北大王選最新OpenAD!助力自動駕駛邁向開放3D世界
寫在前面 & 筆者的個人理解
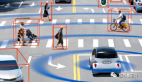
開放世界自動駕駛包括域泛化和開放詞匯。領域泛化是指自動駕駛系統在不同場景和傳感器參數配置下的能力。開放詞匯是指識別訓練中沒有遇到的各種語義類別的能力。在本文中,我們介紹了OpenAD,這是第一個用于3D目標檢測的現實世界開放世界自動駕駛基準。OpenAD建立在與多模態大型語言模型(MLLM)集成的角案例發現和標注管道之上。所提出的管道以統一的格式為五個具有2000個場景的自動駕駛感知數據集標注corner case目標。此外,我們設計評估方法,評估各種2D和3D開放世界和專業模型。此外,我們提出了一種以視覺為中心的3D開放世界目標檢測基線,并通過融合通用和專用模型進一步引入了一種集成方法,以解決OpenAD基準現有開放世界方法精度較低的問題。
- 項目鏈接:https://github.com/VDIGPKU/OpenAD
總結來說,本文的主要貢獻如下:
- 提出了一個開放世界基準,同時評估目標檢測器的領域泛化和開放詞匯表能力。據我們所知,這是3D開放世界物體檢測的第一個現實世界自動駕駛基準。
- 設計了一個與MLLM集成的標注管道,用于自動識別極端情況場景,并為異常目標提供語義標注。
- 提出了一種結合二維開放世界模型的三維開放世界感知基線方法。此外,我們分析了開放世界和專業模式的優缺點,并進一步介紹了一種融合方法來利用這兩種優勢。
相關工作回顧
Benchmark for Open-world Object Detection
2D基準。各種數據集已被用于2D開放詞匯表目標檢測評估。最常用的是LVIS數據集,它包含1203個類別。
在自動駕駛領域,如表1所示,也提出了許多數據集。其中,CODA是一個用于自動駕駛中二維物體檢測的道路拐角案例數據集,包含1500個道路駕駛場景,其中包含34個類別的邊界框注釋。然而,一些數據集只提供語義分割注釋,沒有特定的實例,或者將目標注釋為異常但缺乏語義標簽。此外,從真實世界的駕駛數據中收集的數據集規模較小,而來自CARLA等模擬平臺的合成數據缺乏真實性,因此難以進行有效的評估。相比之下,我們的OpenAD提供了來自真實世界數據的大規模2D和3D邊界框注釋,用于更全面的開放世界目標檢測評估。

3D基準。3D開放世界基準測試可分為兩類:室內和室外場景。對于室內場景,SUN-RGBD和ScanNet是兩個經常用于開放世界評估的真實世界數據集,分別包含約700和21個類別。對于戶外或自動駕駛場景,AnoVox是一個合成數據集,包含35個類別的實例掩碼,用于開放世界評估。然而,由于模擬資產有限,合成數據的質量和實例多樣性不如真實世界的數據。除了AnoVox之外,現有的用于自動駕駛的真實數據3D目標檢測數據集只包含少數目標類別,很難用于評估開放世界模型。為了解決這個問題,我們提出了OpenAD,它由真實世界的數據構建而成,包含206個出現在自動駕駛場景中的不同corner-case類別。
2D Open-world Object Detection Methods
為了解決分布外(OOD)或異常檢測問題,早期的方法通常采用決策邊界、聚類等來發現OOD目標。最近的方法采用文本編碼器,即CLIP,將相應類別標簽的文本特征與框特征對齊。具體來說,OVR-CNN將圖像特征與字幕嵌入對齊。GLIP將目標檢測和短語基礎統一用于預訓練。OWL ViT v2使用預訓練的檢測器在圖像-文本對上生成偽標簽,以擴大檢測數據用于自訓練。YOLO World采用YOLO類型的架構進行開放詞匯檢測,并取得了良好的效率。然而,所有這些方法在推理過程中都需要預定義的目標類別。
最近,一些開放式方法提出利用自然語言解碼器提供語言描述,這使它們能夠直接從RoI特征生成類別標簽。更具體地說,GenerateU引入了一種語言模型,可以直接從感興趣的區域生成類標簽。DetClipv3引入了一個目標字幕器,用于在推理過程中生成類標簽和用于訓練的圖像級描述。VL-SAM引入了一個無需訓練的框架,其中注意力圖作為提示。
3D Open-world Object Detection Methods
與2D開放世界目標檢測任務相比,由于訓練數據集有限和3D環境復雜,3D開放世界目標探測任務更具挑戰性。為了緩解這個問題,大多數現有的3D開放世界模型都來自預訓練的2D開放世界模型,或者利用豐富的2D訓練數據集。
例如,一些室內3D開放世界檢測方法,如OV-3DET和INHA,使用預訓練的2D目標檢測器來引導3D檢測器找到新的目標。同樣,Coda利用3D box幾何先驗和2D語義開放詞匯先驗來生成新類別的偽3D box標簽。FM-OV3D利用穩定擴散生成包含OOD目標的數據。至于戶外方法,FnP在訓練過程中使用區域VLMs和貪婪盒搜索器為新類生成注釋。OV-Uni3DETR利用來自其他2D數據集的圖像和由開放詞匯檢測器生成的2D邊界框或實例掩碼。
然而,這些現有的3D開放詞匯檢測模型在推理過程中需要預定義的目標類別。為了解決這個問題,我們引入了一種以視覺為中心的開放式3D目標檢測方法,該方法可以在推理過程中直接生成無限的類別標簽。
OpenAD概覽


Baseline Methods of OpenAD
Vision-Centric 3D Open-ended Object Detec- tion
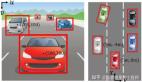
由于現有3D感知數據的規模有限,直接訓練基于視覺的3D開放世界感知模型具有挑戰性。我們利用具有強大泛化能力的現有2D模型來解決這個問題,并為3D開放世界感知提出了一個以視覺為中心的基線。
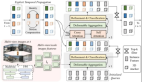
如圖4所示,最初采用任意現有的二維開放世界目標檢測方法來獲得二維邊界框及其相應的語義標簽。同時,緩存由2D模型的圖像編碼器生成的圖像特征圖。隨后,引入了一個結合了多個特征和一些可訓練參數的2D到3D Bbox轉換器,將2D box轉換為3D box。
具體來說,我們使用現有的深度估計模型,如ZoeDepth、DepthAnything和UniDepth,通過2D框獲得裁剪圖像的深度圖。我們還包括一個可選的分支,該分支利用激光雷達點云和線性擬合函數,通過將點云投影到圖像上來細化深度圖。同時,為了消除2D邊界框內不屬于前景目標的區域,我們利用Segment Anything Model(SAM)以2D框為提示對目標進行分割,從而產生分割掩碼。之后,我們可以使用像素坐標、深度圖和相機參數為分割掩模構建偽點云。我們將偽點云投影到特征圖和深度圖上,并通過插值將特征分配給每個點。然后,我們采用PointNet來提取偽點云的特征fp。同時,2D邊界框內的深度圖和特征圖沿著通道維度連接,其特征fc是通過卷積和全局池化得到的。最后,我們利用MLP來預測具有fp和fc級聯特征的目標的3D邊界框。
在此基線中,2D到3D Bbox Converter中只有少數參數是可訓練的。因此,培訓成本低。此外,在訓練過程中,每個3D目標都充當此基線的數據點,從而可以直接構建多域數據集訓練。
General and Specialized Models Fusion
在實驗中,我們發現現有的開放世界方法或通用模型在處理屬于常見類別的目標方面不如閉集方法或專用模型,但它們表現出更強的領域泛化能力和處理極端情況的能力。也就是說,現有的通用和專用模型是相輔相成的。因此,我們利用它們的優勢,通過結合兩種模型的預測結果,提出了一個融合基線。具體來說,我們將兩種模型的置信度得分對齊,并使用雙閾值(即IoU和語義相似性)執行非最大抑制(NMS),以過濾重復項。
實驗結果




結論
在本文中,我們介紹了OpenAD,這是第一個用于3D目標檢測的開放世界自動駕駛基準。OpenAD建立在與多模態大型語言模型集成的角案例發現和注釋管道之上。該管道以格式對齊五個自動駕駛感知數據集,并為2000個場景注釋角案例目標。此外,我們還設計了評估方法,并分析了現有開放世界感知模型和自動駕駛專業模型的優缺點。此外,為了應對訓練3D開放世界模型的挑戰,我們提出了一種結合2D開放世界模型進行3D開放世界感知的基線方法。此外,我們引入了一種融合基線方法,以利用開放世界模型和專用模型的優勢。
通過對OpenAD進行的評估,我們觀察到現有的開放世界模型在域內上下文中仍然不如專門的模型,但它們表現出更強的域泛化和開放詞匯能力。值得注意的是,某些模型在域內基準測試上的改進是以犧牲其開放世界能力為代價的,而其他模型則不是這樣。這種區別不能僅僅通過測試域內基準來揭示。
我們希望OpenAD可以幫助開發超越專業模型的開放世界感知模型,無論是在同一領域還是跨領域,無論是對于可見還是未知的語義類別。