













Go 語言下的 Redis 跳表設計與實現
在現代高性能數據庫和緩存系統中,跳表(Skip List)作為一種高效的有序數據結構,被廣泛應用于快速查找、插入和刪除操作。Redis 是一個開源的鍵值對存儲系統,它支持多種數據類型,并以其出色的性能而聞名。其中,Redis 使用了跳表來實現有序集合(Sorted Set),以保證其高效的數據處理能力。
本文將詳細介紹如何使用 Go 語言從零開始實現一個類似于 Redis 的跳表。我們將探討跳表的基本原理、設計思路以及具體的實現方法。通過本篇文章的學習,你不僅能夠了解跳表的工作機制,還能夠在實際項目中應用這一強大的數據結構。

定義基礎數據結構
redis中跳表通過score標識元素的大小,通過redis obj維護節點的信息,與此同時為了保證查詢的高效,它會為每個節點維護一份隨機高度的索引記錄當前節點的某個前驅節點:
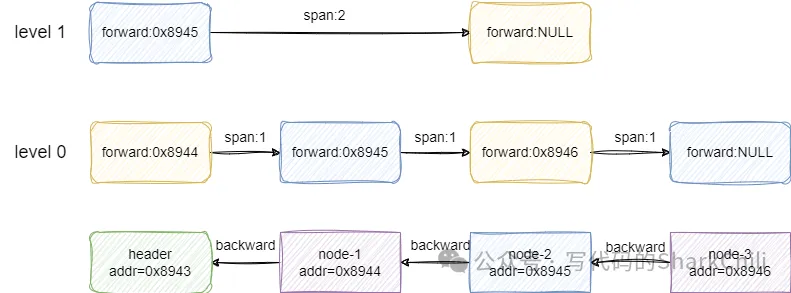
對應我們給出節點的代碼實現:
/*
*
跳表節點的定義
*/
type zskiplistNode struct {
//記錄元素的redis指針
obj *robj
//記錄當前元素的數值,代表當前元素的優先級
score float64
//指向當前元素的前驅節點,即小于當前節點的元素
backward *zskiplistNode
//用一個zskiplistLevel數組維護本屆點各層索引信息
level []zskiplistLevel
}zskiplistLevel的代碼實現比較簡單,通過forward 記錄本層索引的前驅節點,并用span維護當前節點需要跨幾步才能走到該前驅節點:
type zskiplistLevel struct {
//記錄本層索引的前驅節點的指針
forward *zskiplistNode
//標識節點的本層索引需要跨幾步才能到達該節點
span int64
}通過上述概念構成無數個節點即稱為跳表,如下圖所示,各個節點都用一個level數組記錄本層索引到前驅節點的地址和跨度,而跳表也用一個header和tail指針維護跳表的頭尾節點:
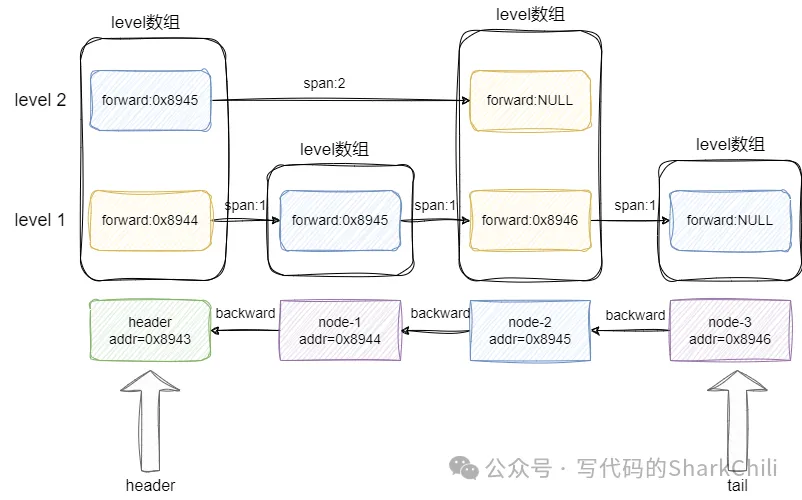
對應的跳表結構體的代碼如下所示:
type zskiplist struct {
//指向跳表的頭節點
header *zskiplistNode
//指向跳表的尾節點
tail *zskiplistNode
//維護跳表的長度
length int64
//維護跳表當前索引的最高高度
level int
}實現初始化方法
對應的我們也給出跳表的初始化代碼,大體邏輯是初始化跳表之后,初始化一個全空的索引和維護跳表的各種初始化信息,對應的筆者也對此代碼做了詳盡的注釋,讀者可自行參閱:
func zslCreate() *zskiplist {
var j int
//初始化跳表結構體
zsl := new(zskiplist)
//索引默認高度為1
zsl.level = 1
//跳表元素初始化為0
zsl.length = 0
//初始化一個頭節點socre為0,元素為空
zsl.header = zslCreateNode(ZSKIPLIST_MAXLEVEL, 0, nil)
/**
基于跳表最大高度32初始化頭節點的索引,
使得前驅指針指向null 跨度也設置為0
*/
for j = 0; j < ZSKIPLIST_MAXLEVEL; j++ {
zsl.header.level[j].forward = nil
zsl.header.level[j].span = 0
}
//頭節點的前驅節點指向null,代表頭節點之前沒有任何元素
zsl.header.backward = nil
//初始化尾節點
zsl.tail = nil
return zsl
}跳表插入操作
插入新節點時,本質上就是通過各層索引找到小于插入節點x的score的最大值,并記錄到update數組中,同時將頭節點跨到update數組元素的跨度值記錄到rank數組中,如下圖所示,假如我們插入節點1.5,那么對應各層索引的在update和rank兩個數組中維護的信息是:
- level2級中update記錄header節點,所以跨度為0。
- level1級中update記錄的是節點1,跨度為1。
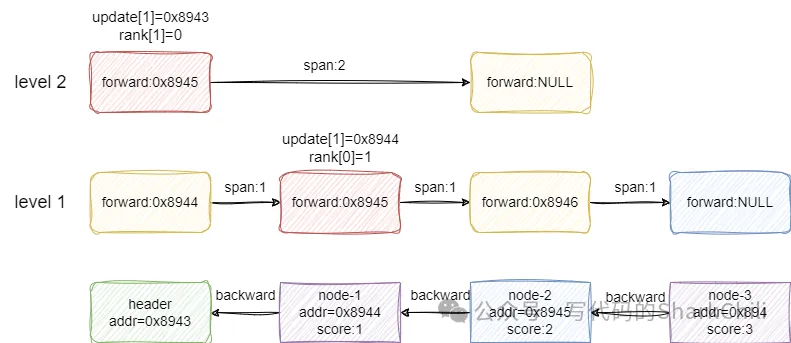
然后基于此信息將x插入:
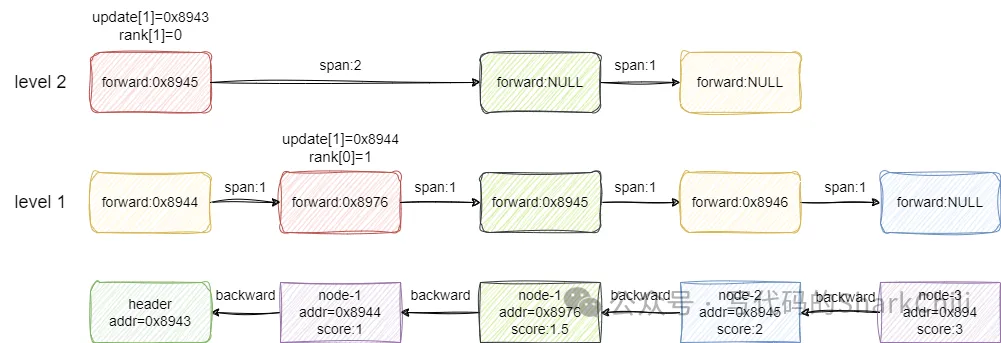
對應的代碼和上述圖解邏輯一致,對應的實現細節筆者都做好了標注:
func zslInsert(zsl *zskiplist, score float64, obj *robj) *zskiplistNode {
//創建一個update數組,記錄插入節點每層索引中小于該score的最大值
update := make([]*zskiplistNode, ZSKIPLIST_MAXLEVEL)
//記錄各層索引走到小于score最大節點的跨區
rank := make([]int64, ZSKIPLIST_MAXLEVEL)
//x指向跳表走節點
x := zsl.header
var i int
//從跳表當前最高層索引開始,查找每層小于當前score的節點的最大值節點
for i = zsl.level - 1; i >= 0; i-- {
//如果當前索引是最高層索引,那么rank從0開始算
if i == zsl.level-1 {
rank[i] = 0
} else { //反之本層索引直接從上一層的跨度開始往后查找
rank[i] = rank[i+1]
}
/**
如果前驅節點不為空,且符合以下條件,則指針前移:
1. 節點小于當前插入節點的score
2. 節點score一致,且元素值小于或者等于當前score
*/
if x.level[i].forward != nil &&
(x.level[i].forward.score < score || (x.level[i].forward.score == score && x.level[i].forward.obj.String() < obj.String())) {
//記錄本層索引前移跨度
rank[i] += x.level[i].span
//索引指針先前移動
x = x.level[i].forward
}
//記錄本層小于當前score的最大節點
update[i] = x
}
//隨機生成新插入節點的索引高度
level := zslRandomLevel()
/**
如果大于當前索引高度,則進行初始化,將這些高層索引的update數組都指向header節點,跨度設置為跳表中的元素數
意為這些高層索引小于插入節點的最大值就是header
*/
if level > zsl.level {
for i := zsl.level; i < level; i++ {
rank[i] = 0
update[i] = zsl.header
update[i].level[i].span = zsl.length
}
//更新一下跳表索引的高度
zsl.level = level
}
//基于入參生成一個節點
x = zslCreateNode(level, score, obj)
//從底層到當前最高層索引處理節點關系
for i = 0; i < level; i++ {
//將小于當前節點的最大節點的forward指向插入節點x,同時x指向這個節點的前向節點
x.level[i].forward = update[i].level[i].forward
update[i].level[i].forward = x
//維護x和update所指向節點之間的跨度信息
x.level[i].span = update[i].level[i].span - (rank[0] - rank[i])
update[i].level[i].span = rank[0] - rank[i] + 1
}
/**
考慮到當前插入節點生成的level小于當前跳表最高level的情況
該邏輯會將這些區間的update索引中的元素到其前方節點的跨度+1,即代表這些層級索引雖然沒有指向x節點,
但因為x節點插入的緣故跨度要加1
*/
for i = level; i < zsl.level; i++ {
update[i].level[i].span++
}
//如果1級索引是header,則x后繼節點不指向該節點,反之指向
if update[0] == zsl.header {
x.backward = nil
} else {
x.backward = update[0]
}
//如果x前向節點不為空,則讓前向節點指向x
if x.level[0].forward != nil {
x.level[0].forward.backward = x
} else {//反之說明x是尾節點,tail指針指向它
zsl.tail = x
}
//維護跳表長度信息
zsl.length++
return x
}跳表查詢操作
有了插入操作的基礎后,查詢操作實現也比較容易了,即從頭節點的最高索引開始不斷向前找,如果沒有則往下一級索引前向找,找到后返回經過的跨度即可。
如下圖,我們希望查找元素2,直接從頭節點的2級索引開始看,就是元素2比對一致,返回跨度2,即跨2步就能到達:
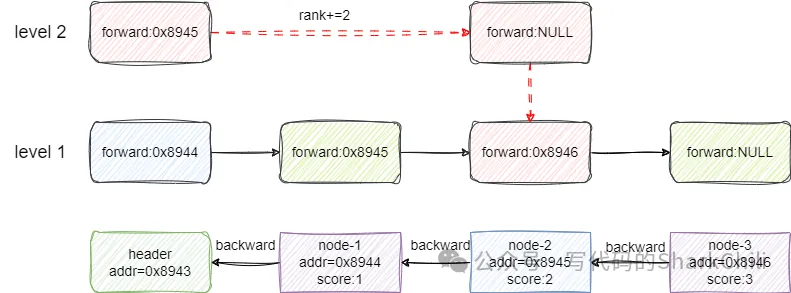
對應代碼如下,和筆者說明一致,這里筆者也做了詳盡的標注提供參考:
func zslGetRank(zsl *zskiplist, score float64, obj *robj) int64 {
var rank int64
//從索引最高節點開始進行查找
x := zsl.header
for i := zsl.level - 1; i >= 0; i-- {
//如果前向節點不為空且score小于查找節點,或者score相等,但是元素字符序比值小于或者等于則前移,同時用rank記錄跨度
for x.level[i].forward != nil &&
(x.level[i].forward.score < score || (x.level[i].forward.score == score && x.level[i].forward.obj.String() <= obj.String())) {
rank += x.level[i].span
x = x.level[i].forward
}
//上述循環結束,比對一直,則返回經過的跨度
if x.obj != nil && x.obj.String() == obj.String() {
return rank
}
}
return 0
}跳表刪除操作
刪除操作本質上也是找到要刪除節點索引的前后節點,然后將這些節點關聯,并修改其之間跨度,如下圖我們要刪除1.5節點,對應各層查找結果為:
- 3級索引找到頭節點,因為前方不是1.5的節點索引,直接跨度減1即。
- 2級索引找到頭節點,前方就是1.5的索引,刪除掉后跨度改為header索引到1.5+1.5到前向節點跨度減去1,這里的減去1代表刪除了節點1.5的跨步。
- 1級索引同2級索引,不多做贅述。
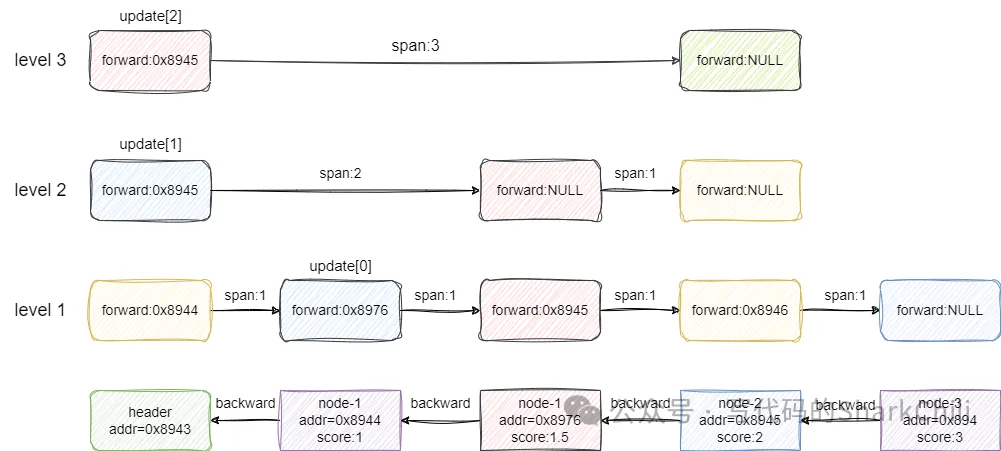
對應的代碼示例如下,整體邏輯和筆者描述基本一致,先通過update找到刪除節點x的前一個元素,然后調用zslDeleteNode進行刪除:
func zslDelete(zsl *zskiplist, score float64, obj *robj) int64 {
update := make([]*zskiplistNode, ZSKIPLIST_MAXLEVEL)
//找到每層索引要刪除節點的前一個節點
x := zsl.header
for i := zsl.level - 1; i >= 0; i-- {
for x.level[i].forward != nil &&
(x.level[i].forward.score < score || (x.level[i].forward.score == score && x.level[i].forward.obj.String() < obj.String())) {
x = x.level[i].forward
}
update[i] = x
}
//查看1級索引前面是否就是要刪除的節點,如果是則直接調用zslDeleteNode刪除節點,并斷掉前后節點關系
x = x.level[0].forward
if x != nil && x.obj.String() == obj.String() {
zslDeleteNode(zsl, x, update)
return 1
}
return 0
}對應zslDeleteNode細節就如筆者上圖所講解的步驟,讀者可參考注釋進行閱讀:
func zslDeleteNode(zsl *zskiplist, x *zskiplistNode, update []*zskiplistNode) {
var i int
for i = 0; i < zsl.level; i++ {
/*
如果索引前方就是刪除節點,當前節點span為:
當前節點到x +x到x前向節點 -1
*/
if update[i].level[i].forward == x {
update[i].level[i].span += x.level[i].span - 1
update[i].level[i].forward = x.level[i].forward
} else {
//反之說明該節點前方不是x的索引,直接減去x的跨步1即
update[i].level[i].span -= 1
}
}
//維護刪除后的節點前后關系
if x.level[0].forward != nil {
x.level[0].forward.backward = x.backward
} else {
zsl.tail = x.backward
}
//將全空層的索引刪除
for zsl.level > 1 && zsl.header.level[zsl.level-1].forward == nil {
zsl.level--
}
//維護跳表節點信息
zsl.length--小結
通過本文的詳細講解,我們從零開始使用 Go 語言實現了一個類似于 Redis 的跳表。我們首先介紹了跳表的基本原理和設計思路,然后逐步實現了跳表的各種核心操作,包括插入、查找和刪除。最后,我們對跳表的性能進行了分析,并探討了其在 Redis 有序集合和其他場景中的應用。




















