













機器人世界模型,TeleAI用少量數據完成訓練 | NeurIPS 2024
引言:TeleAI 李學龍團隊提出具身世界模型,挖掘大量人類操作視頻和少量機器人數據的共同決策模式。
當你在綠茵場上進行一場緊張刺激的足球比賽時,大腦會像一位精明的導演,不斷地在腦海中預演著比賽的下一步發展。你會想象如何帶球突破對方防線、如何與隊友配合制造進球機會等。
這種內心的想象是基于豐富的比賽經驗、對足球規則的深刻理解以及對隊友特點的熟悉。
大腦能夠迅速從記憶中提取信息,結合當前的比賽狀況,預測未來可能出現的場景,并以近乎動畫的形式在腦海中迅速閃現,幫助人類做出更好的決策。
正如足球比賽中展現的一樣,大腦的預演能力實際上是一個精簡版的“世界模型”,通過模擬未來可能發生的情景來指導人類行為。
受此啟發,具身智能研究中有望通過構建類似的“視頻預測模型”作為機器人“世界模型”,通過歷史序列和實時觀測,預測未來可能發生的事件,形成對機器人未來行為的視頻預測。
世界模型給機器人提供了一個“內心預演”的工具,能夠在實際采取行動之前評估可能的行動方案及后果,幫助機器人進行決策。
近期,中國電信集團CTO、首席科學家、中國電信人工智能研究院(TeleAI)院長李學龍教授帶領團隊基于長期以來在擴散噪聲、正激勵噪聲、張量噪聲等噪聲分析的基礎上,對具身世界模型構建中的樣本效率難題進行了深入研究,在少樣本驅動的具身世界模型構建方面邁出了重要的一步。
這項工作提出了全新的具身視頻噪聲擴散模型的訓練方法,通過充分挖掘大量人類操作視頻和機器人操作的共同模式,在僅使用少量具身數據的情況下訓練高效的具身世界模型。
論文由TeleAI院長李學龍教授、TeleAI研究科學家白辰甲博士聯合香港科技大學、上海交通大學、上海人工智能實驗室等單位共同完成,近期被國際人工智能頂會NeurIPS 2024錄用,HKUST在讀博士何浩然為該論文的第一作者。

研究動機
構建通用的機器人世界模型是一項長期的挑戰。盡管以Sora為代表的視頻生成模型在通用視頻生成中有出色的表現,但依賴于對大規模視頻數據集學習。
然而,在具身智能領域,高質量的機器人操作視頻的獲取是非常困難的,且不同類型的機器人數據難以通用。具身世界模型的學習非常具有挑戰性,亟需一種通過少量數據學習的通用具身世界模型構建方法。
本研究提出,能否利用在其他相似領域的大規模視頻數據,特別是人類操作視頻來幫助學習具身世界模型?人類在現實場景中第一視角的物體操作視頻和機器人操作任務具有高度的相似性,包含了物理世界的交互信息,并具有多元的任務場景、復雜的視覺背景、多樣的物體類型,能夠幫助具身世界模型學習物體操作的先驗知識。
近期部分工作開始利用人類操作數據來策略學習,然而局限于從人類視頻中提取圖像表征或Affordance區域,忽略了人類操作視頻中蘊含的豐富的時序信息的行為決策信息,不同于現有方法,本研究提出構建基于人類操作的視頻預測(video prediction)來進行世界模型構建,同時通過少量含有動作的機器人數據獲得可執行的策略,充分挖掘在人類操作視頻和機器人數據上統一的決策行為模式。
為了有效利用大量人類數據,本方法設計了預訓練(pre-training)和微調(fine-tuning)的框架,前者可以遵循scaling law快速擴展到大規模的人類操作視頻數據集,后者可以利用少量機器人數據快速遷移至下游任務。整體框架如圖1所示。

△圖1:算法整體框架
本方法從大規模人類操作數據集(如Ego4d)中學習統一的視頻表征,使用大量無動作視頻構建自監督的視頻預測擴散模型作為預訓練任務,并在少量有動作標記的具身數據上進行高效策略微調,能夠使通用人類操作視頻中編碼的物理世界先驗知識適應于具身環境模型構建,在下游任務中利用少量機器人軌跡即可在通用機械臂操作任務集合中獲得優異的性能。
研究方法
本文方法從三個方面利用人類操作數據構建具身世界模型,實現高效的具身策略學習:
- 在大量人類操作數據和少量機器人數據中構建統一的、可泛化、可遷移的視頻表征;
- 構建自監督預測任務進行軌跡層面整體建模,實現人類和機器人通用的具身視頻預測;
- 新穎的擴散架構實現可擴展的人類視頻學習,同時在小規模機器人數據上快速泛化。
人類和機器人數據的統一token化
為了從數據分布極廣的各類視頻數據中提取有效的信息輸入進行世界模型構建,提出構建人類視頻和機器人視頻統一的視頻編碼。
使用VQ-VAE將高維視頻片段壓縮成信息豐富的離散化潛在token,不僅為混合視頻提供了統一的碼本,還減輕了人類和機器人視頻之間的域差異。通過將連續特征轉換為離散空間,提取出人類和機器人操作的共同模式。
此外,通過統一的動作離散化方法將動作空間的連續維度離散化成有序的整數,使機器人的動作可以通過離散的token來表示,為后續的預訓練和微調階段提供了便利。
通過這種方式,能夠將人類視頻中的動態行為模式和機器人的動作指令統一起來,構建出一個能夠處理大規模視頻數據并提取有用特征的框架。見圖2第一階段所示。

△圖2:三階段學習框架
離散擴散模型的視頻預測學習
在視頻預測模型的訓練階段,利用離散擴散模型從大量人類視頻中提取與物理交互有關的普適知識。具體的,給定一段歷史視頻和文本作為 prompts,利用大規模擴散模型預測未來視頻 token 序列。
當模型能很好地理解交互模式并預測到準確的未來軌跡時,智能體能夠對未來可能發生的行為進行預估,從而用該信息去指導下游任務的決策過程。
為了處理信息量豐富的離散視頻編碼,并且支持提出的預訓練及微調的兩階段訓練模式,提出表達力極強的離散擴散模型(Discrete Diffusion)架構進行視頻建模。
模型訓練中通過引入一個掩碼和替換的擴散策略,能夠學習到視頻中的動態變化規律,并生成在潛在空間中具有連貫性的未來視頻token。
這一過程不僅涉及對視頻內容的理解,還包括對視頻上下文的深入分析,從而為機器人策略學習提供了豐富的先驗知識。見圖2第二階段所示。
世界模型驅動的具身策略學習
通過從大規模人類數據集中學習世界模型,模型已經編碼了的普適的視頻預測模式,在下游機器人任務中僅需要依賴少量機器人數據就能夠快速的學習策略。
具體的,提出了基于少量樣本的微調策略,通過凍結預訓練模型并僅調整動作學習網絡的參數,能夠在有限的機器人數據集上快速適應并預測動作序列。
在預訓練階段模型使用Perceiver Transformer作為噪聲擴散模型的主干網絡,在微調階段使用 GPT2作為主干網絡以便于在小規模機器人數據集中進行策略學習。
這一微調過程有效地將從人類視頻中學到的豐富視頻預測知識轉移到機器人控制任務中,顯著提高了機器人在多任務操作中的性能和樣本效率。見圖2第三階段所示。
實驗結果
本方法在單視角視覺觀測的機械臂操作任務集和使用多視角觀測的3D操作任務集合中評估有效性。
結果發現,論文提出的方法可以在人類物體操作和機器人物體操作中成功預測準確的未來運動軌跡,無論是單視角還是多視角,這些都通過一個離散擴散模型生成。
下方視頻顯示了方法在合成人類操作視頻方面的效果。在復雜的人類物體操作場景中,本文方法能夠精確的建模人類手部的運動細節和運動軌跡,從而在構建世界模型中為機器人末端的運動提供指導。

進而,通過人類視頻和機器人視頻的統一token編碼,人類操作視頻的預測學習能夠極大的幫助模型在少量機器人視頻中學習具身世界模型。下方視頻顯示了機器人操作任務中,本方法能夠準確根據自然語言指令對機械臂未來的軌跡進行預測和規劃,從而指導下一階段的機械臂動作預測。
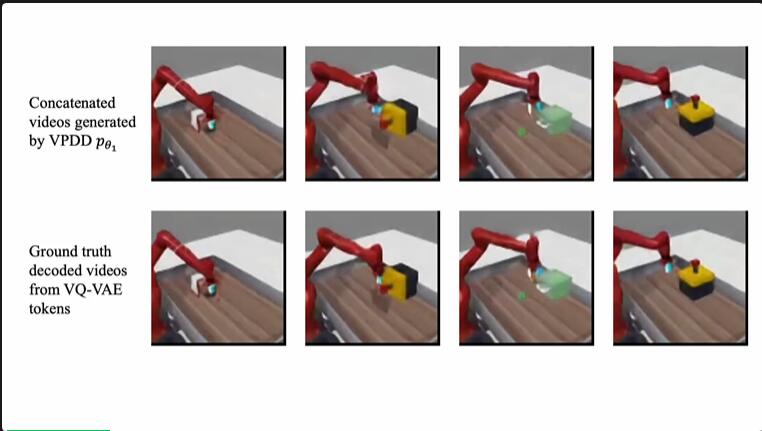
此外,通過對少量真實機械臂操作視頻的學習,世界模型可以快速泛化到對真實機械臂視頻產生準確的預測,從而指導真實機械臂的策略學習。

通過具身世界模型的構建,模型能夠在少量帶有動作標記的數據中進行快速微調,從而使模型能夠產生實際的機器人動作決策序列,指導下游任務的學習。
下面顯示了在RLBench任務中的策略執行效果。通過多視角的視頻預測,世界模型能夠全方位預測機器人的周圍環境變化,從而指導機器人在三維空間中進行復雜的任務決策。


研究總結
該成果提出了一種少樣本的高效具身世界模型架構和訓練方法,通過設計統一token編碼、離散噪聲擴散模型為基礎的運動軌跡(視頻)預訓練、以及少量機器人數據的知識遷移和泛化,能夠使用人類操作視頻的行為模式指導機器人進行決策,從而解決了機器人數據代價昂貴的問題。
提出的方法可以靈活地處理各種視頻輸入的機械臂操作任務,包括單視角2D操作、多視角相機3D操作、真實機械臂操作等,為世界模型邁向機器人做出了重要貢獻。
團隊負責人介紹: 李學龍,中國電信集團CTO、首席科學家,中國電信人工智能研究院(TeleAI)院長。主要關注人工智能、臨地安防、圖像處理、具身智能、噪聲分析。

論文名稱:
Learning an Actionable Discrete Diffusion Policy via Large-Scale Actionless Video Pre-Training
論文鏈接:https://arxiv.org/abs/2402.14407
項目地址:https://video-diff.github.io























