行解釋
for i in range(5): # 可根據需要調整解釋的實例數量
# 獲取一個實例進行解釋
image = X_test_rgb[i]
explanation = explainer.explain_instance(image, predict_proba, top_labels=1, hide_color=0, num_samples=1000)
# 獲取頂級標簽的解釋
temp, mask = explanation.get_image_and_mask(explanation.top_labels[0], positive_only=True, num_features=5, hide_rest=False)
# 顯示帶有解釋的圖像
plt.imshow(mark_boundaries(temp, mask))
plt.title(f"Explanation for instance {i}")
plt.show()
# 打印詳細解釋
print(f"Explanation for instance {i}:")
print(explanation.local_exp[explanation.top_labels[0]])
print("\n")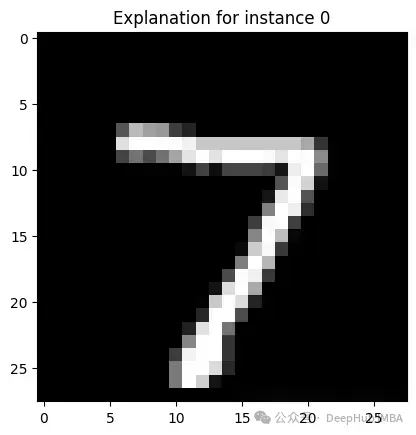
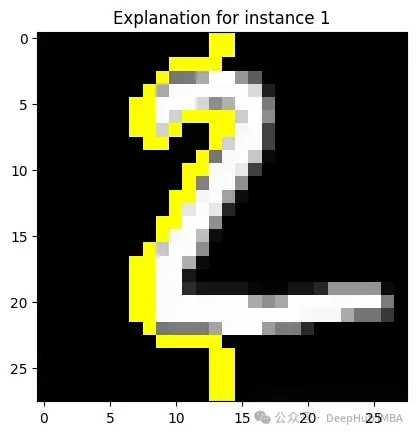
未使用LIME時:類似于前面使用MNIST的例子 - 我們已經看到數字被識別,但無法確定AI系統如何進行判斷
使用LIME時:對于一個被標記為有圖像,LIME可能提供一個熱圖疊加層,突出顯示模型是如何識別這個數字的,這對于研究模型的原理十分重要
LIME的優勢與局限性
盡管LIME已被證明是解釋AI決策的有力工具,但企業在應用時需要充分了解其優勢和局限性。這種平衡的認識有助于組織有效地使用LIME,同時意識到其潛在的不足。
LIME的優勢
- 模型無關性:LIME可以解釋任何機器學習模型的預測,無論其復雜程度如何。這種通用性使其在各種商業環境中都具有價值。
- 解釋直觀性:LIME以原始特征的形式提供解釋,使非技術背景的利益相關者也能輕松理解。
- 局部保真度:通過專注于解釋個別預測,LIME能為特定實例提供高度準確的解釋,即使模型的全局行為復雜。
- 可定制性:該方法允許在解釋類型(如決策樹、線性模型)和解釋中包含的特征數量方面進行定制。
- 視覺表現力:LIME可以提供視覺解釋,對圖像和文本數據特別有效,增強了可解釋性。
- 增進信任:通過提供清晰的解釋,LIME有助于在用戶、客戶和監管機構中建立對AI系統的信任。
- 輔助調試:LIME可以通過揭示意外的決策因素,幫助數據科學家識別模型中的偏見或錯誤。
LIME的局限性和挑戰
- 局部vs全局解釋:LIME專注于局部解釋,可能無法準確表示模型的整體行為。如果用戶試圖從這些局部解釋中概括,可能導致誤解。
- 穩定性問題:由于其基于采樣的方法,LIME有時會在多次運行中為同一預測產生不同的解釋。這種不穩定性在高風險決策環境中可能產生問題。
- 特征獨立性假設:LIME在創建解釋時假設特征獨立,這可能不適用于許多具有相關特征的真實世界數據集。
- 計算開銷:生成LIME解釋在計算上可能較為昂貴,特別是對于大型數據集或實時應用。
- 核寬度敏感性:LIME中核寬度的選擇可能顯著影響結果解釋。選擇適當的寬度可能具有挑戰性,可能需要領域專業知識。
- 非線性關系處理:LIME使用的線性模型來近似局部行為可能無法準確捕捉復雜的非線性關系。
- 對抗性攻擊風險:研究表明,可以創建行為與其LIME解釋不一致的模型,可能誤導用戶。
- 因果關系洞察不足:LIME提供相關性解釋而非因果性解釋,這可能限制其在理解模型真實決策過程方面的應用。
- 高維數據挑戰:隨著特征數量的增加,LIME解釋的質量可能會降低,使其對非常高維的數據集效果較差。
- 解釋偏見:LIME解釋的呈現方式可能影響其解讀,可能引入人為偏見。
未來發展方向和新興趨勢
隨著企業持續應對可解釋AI的需求,以下幾個發展方向值得關注:
- 技術融合:將LIME與其他解釋方法(如SHAP,SHapley Additive exPlanations)結合,以獲得更全面的洞察。
- 自動決策支持:開發不僅能解釋AI決策,還能基于這些解釋提供潛在行動建議的系統。
- 實時解釋引擎:研發更快、更高效的LIME實現,以支持高容量應用的實時解釋需求。
- 個性化解釋:為不同的利益相關者(如技術vs非技術人員,客戶vs監管機構)定制解釋內容和形式。
- 非結構化數據解釋:推進在解釋復雜數據類型(如視頻或音頻)的AI決策方面的技術。
- 聯邦可解釋性:發展在不損害數據隱私的前提下解釋分布式數據集上訓練的模型的技術。
- 因果解釋:超越相關性,為AI決策提供因果解釋的方法。
總結:在AI時代擁抱透明度
LIME代表了可解釋AI領域的重大進展,為企業提供了一個強大的工具來洞察其AI模型的決策過程。自2016年Marco Ribeiro及其同事引入以來,LIME已成為數據科學家工具箱中不可或缺的技術,幫助縮小復雜AI系統和人類理解之間的鴻溝。
LIME的優勢 - 其模型無關性、直觀解釋和提供局部洞察的能力 - 使其成為尋求建立信任、確保合規性和改進AI系統的企業的寶貴資產。然而,重要的是要認識到LIME的局限性,包括其對局部解釋的關注、潛在的不穩定性以及在處理高維或高度相關數據時的挑戰。
隨著AI繼續發展并滲透到業務運營的各個方面,像LIME這樣的技術將扮演越來越重要的角色。它們不僅代表技術解決方案,還象征著向更透明、負責任和以人為中心的AI方法轉變。
展望未來,我們可以期待看到可解釋AI的進一步發展,以LIME奠定的基礎為起點。這可能包括更穩定和高效的解釋方法、能夠提供因果洞察的技術,以及能夠更好地處理真實世界數據復雜性的方法。
對于企業而言,擁抱可解釋AI不僅關乎技術合規或模型改進。它是關于培養透明文化,與利益相關者建立信任,并確保AI系統以可解釋、道德和符合人類價值觀的方式增強人類智能。
在這個AI時代,我們的目標不僅僅是創造更強大的AI系統,而是開發我們可以理解、信任和有效使用以做出更明智決策的AI。LIME和其他可解釋AI技術是這一旅程的關鍵步驟,幫助我們揭示AI的黑盒子,充分發揮其對業務和社會的潛力。