













科研也完了,AI暴虐170位人類(lèi)專(zhuān)家!Nature子刊:大模型精準(zhǔn)預(yù)測(cè)研究結(jié)果,準(zhǔn)確率高達(dá)81%
在現(xiàn)代化工具的幫助下,科研人員的群體規(guī)模、效率都有顯著提升,發(fā)表科學(xué)文獻(xiàn)的數(shù)量幾乎是呈指數(shù)級(jí)增長(zhǎng),而人類(lèi)的閱讀效率卻幾乎沒(méi)有提升,新入行的研究人員一下子就要面對(duì)過(guò)去數(shù)十年的研究成果。
為了更快地掌握行業(yè)動(dòng)態(tài),研究者往往會(huì)考慮優(yōu)先閱讀那些更知名的、影響力更大的論文,從而會(huì)忽視掉很多潛在的、具有顛覆性的發(fā)現(xiàn)。
以ChatGPT為首的大模型算是一個(gè)很有潛力的輔助閱讀、科研的解決方案,其通用能力覆蓋了專(zhuān)業(yè)考試、有限推理、翻譯、解決數(shù)學(xué)問(wèn)題,甚至還能寫(xiě)代碼。
已有的研究考察了大模型在科研領(lǐng)域的表現(xiàn),但基準(zhǔn)數(shù)據(jù)集大多屬于「回顧性質(zhì)」的,比如MMLU、PubMedQA和MedMCQA,主要以問(wèn)答的形式來(lái)評(píng)估模型的核心知識(shí)檢索和推理能力,

然而,這些基準(zhǔn)都不適合評(píng)估模型前瞻的能力,輔助科研需要整合嘈雜但相互關(guān)聯(lián)的發(fā)現(xiàn),比人類(lèi)專(zhuān)家更擅長(zhǎng)預(yù)測(cè)新結(jié)果。
最近,倫敦大學(xué)學(xué)院(UCL)的研究人員在Nature Human Behaviour期刊上發(fā)布了一個(gè)前瞻性基準(zhǔn)BrainBench,在神經(jīng)科學(xué)領(lǐng)域考察模型的預(yù)測(cè)能力。

論文鏈接:https://www.nature.com/articles/s41562-024-02046-9
結(jié)果發(fā)現(xiàn),大模型的表現(xiàn)遠(yuǎn)遠(yuǎn)超越了人類(lèi)專(zhuān)家水平,平均準(zhǔn)確率達(dá)到了81%,而人類(lèi)的平均準(zhǔn)確率只有63%
即使研究團(tuán)隊(duì)將人類(lèi)的反饋限制為僅對(duì)特定神經(jīng)科學(xué)領(lǐng)域、具有最高專(zhuān)業(yè)知識(shí)的人,神經(jīng)科學(xué)家的準(zhǔn)確率仍然低于大模型,為 66%
和人類(lèi)專(zhuān)家類(lèi)似的是,如果大模型對(duì)預(yù)測(cè)結(jié)果表示具有高度自信時(shí),回答結(jié)果的正確率也更高,也就是說(shuō),大模型完全可以輔助人類(lèi)做科研新發(fā)現(xiàn)。
最重要的是,這種方法并不特定于某一個(gè)學(xué)科,其他知識(shí)密集型任務(wù)上也可以使用。
科研結(jié)果預(yù)測(cè)
即使是人類(lèi)專(zhuān)家,在神經(jīng)科學(xué)領(lǐng)域進(jìn)行預(yù)測(cè)時(shí),仍然是非常有挑戰(zhàn)性的,主要有五個(gè)難題:
1. 領(lǐng)域內(nèi)通常有成千上萬(wàn)篇的相關(guān)科學(xué)論文;
2. 存在個(gè)別不可靠的研究結(jié)果,可能無(wú)法復(fù)制;
3. 神經(jīng)科學(xué)是跨領(lǐng)域?qū)W科(multi-level endeavour),涵蓋行為(behaviour)和分子機(jī)制(molecular mechanisms);
4. 分析方法多樣且可能非常復(fù)雜;
5. 可用的實(shí)驗(yàn)方法很多,包括不同的腦成像技術(shù)、損傷研究、基因修改、藥理干預(yù)等。
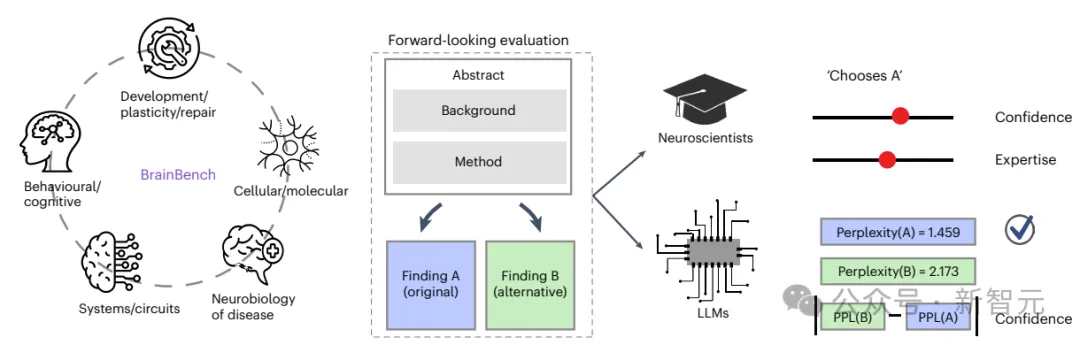
為了滿(mǎn)足對(duì)大模型的測(cè)試需要,針對(duì)上述難題,研究人員開(kāi)發(fā)的BrainBench基準(zhǔn)總共納入了200個(gè)由人類(lèi)專(zhuān)家精心設(shè)計(jì)的、2023年發(fā)表在《神經(jīng)科學(xué)雜志》上的測(cè)試案例,以及額外100個(gè)由GPT-4生成的測(cè)試案例,涵蓋了五個(gè)神經(jīng)科學(xué)領(lǐng)域:行為/認(rèn)知、系統(tǒng)/回路、疾病神經(jīng)生物學(xué)、細(xì)胞/分子以及發(fā)展/可塑性/修復(fù)。
對(duì)于每個(gè)測(cè)試案例,研究人員會(huì)修改已發(fā)表的摘要,創(chuàng)建一個(gè)變更后的版本,在不改變方法和背景的情況下,大幅改變研究結(jié)論。
比如說(shuō),與原始摘要相比,變更后的摘要可能會(huì)交換兩個(gè)大腦區(qū)域在結(jié)果中的作用,反轉(zhuǎn)結(jié)果的方向(將「減少」替換為「增加」)等。任何改動(dòng)都需要保持摘要的連貫性,有時(shí)還需要進(jìn)行多次改動(dòng)(比如將多個(gè)減少替換為增加)。
也就是說(shuō),變更后的摘要需要在實(shí)證上有所不同,但邏輯上并不矛盾。
測(cè)試者需要在原始摘要和修改版本之間做出選擇,人類(lèi)專(zhuān)家和大型語(yǔ)言模型的任務(wù)是從兩個(gè)選項(xiàng)中選擇正確的,即原始版本;人類(lèi)專(zhuān)家需要做出選擇,并提供信心和專(zhuān)業(yè)水平的評(píng)分;大型語(yǔ)言模型則根據(jù)選擇的摘要的困惑度(即模型認(rèn)為文本段落的驚訝程度較低)來(lái)評(píng)分,自信程度與兩個(gè)選項(xiàng)之間困惑度差異成正比。
部分GPT-4提示如下:
你的任務(wù)是修改一篇神經(jīng)科學(xué)研究論文的摘要,使得修改后的內(nèi)容顯著改變研究結(jié)果,但不改變方法和背景。這樣我們可以測(cè)試人工智能對(duì)摘要主題領(lǐng)域的理解能力。
... ... 摘要的開(kāi)頭是背景和方法,所以這部分摘要不應(yīng)被修改。不要改變前幾句話(huà)。
我們希望摘要在實(shí)證上是錯(cuò)誤的,但邏輯上并不矛盾。
要找到論文的原始結(jié)果,需要一些神經(jīng)科學(xué)的洞察力,而不僅僅是一般的推理能力。因此,你所做的修改不應(yīng)該評(píng)估人工智能的推理能力,而是它對(duì)神經(jīng)科學(xué)和大腦工作原理的知識(shí)。
注意不要做出改變結(jié)果但可能在作者的研究中仍然發(fā)生的修改。例如,關(guān)于學(xué)習(xí)的fMRI摘要可能提到海馬體而不是紋狀體。然而,紋狀體可能也是活躍的,但沒(méi)有在摘要中報(bào)告,因?yàn)樗皇茄芯康闹攸c(diǎn)。
你所做的修改不應(yīng)該從摘要的其余部分被識(shí)別或解碼出來(lái)。因此,如果你做了修改,確保你改變了所有可以揭示原始摘要的內(nèi)容。
在你改變單詞時(shí)注意冠詞的使用(a/an)。
確保你的修改保持句子間的一致性和正確的語(yǔ)法,修改不應(yīng)該與摘要的整體意義相矛盾或混淆。
避免進(jìn)行不需要理解科學(xué)概念的瑣碎修改,修改應(yīng)該反映出對(duì)主題的深刻理解。
在進(jìn)行修改時(shí),不要錯(cuò)過(guò)摘要中的任何重要結(jié)果或發(fā)現(xiàn)。每一個(gè)重要點(diǎn)都應(yīng)該在你的修改中得到體現(xiàn)。實(shí)驗(yàn)結(jié)果
人類(lèi)神經(jīng)科學(xué)專(zhuān)家經(jīng)過(guò)專(zhuān)業(yè)能力和參與度的篩選,共有171名參與者通過(guò)了所有檢查并被納入分析結(jié)果,大多數(shù)人類(lèi)專(zhuān)家是博士生、博士后研究員或教職/學(xué)術(shù)人員。
在BrainBench上,大型語(yǔ)言模型的性能表現(xiàn)都超過(guò)了人類(lèi)專(zhuān)家,平均準(zhǔn)確率為81.4%,而人類(lèi)專(zhuān)家的平均準(zhǔn)確率為63.4%;當(dāng)把人類(lèi)回答限制在那些自報(bào)專(zhuān)業(yè)水平在前20%的測(cè)試項(xiàng)時(shí),準(zhǔn)確率上升到了66.2%,但仍然低于大型語(yǔ)言模型的水平。

參數(shù)較小的模型,比如70億參數(shù)的Llama2-7B和Mistral-7B,表現(xiàn)得與更大的模型相當(dāng),其性能也比尺寸更小的模型要好,小模型可能缺乏捕捉關(guān)鍵數(shù)據(jù)模式的能力;而為聊天或指令優(yōu)化的模型表現(xiàn)得比基準(zhǔn)模型要差。
研究人員推測(cè),讓大型語(yǔ)言模型適應(yīng)自然語(yǔ)言對(duì)話(huà)可能會(huì)阻礙其科學(xué)推理能力。
按子領(lǐng)域和參與者類(lèi)型劃分時(shí),大型語(yǔ)言模型在每個(gè)子領(lǐng)域中的表現(xiàn)也都優(yōu)于人類(lèi)專(zhuān)家。
在測(cè)試時(shí),為了防止基準(zhǔn)測(cè)試本身可能是訓(xùn)練集的一部分,研究人員采用zlib-perplexity ratio(困惑度比率)來(lái)評(píng)估大型語(yǔ)言模型是否記住了某些段落。
該值可以衡量文本數(shù)據(jù)不可知壓縮率與大型語(yǔ)言模型計(jì)算的特定數(shù)據(jù)困惑度之間的差異,如果某個(gè)段落難以壓縮,但模型給出的困惑度教低,就代表模型是通過(guò)記憶來(lái)回答問(wèn)題。

從結(jié)果來(lái)看,沒(méi)有跡象表明大型語(yǔ)言模型見(jiàn)過(guò)并記住了BrainBench
研究人員還進(jìn)一步確認(rèn)了大語(yǔ)言模型在2023年早些時(shí)候發(fā)表的項(xiàng)目上并沒(méi)有表現(xiàn)得更好(2023年1月與10月相比)
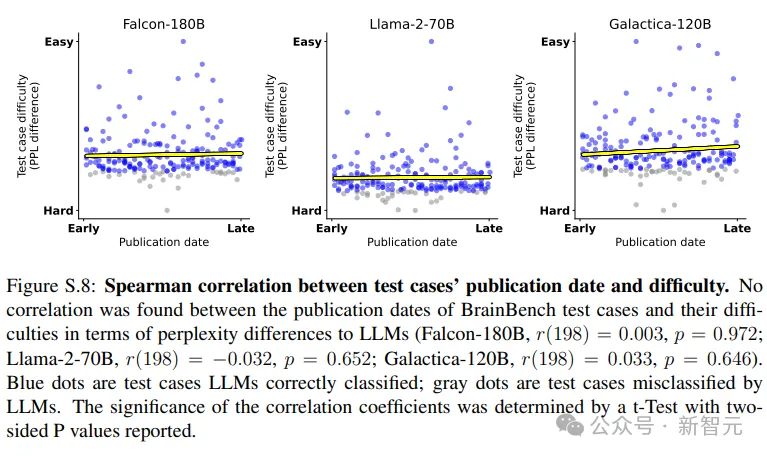
總之,檢查結(jié)果表明,對(duì)于大型語(yǔ)言模型來(lái)說(shuō),BrainBench的數(shù)據(jù)是新的,沒(méi)見(jiàn)過(guò)的。
為了評(píng)估大型語(yǔ)言模型的預(yù)測(cè)是否經(jīng)過(guò)校準(zhǔn),研究人員檢查了置信度與準(zhǔn)確性之間的關(guān)聯(lián)性,結(jié)果發(fā)現(xiàn)與人類(lèi)專(zhuān)家一樣,所有大型語(yǔ)言模型都展現(xiàn)出準(zhǔn)確性和置信度之間的正相關(guān)性。

當(dāng)大型語(yǔ)言模型對(duì)自己的決策有信心時(shí),更有可能做出正確的選擇。
此外,研究人員還在個(gè)體層面上擬合了模型困惑度差異與正確性之間的邏輯回歸,以及人類(lèi)置信度與正確性之間的邏輯回歸,能夠觀察到顯著的正相關(guān)性,證實(shí)了模型和人類(lèi)都是經(jīng)過(guò)校準(zhǔn)的。



























