













聊聊 Redis 中的字典設計與實現
Redis作為非關系數據庫,其底層采用了字典(也稱為映射)保存鍵值對。本文會基于源碼分析的方式帶你了解redis中這一常見數據結構的精巧設計,希望對你有幫助。

哈希表的基本數據結構
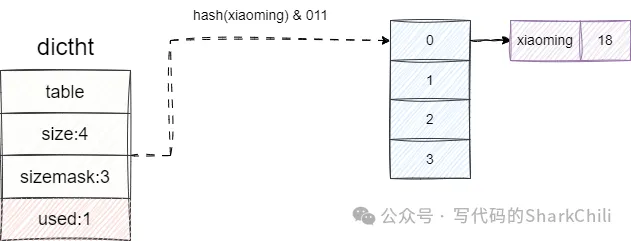
字典用table管理當前存儲鍵值對的數組,這個數組的大小可有size這個字段知曉,每當我們有一個鍵值對要存儲到字典時就會通過sizemask進行按位與運算得到table數組的某個索引位置將當前鍵值對存儲,然后自增一個used標識當前有一個節點加入。
可能上文說的比較抽象,我們不妨舉個例子,假設我們現在鍵入如下指令:
HSET student xiaoming 18redis完成命令解析后,定位到student這個key對應的字段空間的字典,找到當前正在使用的哈希表,按照如下步驟完成鍵值對存儲:
- 計算xiaoming的哈希值。
- 將計算出的哈希值和sizemask即3,也就是數組的索引范圍進行按位與運算,得到對應的數組索引位置。
- 查看該位置是否有元素,如果沒有則直接添加,反之追加到該dictEntry的后面,這也就是我們常說的鏈地址法。
- used字段自增一下,表示當前哈希表有一個元素。
我們可以在dict.h看到上文所提及的哈希表和字典中每一個元素的數據結構:
typedef struct dictht {
//存儲鍵值對的哈希表
dictEntry **table;
//當前哈希表的大小
unsigned long size;
//計算哈希值的掩碼值
unsigned long sizemask;
//當前哈希表的節點數
unsigned long used;
} dictht;
//記錄鍵值對的數據結構dictEntry
typedef struct dictEntry {
//指向鍵的指針
void *key;
//通過共用體存儲值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
//next指針指向下一個dictEntry
struct dictEntry *next;
} dictEntry;字典的數據結構
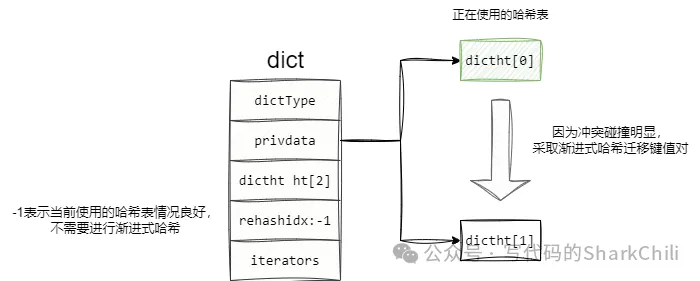
哈希表在極端算法情況下會造成大量鍵值對沖突碰撞的情況,導致查詢效率由原來的O(1)變為O(n),所以為了保證針對沖突的數組進行優化,redis的字典采用的雙數組的方式管理鍵值對。
如下圖所示,可以看到dict的數據結構定義了大小為2的哈希表數組,當某個哈希表碰撞激烈需要進行調整時,就會采用漸進式哈希算法將鍵值對存到dictht[1],并通過rehashidx標志為-1表示當前處于漸進式哈希階段:
對應的我們也可以在dict.h看到dict 的定義:
typedef struct dict {
//.......
//定義2個哈希表
dictht ht[2];
//-1時表示當前哈希表處于漸進式哈希
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
//.......
} dict;字典的創建
進行鍵值對創建時,dictCreate會進行必要的內存分配,然后進入初始化工作:
- 初始化兩個哈希表空間。
- 設置類型特定函數type ,這個type 包含了各種類型哈希值計算、值復制以及鍵比對等各種方法的指針。
- 設置私有數據privdata 。
- 初始化rehashidx 為-1表示未進行漸進式再哈希。
對應的我們可以在dict.c中看到這段源代碼:
/* Create a new hash table */
dict *dictCreate(dictType *type,
void *privDataPtr)
{
//內存分配
dict *d = zmalloc(sizeof(*d));
//字典初始化
_dictInit(d,type,privDataPtr);
return d;
}
/* Initialize the hash table */
int _dictInit(dict *d, dictType *type,
void *privDataPtr)
{
//重置哈希表
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
//設置類型特定函數和私有數據
d->type = type;
d->privdata = privDataPtr;
//初始化漸進式哈希標識
d->rehashidx = -1;
d->iterators = 0;
return DICT_OK;
}元素的插入
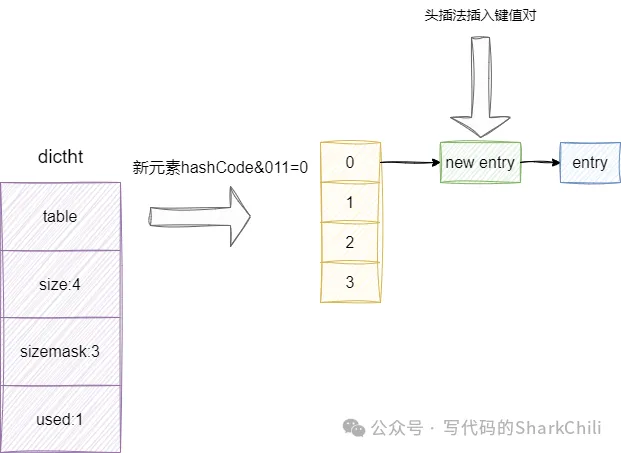
字典的插入操作大體流程也很市面上常見的哈希表實現差不多,通過哈希算法(MurmurHash2)定位元素插入的位置再進行插入操作,唯一有所區別的是,redis版本字典的鏈地址法解決沖突的上的優化,為了保證哈希定位的位置存在元素時能夠快速插入,redis字典的插入采用的是頭插法,即將最新的元素作為鏈表頭元素插入:
與之對應的我們給出代碼的入口,也就是dict.c下的dictAdd方法,可以看到其內部是通過完成鍵的添加,只有key插入成功后才會通過setVal方法維護插入的entry的值:
int dictAdd(dict *d, void *key, void *val)
{
//通過dictAddRaw完成key的插入
dictEntry *entry = dictAddRaw(d,key);
//如果插入成功再維護value
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}dictAddRaw邏輯也比較簡單,先檢查當前的字典表是否因為大量沖突而處理漸進式哈希(關于漸進式哈希后文會詳細講解,這里也補充一些簡單的概念),通過_dictKeyIndex定位到當前元素插入的索引位置,采用頭插法將其插入到對應索引位置的鏈表首部:
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
//是否處于漸進式哈希階段
if (dictIsRehashing(d)) _dictRehashStep(d);
//定位索引位置
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
//定位要存儲元素的哈希表位置
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
//分配內存空間
entry = zmalloc(sizeof(*entry));
//采用頭插法將元素插入到對應哈希表的索引位置上
entry->next = ht->table[index];
ht->table[index] = entry;
//當前插入元素數加一
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}哈希沖突及其對應解決方案(漸進式哈希驅逐)
隨著我們不斷的新增鍵值對,當前的哈希算法得到的索引位置很大概率會出現哈希沖突,即每次定位到的索引位置都很大概率存在元素,這也就是我們的常說的哈希沖突,這就是redis的字典默認會初始化兩張哈希表的原因所在。
符合以下兩個條件時,字典就會觸發擴容機制:
- 未進行BGSAVE命令或者BGREWRITEAOF持久化操作,且當前哈希表元素數和哈希表空間大小一樣。
- 正進行BGSAVE命令或者BGREWRITEAOF持久化操作,當且哈希表元素數是哈希表空間的5倍。
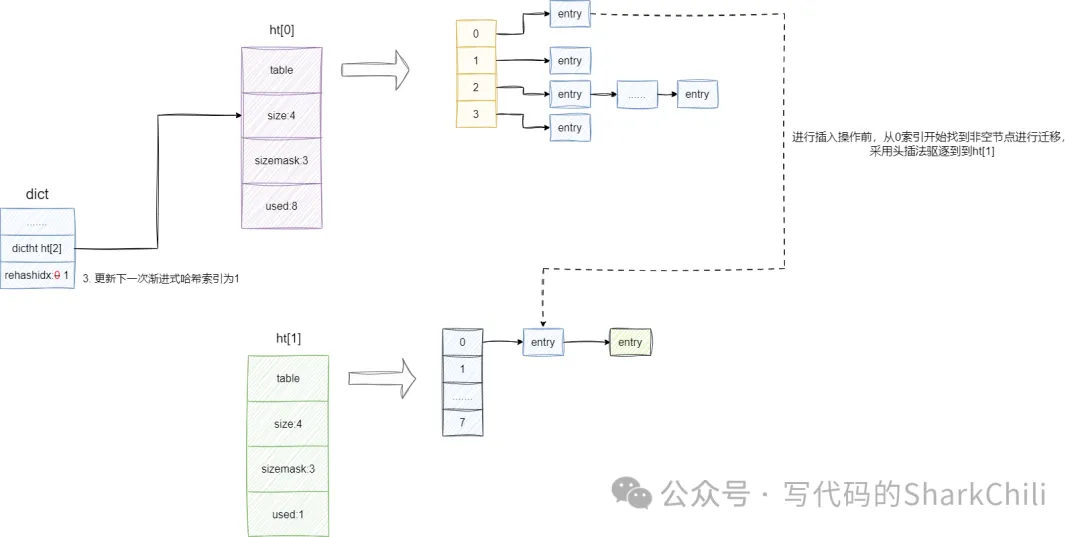
觸發擴容時,字典會將rehashidx設置為0意為當前因為大量沖突碰撞而從0索引開始漸進式再哈希,ht[1]就會開辟一個ht[0]數組長度2倍的數組空間,后續的新插入的元素也都會根據哈希算法將元素插入到ht[1]中。
對于舊有存在的元素,考慮到整個哈希表可能存在不可預估數量的鍵值對,redis的字典會通過漸進式哈希的方式在元素每次進行增刪改查操作時將舊有元素遷移到ht[1]中,一旦所有元素全部遷移到ht[1]后,哈希表就會將ht[1]指向的哈希表指針賦值給ht[0],并將ht[0]原有哈希表釋放。
了解整體的設計之后,我們就可以從源碼角度印證這個問題了,可以看到字典在每次進行哈希索引定位時都會調用_dictKeyIndex方法,而該方法內部則有一個_dictExpandIfNeeded操作,其內部就會根據我們上文所說的閾值判斷當前哈希表是否需要進行擴容:
static int _dictKeyIndex(dict *d, const void *key)
{
unsigned int h, idx, table;
dictEntry *he;
//判斷當前哈希表是否需要進行擴容操作
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
//獲取當前key的哈希值
h = dictHashKey(d, key);
//計算哈希值
for (table = 0; table <= 1; table++) {
//計算索引
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
if (dictCompareKeys(d, key, he->key))
return -1;
he = he->next;
}
//如果不處于漸進式哈希階段,則直接將該索引值返回,后續元素直接存入ht[0]表中,反之進入下一個循環計算當前元素在ht[1]表的索引
if (!dictIsRehashing(d)) break;
}
return idx;
}我們繼續步入_dictExpandIfNeeded即可看到擴容判斷的邏輯,也就是我們上文所說的符合兩個擴容條件之一時就會觸發擴容:
static int _dictExpandIfNeeded(dict *d)
{
//如果正處于漸進式哈希則直接返回
if (dictIsRehashing(d)) return DICT_OK;
//......
//如果當前有子進程進行持久化操作則dict_can_resize為false,所以當字典元素數大于等于哈希表大小且未進行持久化,或進行持久化操作且元素數是哈希表的5倍時才會進行擴容操作,dictExpand會將rehashidx設置為0,告知當前哈希表進行擴容需要進行漸進式再哈希
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}此時我們再回看之前的鍵值對插入操作,它會根據dictIsRehashing判斷rehashidx是否為0,從而調用_dictRehashStep進入漸進式哈希操作在鍵值對維護:
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
//如果處于再哈希階段,若符合要求則進行一次ht[0]哈希表元素驅逐操作
if (dictIsRehashing(d)) _dictRehashStep(d);
//保存鍵值對操作
//......
return entry;
}我們直接查看_dictRehashStep內部的實現就可以看到一個dictRehash的方法,它就是漸進式哈希的核心實現,可以看到該方法會從0開始每次驅逐10個元素到ht[1]中:
int dictRehash(dict *d, int n) {
//基于傳入的n得出訪問空bucket的最大次數,默認為1*10=10
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
//基于empty_visits 循環找到第一個非空的bucket
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
//定位到需要驅逐元素的bucket
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
//計算當前元素在ht[1]中的位置并驅逐過去
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
//計算當前元素在新哈希表的索引位置
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
//基于頭插法,將舊元素指向新哈希表的第一個元素,構成鏈表
de->next = d->ht[1].table[h];
//節點空間指向舊元素
d->ht[1].table[h] = de;
//舊有哈希表元素數減去1
d->ht[0].used--;
//新的哈希值元素空間加上1
d->ht[1].used++;
//進行下一輪迭代
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
//used 為0說明所有元素驅逐完成,將ht[1]指向的哈希表賦值給ht[0],重置rehashidx ,并返回0
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}查詢操作
有了上述的基礎后,我們查看查詢操作就比較簡單了,其步驟比較固定:
- 計算key的哈希值。
- 計算對應索引位置到ht[0]定位,如果找到了直接返回。
- 如果沒找到,查看當前是否處于擴容階段,若是則到ht[1]進行哈希定位,若找到直接返回。
- 上述操作都未找到該元素,直接返回null。
dictEntry *dictFind(dict *d, const void *key)
{
//......
//計算哈希值
h = dictHashKey(d, key);
//通過哈希算法定位索引,到哈希表進行查詢
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
//遍歷當前索引位置的元素,找到比對一致的返回
while(he) {
if (dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
//上一步沒找到則判斷是否處于擴容,若處于擴容則進入下一個循環到ht[1]表找,反之直接返回null
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}刪除操作
同理我們最后給出刪除操作的源碼,也查詢操作一樣,定位到元素后,將其從索引位置中解除該元素和前驅節點關系即可:
static int dictGenericDelete(dict *d, const void *key, int nofree)
{
//......
//定位元素
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
prevHe = NULL;
while(he) {
//找到比對一致的鍵值對
if (dictCompareKeys(d, key, he->key)) {
//解除該元素和前驅節點的關系
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next;
//釋放當前節點
if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
}
zfree(he);
//元素數減去1
d->ht[table].used--;
return DICT_OK;
}
prevHe = he;
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return DICT_ERR; /* not found */
}

























