













基于 ?YOLO11 的手語檢測 | 附數(shù)據(jù)集+代碼
YOLO11是Ultralytics YOLO系列實(shí)時(shí)目標(biāo)檢測器的最新迭代,它重新定義了尖端精度、速度和效率的可能性。在以往YOLO版本的令人印象深刻的進(jìn)步基礎(chǔ)上,YOLO11在架構(gòu)和訓(xùn)練方法上引入了重大改進(jìn),使其成為廣泛計(jì)算機(jī)視覺任務(wù)的多功能選擇。

此模型可以做很多很酷的事情,比如:
- 尋找物體:它可以在圖像中定位和識別不同的物體,如汽車、人或樹木。
- 分類事物:它可以告訴你它看到了什么樣的物體,如貓或香蕉。
- 理解物體的形狀:它甚至可以勾勒出物體的確切形狀,如追蹤它。
- 弄清楚姿勢:它可以了解人體的位置,比如他們是站著、坐著還是揮手。
主要特點(diǎn)
- 增強(qiáng)特征提取:YOLO11采用了改進(jìn)的骨干和頸部架構(gòu),增強(qiáng)了特征提取能力,實(shí)現(xiàn)了更精確的目標(biāo)檢測和復(fù)雜任務(wù)的性能。
- 優(yōu)化效率和速度:YOLO11引入了精細(xì)的架構(gòu)設(shè)計(jì)和優(yōu)化的訓(xùn)練流程,提供了更快的處理速度,并在準(zhǔn)確性和性能之間保持了最佳平衡。
- 參數(shù)更少,準(zhǔn)確性更高:隨著模型設(shè)計(jì)的進(jìn)步,YOLO11m在COCO數(shù)據(jù)集上實(shí)現(xiàn)了更高的平均精度均值(mAP),同時(shí)比YOLOv8m使用的參數(shù)減少了22%,使其在不犧牲準(zhǔn)確性的情況下具有計(jì)算效率。
- 適應(yīng)不同環(huán)境:YOLO11可以無縫部署在各種環(huán)境中,包括邊緣設(shè)備、云平臺和支持NVIDIA GPU的系統(tǒng),確保了最大的靈活性。
- 支持任務(wù)范圍廣泛:無論是目標(biāo)檢測、實(shí)例分割、圖像分類、姿態(tài)估計(jì)還是定向目標(biāo)檢測(OBB),YOLO11都旨在應(yīng)對多樣化的計(jì)算機(jī)視覺挑戰(zhàn)。
數(shù)據(jù)集信息
在此項(xiàng)目中使用的美國手語(ASL)數(shù)據(jù)集來源自Roboflow Universe/duyguj/american-sign-language-letters。所有數(shù)據(jù)集中的圖像都預(yù)先標(biāo)記,確保了準(zhǔn)確的訓(xùn)練數(shù)據(jù)。此外,還在Roboflow中應(yīng)用了數(shù)據(jù)增強(qiáng)技術(shù)以增加數(shù)據(jù)集的多樣性,提高了模型的泛化能力。采用了翻轉(zhuǎn)、旋轉(zhuǎn)和亮度調(diào)整等技術(shù)。
詳細(xì)鏈接:https://app.roboflow.com/duyguj/american-sign-language-letters-vouo0/1
該數(shù)據(jù)集包含總共1224張圖像,分為三組:
- 訓(xùn)練集:1008張圖像(82%)
- 驗(yàn)證集:144張圖像(12%)
- 測試集:72張圖像(6%)
(1) 預(yù)處理:
- 自動(dòng)定向:應(yīng)用以確保圖像正確對齊。
- 調(diào)整大小:所有圖像都調(diào)整大小以適應(yīng)640x640像素。
(2) 數(shù)據(jù)增強(qiáng):
每個(gè)訓(xùn)練示例由于增強(qiáng)而有兩個(gè)輸出,包括:
- 旋轉(zhuǎn):在-15°和+15°之間以模擬不同的手姿。
- 曝光:在-10%和+10%之間調(diào)整以適應(yīng)不同的光照條件。
- 模糊:高達(dá)2px以模擬運(yùn)動(dòng)或相機(jī)模糊。
這種設(shè)置旨在通過讓模型接觸多樣化的輸入來提高其泛化能力。
(3) 訓(xùn)練過程
YOLO11模型在此ASL數(shù)據(jù)集上進(jìn)行了微調(diào),專門用于手語目標(biāo)檢測。這個(gè)訓(xùn)練過程包括:
- 數(shù)據(jù)集增強(qiáng):使用Roboflow通過轉(zhuǎn)換來增強(qiáng)數(shù)據(jù)集。
- 模型訓(xùn)練:使用這個(gè)增強(qiáng)的數(shù)據(jù)集訓(xùn)練YOLOv11,并使用單獨(dú)的驗(yàn)證數(shù)據(jù)集來驗(yàn)證性能。
- 測試:訓(xùn)練完成后,模型在專用的測試集上進(jìn)行測試,以評估其預(yù)測未見數(shù)據(jù)的能力。
(4) 性能和觀察
最終模型在隨機(jī)手語圖像和視頻上進(jìn)行了測試,以觀察其在現(xiàn)實(shí)世界中的表現(xiàn)。結(jié)果顯示了在實(shí)時(shí)檢測不同ASL標(biāo)志方面的有希望的結(jié)果,證明了YOLO11架構(gòu)在處理復(fù)雜、基于手勢的任務(wù)方面的有效性。
設(shè)置和初始化
(1) 訪問GPU
我們可以使用nvidia-smi命令來做到這一點(diǎn)。如果遇到任何問題,請導(dǎo)航到“編輯”->“筆記本設(shè)置”->“硬件加速器”,將其設(shè)置為GPU。
# “注意:此設(shè)置適用于kaggle”
!pip install ultralytics supervision roboflow
from IPython import display
display.clear_output()
!pip install ultralytics --quiet
import ultralytics
ultralytics.checks()(2) 加載數(shù)據(jù)集
① 配置API密鑰以加載數(shù)據(jù)集
為了微調(diào)YOLO11,你需要提供你的Roboflow API密鑰。請按照以下步驟操作:
- 前往你的Roboflow設(shè)置頁面,點(diǎn)擊復(fù)制,這將把你的私有密鑰放在剪貼板中。
- 在Colab中,轉(zhuǎn)到左側(cè)面板并點(diǎn)擊“秘密”(??)。
- 在名稱為ROBOFLOW_API_KEY下存儲(chǔ)Roboflow API密鑰。 Roboflow:轉(zhuǎn)到你的Roboflow數(shù)據(jù)集下載 -> 選擇YOLO模型 -> 選擇顯示下載代碼 -> 點(diǎn)擊復(fù)制。 在Colab中:轉(zhuǎn)到左側(cè)面板并點(diǎn)擊“秘密”(??)。
- 在一個(gè)用戶名下存儲(chǔ)Roboflow API密鑰。
- 在Kaggle中:轉(zhuǎn)到“插件”→“秘密”→“添加秘密”(??),并存儲(chǔ)你的Kaggle API密鑰和用戶名。
# Save the API key in Kaggle
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_value_0 = user_secrets.get_secret("my_api_key")# Roboflow Dataset API Code
!pip install roboflow --quiet
from roboflow import Roboflow
rf = Roboflow(secret_value_0)
project = rf.workspace("duyguj").project("american-sign-language-letters-vouo0")
version = project.version(1)
dataset = version.download("yolov11")② 模型訓(xùn)練
# Changing to the working directory in Kaggle
%cd /kaggle/working
# Training the YOLO model
!yolo task=detect mode=train model=yolo11n.pt data=/kaggle/working/American-Sign-Language-Letters-1/data.yaml epochs=10 imgsz=640 plots=True
#Results saved to runs/detect/train
#Learn more at https://docs.ultralytics.com/modes/trainfrom IPython.display import Image as IPyImage
# Display the confusion matrix image from the specified directory in Kaggle
IPyImage(filename='/kaggle/working/runs/detect/train/confusion_matrix.png', width=1000)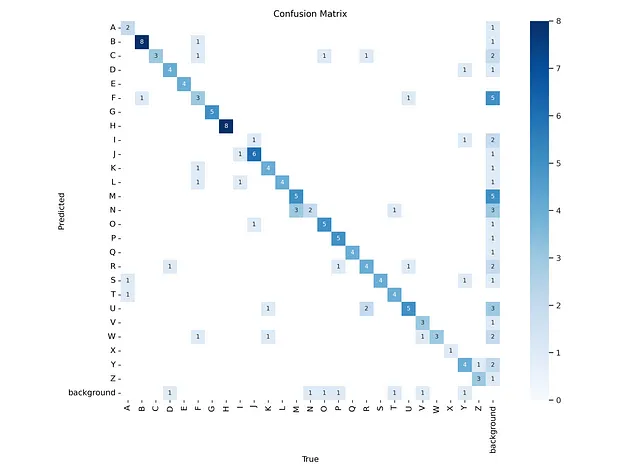
IPyImage(filename=f'/kaggle/working/runs/detect/train/results.png', width=1000)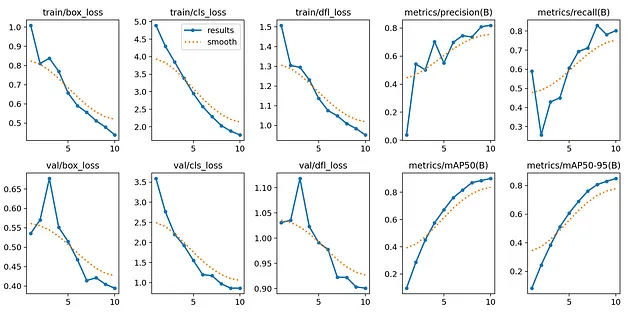
IPyImage(filename=f'/kaggle/working/runs/detect/train/val_batch0_pred.jpg', width=1000)
③ 預(yù)測
# Run the prediction task on Test Data
!yolo task=detect mode=predict model=/kaggle/working/runs/detect/train/weights/best.pt conf=0.25 source=/kaggle/working/American-Sign-Language-Letters-1/test/images save=True
#Results saved to runs/detect/predict
#?? Learn more at https://docs.ultralytics.com/modes/predictimport glob
import os
from IPython.display import Image as IPyImage, display
# Get the latest prediction folder for detection in Kaggle
latest_folder = max(glob.glob('/kaggle/working/runs/detect/predict*/'), key=os.path.getmtime)
# Display images from the prediction folder
for img in glob.glob(f'{latest_folder}/*.jpg')[15:18]:
display(IPyImage(filename=img, width=300))

完整代碼:https://www.kaggle.com/code/duygujones/sign-language-detection-using-yolo11




























