80后聊架構:增加線程到底能不能提升吞吐量? | 架構師之路
《架構師之路:架構設計中的100個知識點》四:性能與擴展性,線程數與吞吐量
之前聊了,啥時候應該優化延時(Latency),啥時候應該優化吞吐量(Throughput)。
畫外音:短視頻二維碼附在文末。
有一些評論,值得和大家擴展討論下:
- 有人說,延時與吞吐量是一回事,說延時下去了,吞吐量自然就上來了;
- 有人說,增加線程數,吞吐量就上來了;
- 有人說,增加線程數,吞吐量未必上來;

1. 延時和吞吐量,是評估啥的指標?
再次強調一下,在性能優化中:
- 一個用戶慢,就去優化延時。
- 多個用戶扛不住,就去優化吞吐量。
- 延時,是偏性能(performance)的指標。
- 吞吐量,是偏擴展性(scalability)的指標。
performance和scalability,評估維度并不一樣。
前端架構,為什么聊performance更多?
前端FE,Android,IOS的童鞋,經常說提升performance,很少說提升scalability。
壓縮資源,緩存圖片,異步加載,Webpack代碼拆分,PWA等等這些技術,都是提升performance的,服務好一個用戶,讓一個用戶速度快。
后端架構,要不要提升performance,當然要。數據庫訪問200ms,引入緩存20ms,速度更快了。
后端架構,為什么聊scalability會更多?
因為系統難點不在于1個用戶的延時是200ms還是20ms,難的是:
- 數據庫里有1億個用戶時,系統扛不扛得住;
- 10萬個用戶同時訪問時,系統扛不扛得住;
而這些,就是scalability的范疇。
這,是后端架構設計的核心,是scalability相關的知識點,也是我在“100個架構知識點”里要重點講的內容。
2. 線程數和吞吐量,到底是什么關系?
我在短視頻里舉例:“增加線程數是提高吞吐量的方法之一,1個線程1秒鐘處理5個請求,吞吐量是5,增加到10個線程,吞吐量變成50”。
有朋友指出我說的不對,說增加線程數,有時候能提升吞吐量,有時候不能提升吞吐量。
這位朋友說的對,我表達不嚴密,那么問題來:
- 啥時候增加線程數能提升吞吐量,啥時候不能?
- 設置線程數的依據是什么,是不是越大越好?
- 線程數設為多少,吞吐量能最大?
下面稍微展開詳細說下。
首先,工作線程數是不是設置得越大越好?
答案顯然是否定的。
- 服務器CPU核數有限,能夠同時并發的線程數有限,單核CPU設置1000個工作線程沒有意義;
- 線程切換有開銷,如果線程切換過于頻繁,反而會使性能降低;
第二個問題,調用sleep()函數的時候,線程是否一直占用CPU?
不占用,休眠時會把CPU讓出來,給其他需要CPU資源的線程使用。
不止sleep,一些阻塞調用,例如網絡編程中的:
- 阻塞accept(),等待客戶端連接;
- 阻塞recv(),等待下游回包;
都會讓出CPU資源。
第三個問題,單核CPU,設置多線程有沒有意義?單核CPU,設置多線程能否提高并發性能?
即使是單核,使用多線程也是有意義的,大多數情況也能提高并發。
- 其一,多線程編碼可以讓代碼更加清晰,例如:IO線程收發包,Worker線程進行任務處理,Timeout線程進行超時檢測;
- 其二,如果有一個任務一直占用CPU資源在進行計算,此時增加線程并不能增加并發,例如以下代碼會一直占用CPU,并使得CPU占用率達到100%:
while(1){ i++; }- 其三,通常來說,Worker線程一般不會一直占用CPU進行計算,此時即使CPU是單核,增加Worker線程也能夠提高并發,因為這個線程在休息的時候,其他的線程可以繼續工作;
第四個問題,常見服務線程模型是怎樣的?
了解常見的服務線程模型,有助于理解服務并發的原理,一般來說互聯網常見的服務線程模型是:IO線程與工作線程通過任務隊列解耦模型。
畫外音:還有一種是無鎖純異步,可參考lighttpd的單線程模式,這種模型完全無鎖,但無法利用多核優勢。
這類線程模型,示例如下:
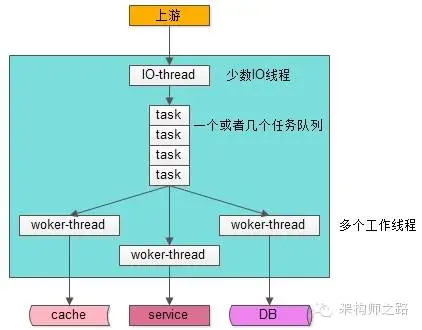
如上圖,很多Web-Server與服務框架都是使用這樣的一種“IO線程與Worker線程通過隊列解耦”類線程模型:
- 有少數幾個IO線程監聽上游發過來的請求,并進行收發包(生產者);
- 有一個或者多個任務隊列,作為IO線程與Worker線程異步解耦的數據傳輸通道(臨界資源);
- 有多個工作線程執行真正的任務(消費者);
這個線程模型應用很廣,其特點是,工作線程內部是同步阻塞執行任務的,因此可以通過增加Worker線程數來增加并發能力。
畫外音:純異步模型未來再聊。
“IO線程與工作線程通過隊列解耦”類線程模型,工作線程的工作模式是怎么樣的?
了解工作線程的工作模式,對量化分析線程數的設置非常有幫助:
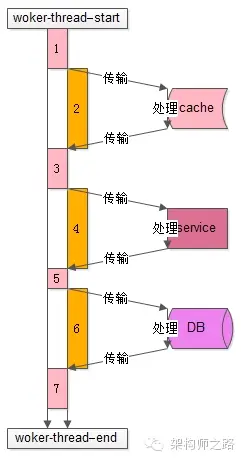
上圖是一個典型的工作線程的處理過程,從開始處理start到結束處理end,該任務的處理共有7個步驟:
- 從工作隊列里拿出任務,進行一些本地初始化計算,例如http協議分析、參數解析、參數校驗等;
- 訪問cache拿一些數據;
- 拿到cache里的數據后,再進行一些本地計算,這些計算和業務邏輯相關;
- 通過RPC調用下游service再拿一些數據,或者讓下游service去處理一些相關的任務;
- RPC調用結束后,再進行一些本地計算,怎么計算和業務邏輯相關;
- 訪問DB進行一些數據操作;
- 操作完數據庫之后做一些收尾工作,同樣這些收尾工作也是本地計算,和業務邏輯相關;
分析整個處理的時間軸,會發現:
- 其中1,3,5,7步驟中(上圖中粉色時間軸),線程進行本地業務邏輯計算時需要占用CPU;
- 而2,4,6步驟中(上圖中橙色時間軸),訪問cache、service、DB過程中線程處于一個等待結果的狀態,不需要占用CPU;
如何量化分析,并合理設置工作線程數呢?
通過上面的分析,Worker線程在執行的過程中:
- 有一部計算時間需要占用CPU;
- 另一部分等待時間不需要占用CPU;
通過量化分析,例如打日志進行統計,可以統計出整個Worker線程執行過程中這兩部分時間的比例,例如:
- 執行計算,占用CPU的時間(粉色時間軸)是100ms;
- 等待時間,不占用CPU的時間(橙色時間軸)也是100ms;
得到的結果是,這個線程計算和等待的時間是1:1,即有50%的時間在計算(占用CPU),50%的時間在等待(不占用CPU):
- 假設此時是單核,則設置為2個工作線程就可以把CPU充分利用起來,讓CPU跑到100%;
- 假設此時是N核,則設置為2N個工作線程就可以把CPU充分利用起來,讓CPU跑到N*100%;
當當當當!!!
結論來了:
N核服務器,通過執行業務的單線程分析出本地計算時間為x,等待時間為y,則工作線程數(線程池線程數)設置為 N*(x+y)/x,能讓CPU的利用率最大化。
一般來說,非CPU密集型的業務(加解密、壓縮解壓縮、搜索排序等業務是CPU密集型的業務),瓶頸都在后端數據庫訪問或者RPC調用,本地CPU計算的時間很少,所以設置幾十或者幾百個工作線程是能夠提升吞吐量的。
你,學廢了嗎?